RAP: Retrieval-Augmented Personalization for Multimodal Large Language Models
作者: Haoran Hao, Jiaming Han, Changsheng Li, Yu-Feng Li, Xiangyu Yue
分类: cs.CV, cs.AI, cs.CL, cs.LG, cs.MM
发布日期: 2024-10-17 (更新: 2025-03-28)
备注: Accepted by CVPR 2025. Code: https://github.com/Hoar012/RAP-MLLM
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
RAP:检索增强的个性化多模态大语言模型框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 个性化 检索增强 知识库 视觉识别
📋 核心要点
- 现有MLLM缺乏用户特定知识,限制了其在日常生活中的应用,难以提供个性化服务。
- RAP框架通过构建用户知识库、多模态检索和个性化生成三个步骤,增强MLLM的个性化能力。
- RAP-MLLM通过预训练泛化到无限视觉概念,并在个性化图像描述、问答和视觉识别等任务中表现出色。
📝 摘要(中文)
本文提出了一种用于多模态大语言模型(MLLM)个性化的检索增强个性化(RAP)框架。该框架将通用MLLM转化为个性化助手,包含三个步骤:(a)记忆:设计一个键值数据库来存储用户相关信息,例如用户的姓名、头像和其他属性。(b)检索:当用户发起对话时,RAP将使用多模态检索器从数据库中检索相关信息。(c)生成:将输入查询和检索到的概念信息输入到MLLM中,以生成个性化的、知识增强的响应。与以往方法不同,RAP允许通过更新外部数据库进行实时概念编辑。为了进一步提高生成质量和与用户特定信息的一致性,我们设计了一个数据收集流程,并创建了一个专门的数据集用于MLLM的个性化训练。基于该数据集,我们训练了一系列MLLM作为个性化多模态助手。通过在大规模数据集上进行预训练,RAP-MLLM可以推广到无限的视觉概念,而无需额外的微调。我们的模型在各种任务中表现出出色的灵活性和生成质量,例如个性化图像描述、问答和视觉识别。代码、数据和模型可在https://hoar012.github.io/RAP-Project/上找到。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)和多模态大型语言模型(MLLM)虽然在通用任务上表现出色,但在处理需要用户特定知识的任务时存在局限性。它们无法记住用户的偏好、历史记录和个人信息,导致无法提供真正个性化的服务。现有的个性化方法通常需要针对每个用户进行微调,成本高昂且难以扩展。
核心思路:RAP的核心思路是通过检索增强的方式,将用户的个性化信息存储在外部数据库中,并在生成响应时动态地检索相关信息。这样,MLLM就可以在不进行微调的情况下,利用外部知识来生成个性化的回复。这种方法的优势在于可以实时更新用户知识,并且可以泛化到新的用户和任务。
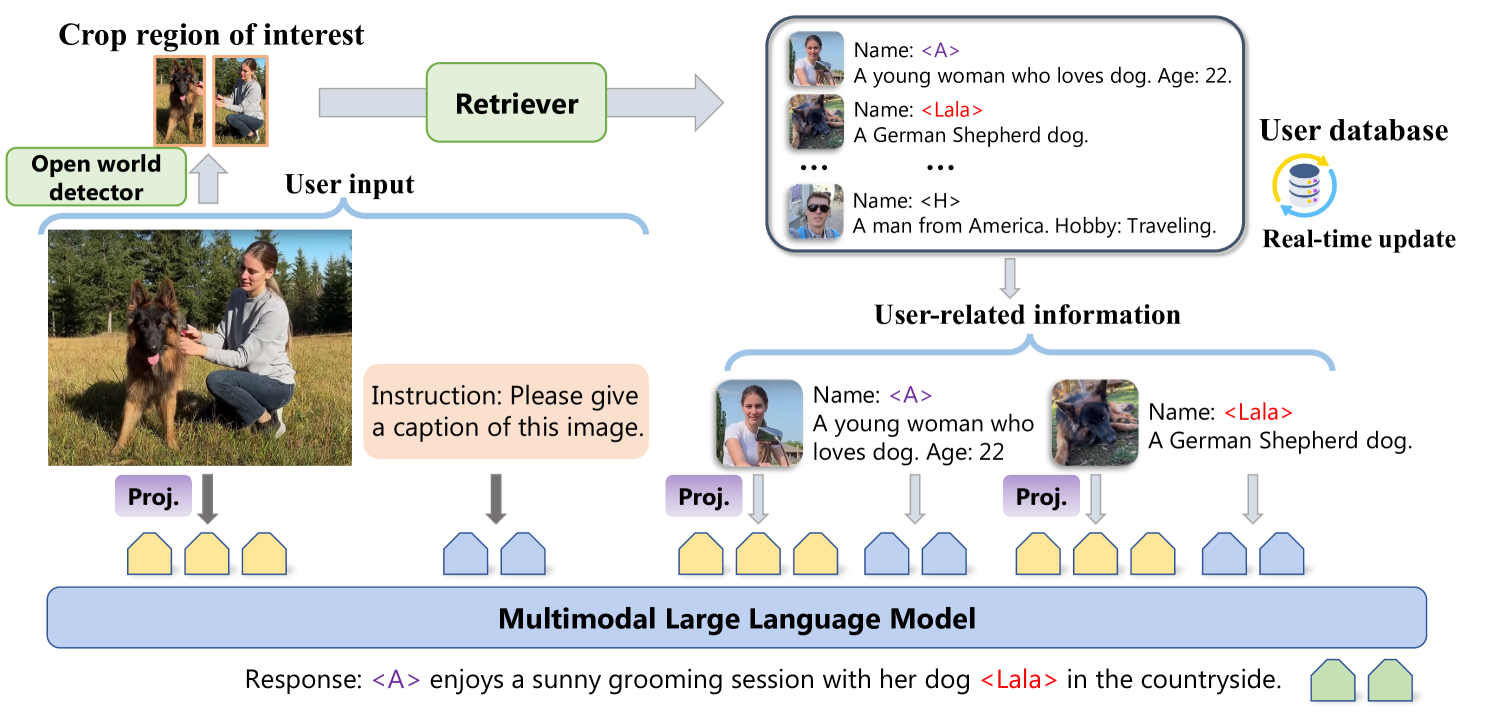
技术框架:RAP框架包含三个主要模块:记忆(Remember)、检索(Retrieve)和生成(Generate)。记忆模块负责构建和维护用户相关的键值数据库,其中键可以是用户的属性或视觉概念,值是相应的描述或信息。检索模块使用多模态检索器,根据用户的输入查询从数据库中检索相关信息。生成模块将用户的输入查询和检索到的信息输入到MLLM中,生成个性化的响应。
关键创新:RAP的关键创新在于将检索增强与MLLM的个性化相结合,提出了一种无需微调即可实现个性化的方法。此外,RAP还允许实时更新用户知识,并可以泛化到新的视觉概念。通过专门的数据集和训练流程,RAP-MLLM能够更好地对齐用户特定信息,提高生成质量。
关键设计:RAP使用键值数据库存储用户相关信息,键可以是文本或图像。多模态检索器可以使用预训练的CLIP模型或其他相似度度量方法。生成模块可以使用各种MLLM,例如LLaVA或InstructBLIP。为了训练RAP-MLLM,作者设计了一个数据收集流程,并创建了一个专门的数据集,其中包含用户特定信息和相应的问答对。训练目标是使MLLM能够根据用户输入和检索到的信息生成个性化的响应。
