Multi-modal Pose Diffuser: A Multimodal Generative Conditional Pose Prior
作者: Calvin-Khang Ta, Arindam Dutta, Rohit Kundu, Rohit Lal, Hannah Dela Cruz, Dripta S. Raychaudhuri, Amit Roy-Chowdhury
分类: cs.CV
发布日期: 2024-10-18
💡 一句话要点
提出MOPED:一种多模态条件扩散模型,作为SMPL姿态参数的先验,提升人体姿态生成质量。
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人体姿态估计 SMPL模型 扩散模型 多模态学习 姿态先验 条件生成 3D人体建模
📋 核心要点
- 现有方法难以保证SMPL模型生成的人体姿态的真实性和有效性,缺乏鲁棒的人体姿态先验。
- MOPED利用多模态条件扩散模型作为SMPL姿态参数的先验,从而生成更合理的人体姿态。
- 实验表明,MOPED在姿态估计、去噪和补全任务上显著优于现有方法,能捕捉更广泛的合理姿态。
📝 摘要(中文)
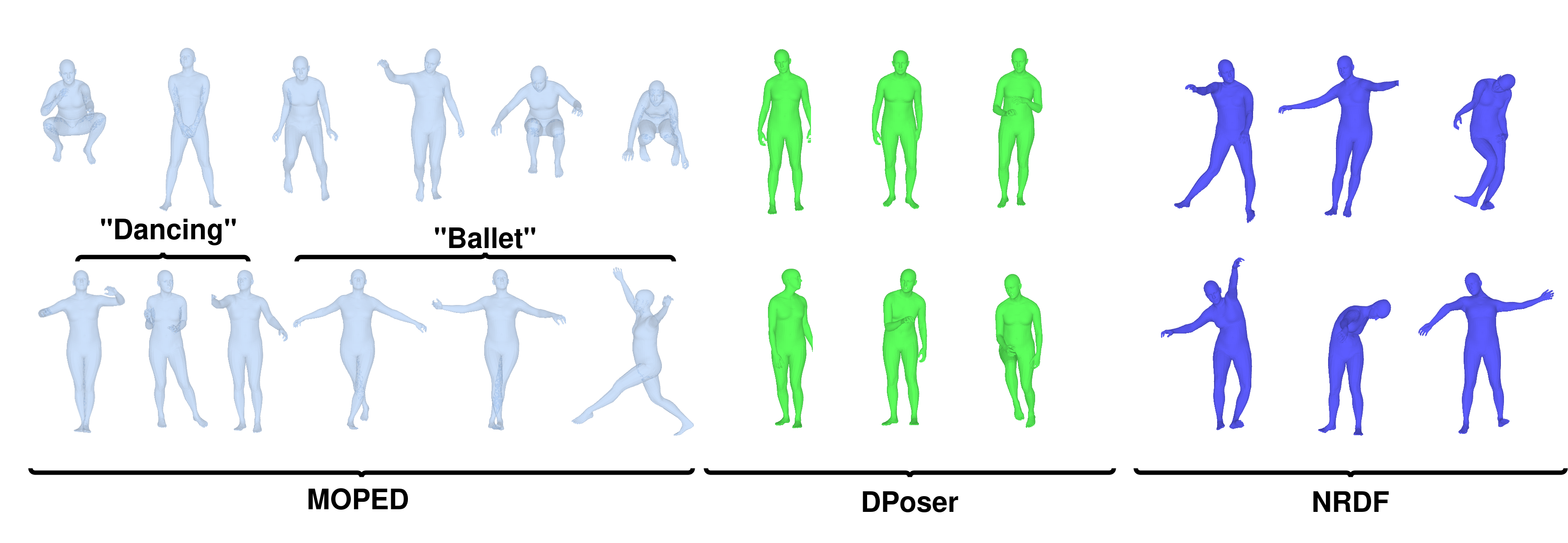
本文提出了一种名为MOPED(多模态姿态扩散器)的新方法,它利用一种新颖的多模态条件扩散模型作为SMPL姿态参数的先验。SMPL模型在3D人体姿态估计中起着关键作用,但保证SMPL配置的有效性仍然是一个挑战。MOPED是第一个利用多模态条件扩散模型作为SMPL姿态参数先验的方法。该方法能够进行强大的无条件姿态生成,并能以图像和文本等多模态输入为条件。通过整合传统姿态先验中经常被忽略的额外上下文信息,增强了方法的适用性。在姿态估计、姿态去噪和姿态补全三个不同任务上的大量实验表明,基于多模态扩散模型的先验显著优于现有方法。这些结果表明,该模型能够捕捉到更广泛的合理人体姿态。
🔬 方法详解
问题定义:论文旨在解决3D人体姿态估计中,如何确保生成的人体姿态(SMPL模型参数)的真实性和合理性的问题。现有方法生成的姿态可能不符合人体生理结构,缺乏有效的姿态先验约束。
核心思路:论文的核心思路是将多模态条件扩散模型作为SMPL姿态参数的先验。扩散模型能够学习复杂的数据分布,而多模态条件则允许模型根据图像、文本等额外信息生成更符合场景的姿态。这样设计的目的是利用扩散模型的生成能力和多模态信息的约束,从而生成更真实、合理的人体姿态。
技术框架:MOPED的整体框架包含以下几个主要部分:首先,使用SMPL模型表示人体姿态。然后,构建一个多模态条件扩散模型,该模型以SMPL姿态参数为目标,以图像或文本等模态信息为条件。扩散模型通过逐步添加噪声,再逐步去噪的方式学习姿态分布。在推理阶段,可以根据给定的条件生成新的姿态。
关键创新:MOPED的关键创新在于将多模态条件扩散模型引入到人体姿态先验的学习中。与传统的姿态先验方法相比,MOPED能够利用图像、文本等多模态信息,从而生成更符合场景的姿态。此外,扩散模型本身具有强大的生成能力,能够捕捉到更复杂、更真实的姿态分布。
关键设计:论文中关于扩散模型的具体参数设置、损失函数以及网络结构等技术细节未详细描述,属于未知信息。但可以推测,损失函数可能包含重建损失和对抗损失,网络结构可能采用U-Net类似的结构。
🖼️ 关键图片


📊 实验亮点
