ExpGest: Expressive Speaker Generation Using Diffusion Model and Hybrid Audio-Text Guidance
作者: Yongkang Cheng, Mingjiang Liang, Shaoli Huang, Jifeng Ning, Wei Liu
分类: cs.SD, cs.CV, eess.AS
发布日期: 2024-10-12
备注: Accepted by ICME 2024
DOI: 10.1109/ICME57554.2024.10687922
💡 一句话要点
ExpGest:提出一种基于扩散模型和混合音文引导的富有表现力的说话人姿态生成框架
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱四:生成式动作 (Generative Motion)
关键词: 姿态生成 扩散模型 音频文本引导 情感表达 全身运动 人机交互
📋 核心要点
- 现有姿态生成方法忽略语音内容和情感,导致生成的姿态僵硬且缺乏表现力,难以准确传达音频信息。
- ExpGest利用扩散模型,结合同步文本和音频信息,生成更具表现力的全身姿态,并引入噪声情感分类器优化情感表达。
- 实验结果表明,ExpGest能有效学习混合数据集,生成更自然、可控的说话人姿态,优于现有技术水平。
📝 摘要(中文)
现有的姿态生成方法主要关注基于音频特征的上半身姿态,忽略了语音内容、情感和运动。这些局限性导致姿态僵硬、机械,无法传达音频内容的真正含义。我们提出了ExpGest,一种利用同步文本和音频信息来生成富有表现力的全身姿态的新框架。与AdaIN或one-hot编码方法不同,我们设计了一个噪声情感分类器,用于优化对抗方向噪声,避免旋律失真,并将结果引导到指定的情感。此外,在潜在空间中对齐语义和姿态提供了更好的泛化能力。ExpGest是一个基于扩散模型的姿态生成框架,首次尝试提供混合生成模式,包括音频驱动的姿态和文本塑造的运动。实验表明,我们的框架有效地从组合的文本驱动运动和音频诱导姿态数据集中学习,初步结果表明,与最先进的模型相比,ExpGest在说话人中实现了更富有表现力、自然和可控的全局运动。
🔬 方法详解
问题定义:现有姿态生成方法主要依赖音频信息生成上半身姿态,忽略了语音内容、情感以及全身运动的连贯性,导致生成的姿态缺乏表现力,无法准确反映说话人的意图和情感。这些方法生成的姿态通常显得僵硬和机械,难以应用于需要自然交互的场景。
