ProReason: Multi-Modal Proactive Reasoning with Decoupled Eyesight and Wisdom
作者: Jingqi Zhou, Sheng Wang, Jingwei Dong, Kai Liu, Lei Li, Jiahui Gao, Jiyue Jiang, Lingpeng Kong, Chuan Wu
分类: cs.CV, cs.AI
发布日期: 2024-10-18 (更新: 2025-10-15)
💡 一句话要点
ProReason:解耦视觉感知与文本推理,实现多模态主动推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉推理 多模态学习 主动感知 大型语言模型 知识蒸馏 视觉语言模型 解耦推理
📋 核心要点
- 现有视觉语言模型在视觉推理中过度依赖语言知识,忽略图像信息,导致性能下降。
- ProReason框架将视觉推理分解为主动视觉感知和文本推理两个阶段,解耦视觉和推理能力。
- 实验表明,ProReason在多个基准测试中优于现有方法,平均性能提升13.2%,并能生成高质量的视觉推理数据。
📝 摘要(中文)
大型视觉语言模型(LVLMs)在视觉理解任务中取得了显著进展。然而,在视觉推理任务中,它们常常过度依赖语言知识而忽略图像信息,导致性能下降。为了解决这个问题,我们首先指出了现有解决方案的不足(即,有限的多模态推理能力,以及不足且不相关的视觉描述)。然后,我们将视觉推理过程分解为两个阶段:主动视觉感知(即,视力)和文本推理(即,智慧),并提出了一个名为ProReason的新型视觉推理框架。该框架具有解耦的视觉-推理能力和多轮主动感知。简而言之,给定一个多模态问题,ProReason迭代地进行主动信息收集和推理,直到能够用必要且充分的视觉描述得出答案。值得注意的是,这种能力的分离允许无缝集成现有的大型语言模型(LLMs),以弥补LVLM的推理缺陷。大量的实验表明,ProReason在各种基准测试中优于现有的多步推理框架,开源和闭源模型的平均性能提升达到13.2%。此外,LLM的集成使ProReason能够生成高质量的视觉推理数据,这使得ProReason-distilled模型(即,ProReason-VL和ProReason-Q3)在下游任务中实现了卓越的性能。我们对现有解决方案的见解以及用于可行集成LLM的解耦视角,为视觉推理技术(尤其是LLM辅助的视觉推理技术)的未来研究提供了启示。
🔬 方法详解
问题定义:现有视觉语言模型(LVLMs)在视觉推理任务中表现不佳,主要原因是它们倾向于利用语言知识而非图像信息。现有方法的多模态推理能力有限,且提供的视觉描述不足或不相关,无法有效解决复杂视觉推理问题。
核心思路:ProReason的核心思路是将视觉推理过程解耦为两个独立的阶段:主动视觉感知(眼睛)和文本推理(智慧)。通过这种解耦,模型可以更专注于视觉信息的提取和理解,并利用大型语言模型(LLMs)进行更有效的推理。这种设计允许模型迭代地收集和推理信息,直到获得足够且必要的视觉描述来回答问题。
技术框架:ProReason框架包含以下主要模块:1) 问题编码模块:将多模态问题编码为向量表示。2) 主动视觉感知模块:迭代地从图像中提取相关视觉信息,生成视觉描述。3) 文本推理模块:利用LLM对问题和视觉描述进行推理,生成答案。4) 停止条件判断模块:判断当前视觉描述是否足够回答问题,如果不足够,则返回主动视觉感知模块继续提取信息。整个流程是一个迭代的过程,直到满足停止条件。
关键创新:ProReason的关键创新在于解耦了视觉感知和文本推理能力,并引入了多轮主动感知机制。这种解耦允许模型更有效地利用LLM进行推理,并避免了过度依赖语言知识的问题。多轮主动感知机制使得模型能够逐步提取必要的视觉信息,从而提高推理的准确性。
关键设计:ProReason的关键设计包括:1) 使用预训练的视觉模型(如CLIP)进行视觉特征提取。2) 使用LLM(如GPT-3)进行文本推理。3) 设计了停止条件判断模块,用于控制迭代过程。4) 使用高质量的视觉推理数据进行蒸馏训练,得到ProReason-VL和ProReason-Q3模型。
🖼️ 关键图片

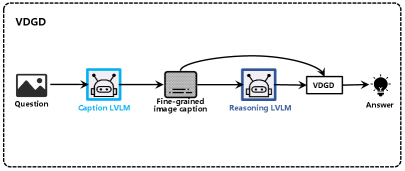
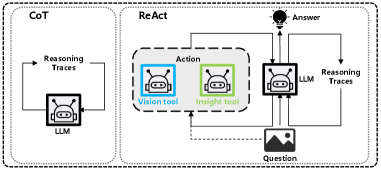
📊 实验亮点
ProReason在多个视觉推理基准测试中取得了显著的性能提升,平均性能提升达到13.2%。通过集成LLM,ProReason能够生成高质量的视觉推理数据,并利用这些数据蒸馏训练出ProReason-VL和ProReason-Q3模型,在下游任务中表现出色。实验结果表明,ProReason框架能够有效解决现有视觉语言模型在视觉推理任务中的问题。
🎯 应用场景
ProReason框架可应用于各种需要复杂视觉推理的场景,例如智能问答、视觉导航、机器人操作等。该研究有助于提升视觉语言模型在实际应用中的性能和可靠性,并为未来LLM辅助的视觉推理技术研究提供了新的方向。
📄 摘要(原文)
Large vision-language models (LVLMs) have witnessed significant progress on visual understanding tasks. However, they often prioritize language knowledge over image information on visual reasoning tasks, incurring performance degradation. To tackle this issue, we first identify the drawbacks of existing solutions (i.e., limited multi-modal reasoning capacities, and insufficient and irrelevant visual descriptions). We then decompose visual reasoning process into two stages: proactive visual perception (i.e., eyesight) and textual reasoning (i.e., wisdom), and introduce a novel visual reasoning framework named ProReason. This framework features decoupled vision-reasoning capabilities and multi-run proactive perception. Briefly, given a multi-modal question, ProReason iterates proactive information collection and reasoning until the answer can be concluded with necessary and sufficient visual descriptions. Notably, the disassociation of capabilities allows seamless integration of existing large language models (LLMs) to compensate for the reasoning deficits of LVLMs. Our extensive experiments demonstrate that ProReason outperforms existing multi-step reasoning frameworks on various benchmarks for both open-source and closed-source models, with the average performance gain reaching 13.2%. Besides, the integration of LLMs allows ProReason to produce high-quality visual reasoning data, which empowers ProReason-distilled models (i.e., ProReason-VL and ProReason-Q3) to achieve superior performance in downstream tasks. Our insights into existing solutions and the decoupled perspective for feasible integration of LLMs illuminate future research on visual reasoning techniques, especially LLM-assisted ones.