ViCToR: Improving Visual Comprehension via Token Reconstruction for Pretraining LMMs
作者: Yin Xie, Kaicheng Yang, Peirou Liang, Xiang An, Yongle Zhao, Yumeng Wang, Ziyong Feng, Roy Miles, Ismail Elezi, Jiankang Deng
分类: cs.CV
发布日期: 2024-10-18 (更新: 2025-08-13)
备注: 10 pages, 6 figures, 5 tables
🔗 代码/项目: GITHUB
💡 一句话要点
ViCToR:通过视觉Token重建提升LMMs的视觉理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视觉理解 Token重建 大型语言模型 预训练
📋 核心要点
- 现有LMMs的视觉表示对背景噪声敏感,导致视觉理解能力不足。
- ViCToR通过可学习的视觉token池和token重建损失,增强视觉表示的鲁棒性和细节保留。
- 实验表明,ViCToR在多个基准测试中显著优于现有模型,提升视觉理解性能。
📝 摘要(中文)
大型多模态模型(LMMs)在预训练过程中经常面临模态表示差距:语言嵌入保持稳定,而视觉表示对上下文噪声(例如,背景杂乱)高度敏感。为了解决这个问题,我们引入了一个视觉理解阶段,称为ViCToR(Visual Comprehension via Token Reconstruction),这是一种用于LMMs的新的预训练框架。ViCToR采用可学习的视觉token池,并利用匈牙利匹配算法从该池中选择语义相关的token进行视觉token替换。此外,通过将视觉token重建损失与密集语义监督相结合,ViCToR可以学习保留高视觉细节的token,从而增强大型语言模型(LLM)对视觉信息的理解。在300万张公开图像和标题上进行预训练后,ViCToR取得了最先进的结果,在MMStar、SEED$^I$和RealWorldQA基准测试中,分别比LLaVA-NeXT-8B提高了10.4%、3.2%和7.2%。代码可在https://github.com/deepglint/Victor获取。
🔬 方法详解
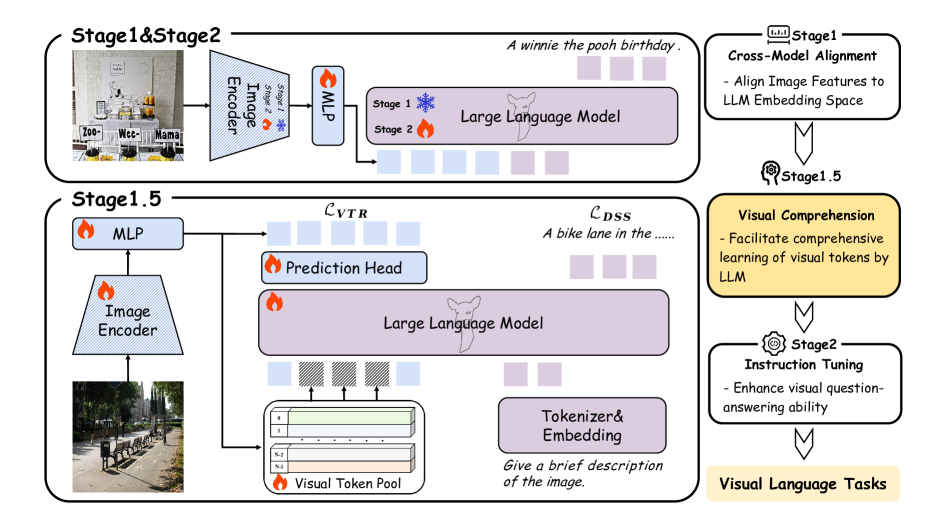
问题定义:LMMs在预训练时,视觉模态的表示容易受到图像背景噪声的影响,导致模型难以准确理解图像内容。现有的方法无法有效地提取和利用图像中的关键视觉信息,从而限制了LMMs的整体性能。
核心思路:ViCToR的核心思路是通过视觉token重建来提高视觉表示的质量。具体来说,它使用一个可学习的视觉token池,并从中选择与图像内容最相关的token来替换原始的视觉token。同时,通过视觉token重建损失,迫使模型学习保留高视觉细节的token,从而增强LMMs对视觉信息的理解。
技术框架:ViCToR的整体框架包括以下几个主要模块:1) 图像编码器:用于提取图像的原始视觉token。2) 可学习的视觉token池:包含一组可学习的视觉token,用于替换原始的视觉token。3) 匈牙利匹配算法:用于从视觉token池中选择与图像内容最相关的token。4) 视觉token重建模块:用于重建原始的视觉token,并计算重建损失。5) 语言模型:用于处理视觉token和文本信息,进行多模态理解和生成。
关键创新:ViCToR的关键创新在于引入了视觉token池和视觉token重建损失。视觉token池允许模型从一组预定义的token中选择最相关的token,从而提高视觉表示的鲁棒性。视觉token重建损失迫使模型学习保留高视觉细节的token,从而增强LMMs对视觉信息的理解。与现有方法相比,ViCToR能够更有效地提取和利用图像中的关键视觉信息。
关键设计:ViCToR的关键设计包括:1) 使用匈牙利匹配算法来选择视觉token,以确保选择的token与图像内容最相关。2) 使用视觉token重建损失和密集语义监督来训练模型,以提高视觉表示的质量。3) 使用300万张公开图像和标题进行预训练,以提高模型的泛化能力。具体的损失函数包括token重建损失和语义对齐损失。网络结构基于现有的LMMs,例如LLaVA-NeXT,并在其基础上添加了视觉token池和重建模块。
🖼️ 关键图片


📊 实验亮点
ViCToR在MMStar、SEED$^I$和RealWorldQA基准测试中取得了显著的性能提升,分别比LLaVA-NeXT-8B提高了10.4%、3.2%和7.2%。这些结果表明,ViCToR能够有效地提高LMMs的视觉理解能力,并在多个实际应用中具有潜力。实验结果证明了视觉token重建策略的有效性。
🎯 应用场景
ViCToR的潜在应用领域包括图像描述生成、视觉问答、机器人导航和自动驾驶等。通过提高LMMs的视觉理解能力,ViCToR可以帮助这些应用更好地理解和利用视觉信息,从而提高其性能和可靠性。未来,ViCToR可以进一步扩展到其他多模态任务,例如视频理解和3D场景理解。
📄 摘要(原文)
Large Multimodal Models (LMMs) often face a modality representation gap during pretraining: while language embeddings remain stable, visual representations are highly sensitive to contextual noise (e.g., background clutter). To address this issue, we introduce a visual comprehension stage, which we call ViCToR (Visual Comprehension via Token Reconstruction), a novel pretraining framework for LMMs. ViCToR employs a learnable visual token pool and utilizes the Hungarian matching algorithm to select semantically relevant tokens from this pool for visual token replacement. Furthermore, by integrating a visual token reconstruction loss with dense semantic supervision, ViCToR can learn tokens which retain high visual detail, thereby enhancing the large language model's (LLM's) understanding of visual information. After pretraining on 3 million publicly accessible images and captions, ViCToR achieves state-of-the-art results, improving over LLaVA-NeXT-8B by 10.4%, 3.2%, and 7.2% on the MMStar, SEED$^I$, and RealWorldQA benchmarks, respectively. Code is available at https://github.com/deepglint/Victor.