Music Genre Classification using Large Language Models
作者: Mohamed El Amine Meguenani, Alceu de Souza Britto, Alessandro Lameiras Koerich
分类: cs.SD, cs.CV, eess.AS
发布日期: 2024-10-10
备注: 7 pages
💡 一句话要点
利用预训练大语言模型进行音乐流派分类研究
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音乐流派分类 大语言模型 零样本学习 Transformer 音频特征提取
📋 核心要点
- 现有音乐流派分类方法在处理复杂音乐特征和泛化能力方面存在不足,尤其是在零样本场景下。
- 本文提出利用预训练大语言模型(LLMs)的零样本能力,直接从音频特征中学习音乐流派的表示。
- 实验结果表明,基于Transformer的AST模型在音乐流派分类任务中表现出色,准确率达到85.5%,优于其他模型。
📝 摘要(中文)
本文探索了预训练大语言模型(LLMs)在音乐流派分类中的零样本能力。该方法将音频信号分割成20毫秒的片段,并通过卷积特征编码器、Transformer编码器以及额外的层进行处理,以编码音频单元并生成特征向量。提取的特征向量用于训练分类头。在推理阶段,对各个片段的预测进行聚合,以获得最终的流派分类结果。我们对包括WavLM、HuBERT和wav2vec 2.0在内的大语言模型与传统深度学习架构(如1D和2D卷积神经网络(CNN)以及音频频谱图Transformer(AST))进行了全面比较。结果表明,AST模型的性能优于其他模型,总体准确率达到85.5%。这些结果突显了LLM和基于Transformer的架构在推进音乐信息检索任务方面的潜力,即使在零样本场景下也是如此。
🔬 方法详解
问题定义:论文旨在解决音乐流派分类问题,尤其是在零样本学习场景下的挑战。现有方法,如传统的CNN和手工设计的特征,在捕捉音乐的复杂性和泛化能力方面存在局限性。预训练模型在其他领域展现出强大的零样本能力,但在音乐流派分类中的应用仍有待探索。
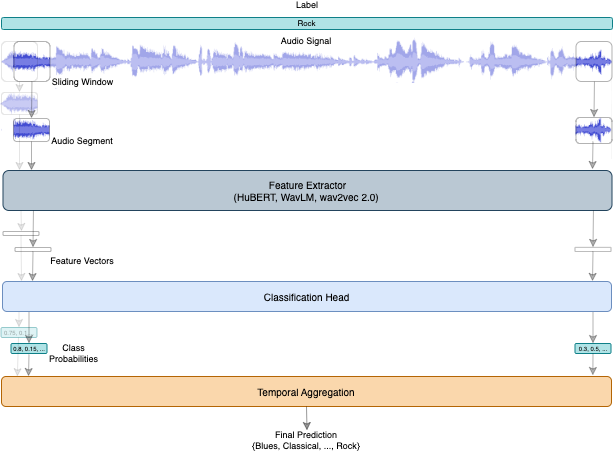
核心思路:论文的核心思路是利用预训练大语言模型(LLMs)的强大特征提取能力和零样本学习能力,直接从音频信号中学习音乐流派的表示。通过将音频信号转换为适合LLM处理的特征向量,并利用LLM进行分类,从而实现高效的音乐流派分类。
技术框架:整体框架包括以下几个主要模块:1) 音频预处理:将音频信号分割成20ms的片段。2) 特征编码:使用卷积特征编码器、Transformer编码器以及额外的层来编码音频单元并生成特征向量。3) 分类头训练:使用提取的特征向量训练分类头。4) 推理:对各个片段的预测进行聚合,以获得最终的流派分类结果。使用的LLM包括WavLM、HuBERT和wav2vec 2.0。
关键创新:该论文的关键创新在于探索了预训练大语言模型在音乐流派分类中的零样本能力。与传统方法相比,该方法无需大量标注数据进行训练,可以直接利用预训练模型的知识进行分类。此外,论文还比较了不同LLM和传统深度学习架构的性能,为音乐流派分类任务提供了新的思路。
关键设计:音频片段长度设置为20ms,以捕捉短时音乐特征。特征编码器采用卷积层和Transformer层相结合的方式,以提取音频信号的时域和频域特征。分类头采用全连接层,并使用交叉熵损失函数进行训练。实验中对比了不同LLM(WavLM、HuBERT和wav2vec 2.0)以及传统深度学习架构(1D CNN、2D CNN和AST)的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,基于Transformer的AST模型在音乐流派分类任务中表现最佳,总体准确率达到85.5%,优于其他模型,包括WavLM、HuBERT、wav2vec 2.0、1D CNN和2D CNN。这一结果突显了Transformer架构在处理音频信号方面的优势,并为音乐信息检索任务提供了新的方向。
🎯 应用场景
该研究成果可应用于音乐推荐系统、音乐检索、自动音乐标注等领域。通过利用预训练模型的零样本能力,可以降低对大量标注数据的依赖,提高音乐信息检索系统的效率和准确性。未来,该方法还可以扩展到其他音频分类任务,如语音识别、环境声音识别等。
📄 摘要(原文)
This paper exploits the zero-shot capabilities of pre-trained large language models (LLMs) for music genre classification. The proposed approach splits audio signals into 20 ms chunks and processes them through convolutional feature encoders, a transformer encoder, and additional layers for coding audio units and generating feature vectors. The extracted feature vectors are used to train a classification head. During inference, predictions on individual chunks are aggregated for a final genre classification. We conducted a comprehensive comparison of LLMs, including WavLM, HuBERT, and wav2vec 2.0, with traditional deep learning architectures like 1D and 2D convolutional neural networks (CNNs) and the audio spectrogram transformer (AST). Our findings demonstrate the superior performance of the AST model, achieving an overall accuracy of 85.5%, surpassing all other models evaluated. These results highlight the potential of LLMs and transformer-based architectures for advancing music information retrieval tasks, even in zero-shot scenarios.