Few-shot Novel View Synthesis using Depth Aware 3D Gaussian Splatting
作者: Raja Kumar, Vanshika Vats
分类: cs.CV, cs.AI, cs.GR
发布日期: 2024-10-14
备注: Presented in ECCV 2024 workshop S3DSGR
🔗 代码/项目: GITHUB
💡 一句话要点
提出深度感知3D高斯溅射,解决少样本新视角合成中性能下降问题。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 新视角合成 3D高斯溅射 少样本学习 深度预测 单目视觉
📋 核心要点
- 3D高斯溅射在视图合成中表现出色,但在少量视图下性能显著下降,难以保证高质量渲染。
- 利用单目深度预测作为先验知识,结合深度损失约束3D形状,并保留所有splat以避免点云稀疏。
- 实验表明,该方法在PSNR、SSIM和LPIPS指标上均优于传统3D高斯溅射方法,提升显著。
📝 摘要(中文)
3D高斯溅射在计算成本和高质量实时渲染方面超越了神经辐射场方法,成为新视角合成的有力工具。然而,在少量输入视图的情况下,其性能会显著下降。本文提出了一种深度感知的3D高斯溅射方法,用于少样本新视角合成。该方法利用单目深度预测作为先验,并结合尺度不变的深度损失,以约束少量输入视图下的3D形状。同时,使用低阶球谐函数对颜色进行建模,以避免过拟合。此外,观察到原始方法中定期移除低透明度splat会导致点云过于稀疏,从而降低渲染质量。为了缓解这个问题,本文保留了所有的splat,从而在少视图设置下实现了更好的重建。实验结果表明,该方法在峰值信噪比方面提高了10.5%,在结构相似性指数方面提高了6%,在感知相似性方面提高了14.1%,验证了该方法的有效性。
🔬 方法详解
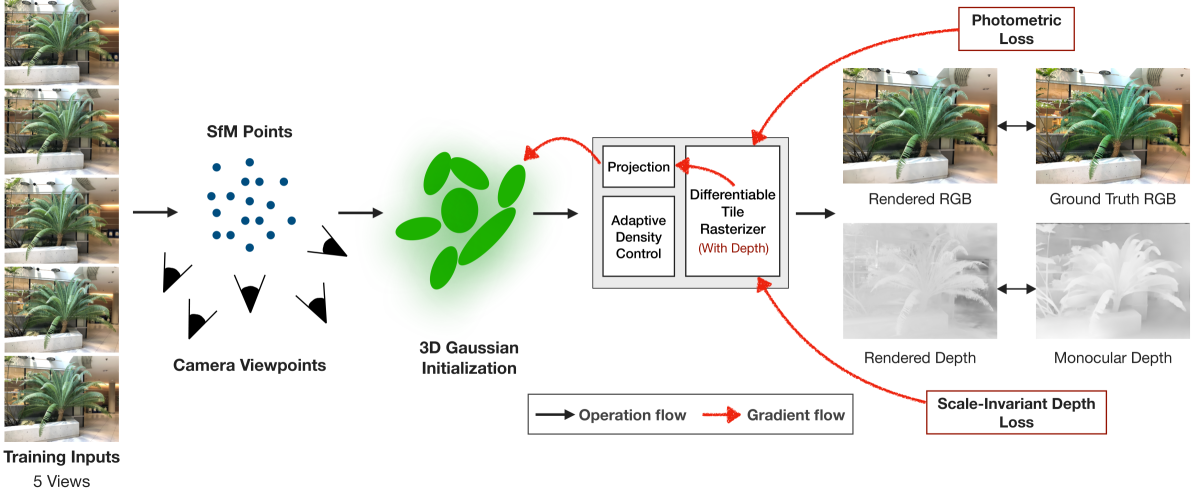
问题定义:在少样本新视角合成任务中,现有的3D高斯溅射方法由于缺乏足够的视图信息,难以准确地重建场景的3D结构和外观,导致合成的新视角图像质量下降。原始方法中splat的定期移除进一步加剧了点云的稀疏性,使得重建质量雪上加霜。
核心思路:论文的核心思路是利用单目深度预测作为先验知识,辅助3D高斯溅射进行场景重建。通过引入深度信息,可以有效地约束3D形状,即使在少量视图的情况下也能生成较为准确的几何结构。同时,保留所有splat,避免点云过于稀疏,从而提升渲染质量。
技术框架:该方法主要包含以下几个模块:1) 单目深度预测模块,用于从输入图像中估计深度图;2) 深度损失计算模块,用于约束3D高斯溅射的形状;3) 3D高斯溅射优化模块,用于优化高斯参数,包括位置、协方差、颜色和透明度等;4) 渲染模块,用于将3D高斯溅射渲染成新视角图像。整个流程是:首先利用单目深度预测得到深度图,然后将其作为先验信息,在3D高斯溅射优化过程中,通过深度损失约束高斯参数,最后渲染得到新视角图像。
关键创新:该方法最重要的技术创新点在于将单目深度预测与3D高斯溅射相结合,利用深度信息作为先验知识,有效地解决了少样本新视角合成问题。与传统的3D高斯溅射方法相比,该方法能够更好地约束3D形状,避免过拟合,从而在少量视图的情况下也能生成高质量的新视角图像。
关键设计:论文使用了尺度不变的深度损失函数,以保证深度预测的尺度一致性。同时,为了避免颜色过拟合,使用了低阶球谐函数对颜色进行建模。此外,与原始3D高斯溅射方法不同,该方法保留了所有的splat,避免了点云的稀疏性。具体的损失函数包括深度损失、光度损失和正则化损失等。网络结构方面,单目深度预测模块可以使用现有的深度估计网络,如DPT等。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在少样本新视角合成任务中取得了显著的性能提升。在峰值信噪比(PSNR)方面,该方法比传统3D高斯溅射方法提高了10.5%;在结构相似性指数(SSIM)方面,提高了6%;在感知相似性(LPIPS)方面,提高了14.1%。这些数据充分验证了该方法的有效性。
🎯 应用场景
该研究成果可应用于虚拟现实、增强现实、机器人导航、自动驾驶等领域。在这些应用中,通常需要在少量图像或视频帧的情况下,快速准确地重建场景的3D结构和外观,并生成新视角的图像。该方法能够有效地解决这个问题,提高用户体验和系统性能,具有重要的实际应用价值。
📄 摘要(原文)
3D Gaussian splatting has surpassed neural radiance field methods in novel view synthesis by achieving lower computational costs and real-time high-quality rendering. Although it produces a high-quality rendering with a lot of input views, its performance drops significantly when only a few views are available. In this work, we address this by proposing a depth-aware Gaussian splatting method for few-shot novel view synthesis. We use monocular depth prediction as a prior, along with a scale-invariant depth loss, to constrain the 3D shape under just a few input views. We also model color using lower-order spherical harmonics to avoid overfitting. Further, we observe that removing splats with lower opacity periodically, as performed in the original work, leads to a very sparse point cloud and, hence, a lower-quality rendering. To mitigate this, we retain all the splats, leading to a better reconstruction in a few view settings. Experimental results show that our method outperforms the traditional 3D Gaussian splatting methods by achieving improvements of 10.5% in peak signal-to-noise ratio, 6% in structural similarity index, and 14.1% in perceptual similarity, thereby validating the effectiveness of our approach. The code will be made available at: https://github.com/raja-kumar/depth-aware-3DGS