MOPED在姿态估计、姿态去噪和姿态补全三个任务上都取得了显著的性能提升。具体的数据和对比基线在摘要中没有给出,属于未知信息。但论文强调,MOPED能够捕捉到更广泛的合理人体姿态,表明其学习到的姿态先验更加鲁棒和有效。
🎯 应用场景
MOPED在3D人体姿态估计、虚拟现实、游戏、动画制作等领域具有广泛的应用前景。它可以用于生成更逼真的人体动画,提高虚拟角色的交互性,以及辅助人体运动分析和康复训练。该研究的实际价值在于提升了人体姿态估计的准确性和真实性,为相关应用提供了更可靠的基础。
📄 摘要(原文)
The Skinned Multi-Person Linear (SMPL) model plays a crucial role in 3D human pose estimation, providing a streamlined yet effective representation of the human body. However, ensuring the validity of SMPL configurations during tasks such as human mesh regression remains a significant challenge , highlighting the necessity for a robust human pose prior capable of discerning realistic human poses. To address this, we introduce MOPED: \underline{M}ulti-m\underline{O}dal \underline{P}os\underline{E} \underline{D}iffuser. MOPED is the first method to leverage a novel multi-modal conditional diffusion model as a prior for SMPL pose parameters. Our method offers powerful unconditional pose generation with the ability to condition on multi-modal inputs such as images and text. This capability enhances the applicability of our approach by incorporating additional context often overlooked in traditional pose priors. Extensive experiments across three distinct tasks-pose estimation, pose denoising, and pose completion-demonstrate that our multi-modal diffusion model-based prior significantly outperforms existing methods. These results indicate that our model captures a broader spectrum of plausible human poses.