🖼️ 关键图片


📊 实验亮点
RAP-MLLM在个性化图像描述、问答和视觉识别等任务中表现出出色的性能。实验结果表明,RAP-MLLM能够生成更准确、更个性化的响应,并且可以泛化到新的视觉概念,而无需额外的微调。与传统的微调方法相比,RAP具有更高的效率和灵活性。
🎯 应用场景
RAP框架可应用于各种需要个性化服务的场景,例如个性化推荐系统、智能客服、虚拟助手和教育辅导。通过记住用户的偏好和历史记录,RAP可以提供更贴合用户需求的建议和服务,提高用户满意度和参与度。该研究为构建更智能、更人性化的AI系统奠定了基础。
📄 摘要(原文)
The development of large language models (LLMs) has significantly enhanced the capabilities of multimodal LLMs (MLLMs) as general assistants. However, lack of user-specific knowledge still restricts their application in human's daily life. In this paper, we introduce the Retrieval Augmented Personalization (RAP) framework for MLLMs' personalization. Starting from a general MLLM, we turn it into a personalized assistant in three steps. (a) Remember: We design a key-value database to store user-related information, e.g., user's name, avatar and other attributes. (b) Retrieve: When the user initiates a conversation, RAP will retrieve relevant information from the database using a multimodal retriever. (c) Generate: The input query and retrieved concepts' information are fed into MLLMs to generate personalized, knowledge-augmented responses. Unlike previous methods, RAP allows real-time concept editing via updating the external database. To further improve generation quality and alignment with user-specific information, we design a pipeline for data collection and create a specialized dataset for personalized training of MLLMs. Based on the dataset, we train a series of MLLMs as personalized multimodal assistants. By pretraining on large-scale dataset, RAP-MLLMs can generalize to infinite visual concepts without additional finetuning. Our models demonstrate outstanding flexibility and generation quality across a variety of tasks, such as personalized image captioning, question answering and visual recognition. The code, data and models are available at https://hoar012.github.io/RAP-Project/.