核心思路:ExpGest的核心思路是利用扩散模型强大的生成能力,并结合同步的文本和音频信息,从而生成更富有表现力的全身姿态。通过文本信息来指导姿态的语义内容,音频信息来驱动姿态的节奏和风格,从而实现更自然和可控的姿态生成。此外,该方法还引入了噪声情感分类器,用于优化情感表达。
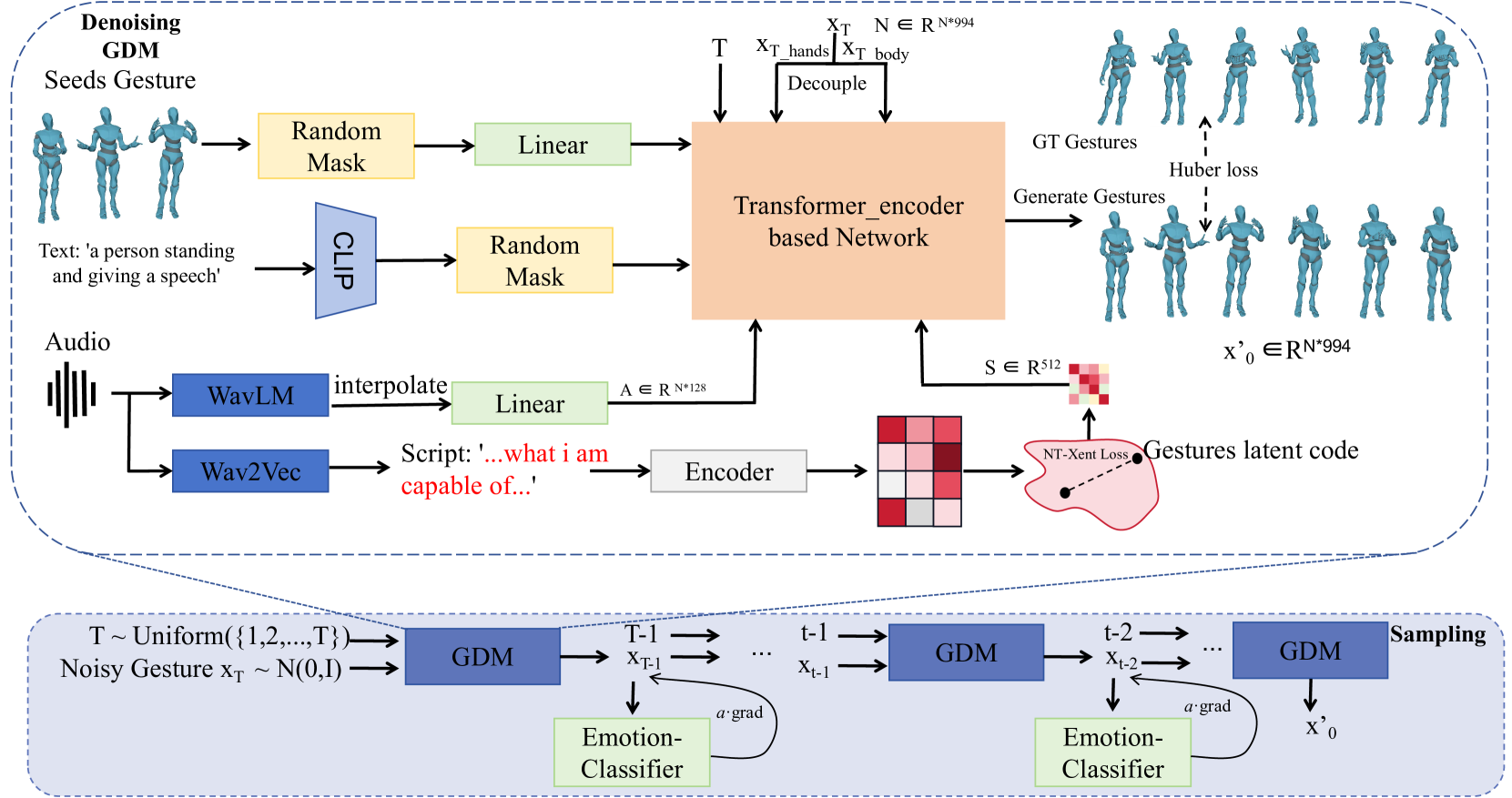
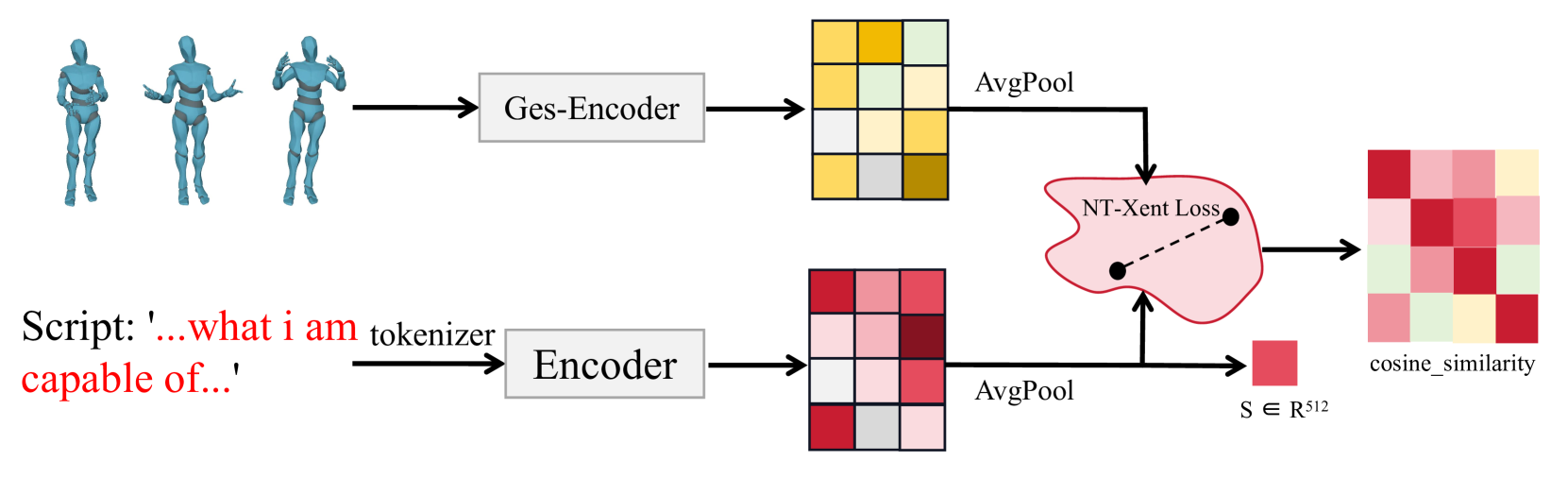
技术框架:ExpGest框架主要包含以下几个模块:1) 音频特征提取模块,用于提取音频的声学特征;2) 文本特征提取模块,用于提取文本的语义特征;3) 扩散模型,用于生成姿态序列;4) 噪声情感分类器,用于优化生成姿态的情感表达。该框架首先将音频和文本特征输入到扩散模型中,生成初始的姿态序列。然后,利用噪声情感分类器对生成的姿态序列进行优化,使其更符合指定的情感。
关键创新:ExpGest的关键创新在于:1) 首次将扩散模型应用于全身姿态生成任务;2) 提出了一种混合音文引导的姿态生成方法,能够同时利用音频和文本信息;3) 设计了一种噪声情感分类器,用于优化生成姿态的情感表达。与现有方法相比,ExpGest能够生成更富有表现力、自然和可控的全身姿态。
关键设计:噪声情感分类器的设计是关键。它通过对抗训练的方式,引导扩散模型生成符合特定情感的姿态。具体来说,该分类器被训练来区分不同情感的噪声,然后利用这些噪声来引导扩散模型的生成过程。损失函数包括扩散模型的重建损失、情感分类器的交叉熵损失以及对抗损失。网络结构方面,扩散模型采用U-Net结构,情感分类器采用卷积神经网络结构。
🖼️ 关键图片

📊 实验亮点
ExpGest通过混合音文引导和噪声情感分类器,在姿态生成任务上取得了显著的性能提升。实验结果表明,ExpGest能够生成更自然、富有表现力和可控的全身姿态。与现有最先进的模型相比,ExpGest在主观评价和客观指标上均有明显优势,尤其是在情感表达方面,ExpGest生成的姿态更符合用户的预期。
🎯 应用场景
ExpGest可应用于虚拟人物生成、人机交互、游戏开发、动画制作等领域。该技术能够生成更自然、富有表现力的虚拟人物姿态,提升用户体验。例如,在虚拟助手应用中,ExpGest可以使虚拟助手根据用户的语音和文本指令,做出更符合语境的姿态,从而增强交互的真实感和趣味性。未来,该技术有望应用于更广泛的领域,如远程教育、虚拟现实等。
📄 摘要(原文)
Existing gesture generation methods primarily focus on upper body gestures based on audio features, neglecting speech content, emotion, and locomotion. These limitations result in stiff, mechanical gestures that fail to convey the true meaning of audio content. We introduce ExpGest, a novel framework leveraging synchronized text and audio information to generate expressive full-body gestures. Unlike AdaIN or one-hot encoding methods, we design a noise emotion classifier for optimizing adversarial direction noise, avoiding melody distortion and guiding results towards specified emotions. Moreover, aligning semantic and gestures in the latent space provides better generalization capabilities. ExpGest, a diffusion model-based gesture generation framework, is the first attempt to offer mixed generation modes, including audio-driven gestures and text-shaped motion. Experiments show that our framework effectively learns from combined text-driven motion and audio-induced gesture datasets, and preliminary results demonstrate that ExpGest achieves more expressive, natural, and controllable global motion in speakers compared to state-of-the-art models.