SPA: 3D Spatial-Awareness Enables Effective Embodied Representation
作者: Haoyi Zhu, Honghui Yang, Yating Wang, Jiange Yang, Limin Wang, Tong He
分类: cs.CV, cs.AI, cs.LG, cs.RO
发布日期: 2024-10-10 (更新: 2025-03-01)
备注: Project Page: https://haoyizhu.github.io/spa/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
SPA:通过3D空间感知增强具身智能的有效表征学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 表征学习 3D空间感知 可微神经渲染 Vision Transformer
📋 核心要点
- 现有具身智能表征学习方法缺乏有效的3D空间感知能力,限制了智能体对环境的理解和交互。
- SPA框架利用可微神经渲染技术,从多视角图像中提取3D空间信息,增强Vision Transformer的空间理解能力。
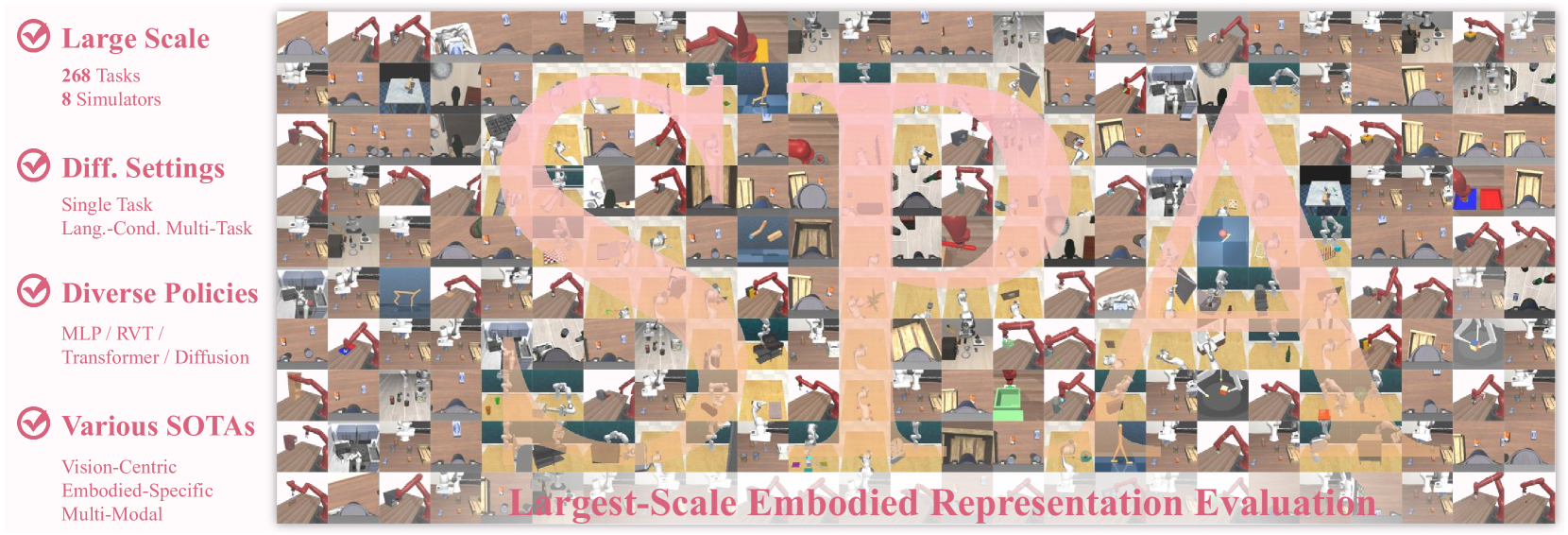
- 实验结果表明,SPA在多个模拟器和真实世界场景中,显著优于现有表征学习方法,证明了3D空间感知的重要性。
📝 摘要(中文)
本文提出了一种名为SPA的新型表征学习框架,强调了3D空间感知在具身智能中的重要性。该方法利用多视角图像上的可微神经渲染,赋予了原始的Vision Transformer (ViT)内在的空间理解能力。我们对具身表征学习进行了迄今为止最全面的评估,涵盖了8个模拟器中的268个任务,这些任务具有单任务和语言条件多任务场景中的各种策略。结果表明,SPA始终优于10多种最先进的表征方法,包括那些专门为具身智能、以视觉为中心任务和多模态应用而设计的方法,同时使用更少的训练数据。此外,我们进行了一系列真实世界的实验,以证实其在实际场景中的有效性。这些结果突出了3D空间感知对于具身表征学习的关键作用。我们最强大的模型需要超过6000个GPU小时进行训练,并且我们致力于开源所有代码和模型权重,以促进未来在具身表征学习方面的研究。
🔬 方法详解
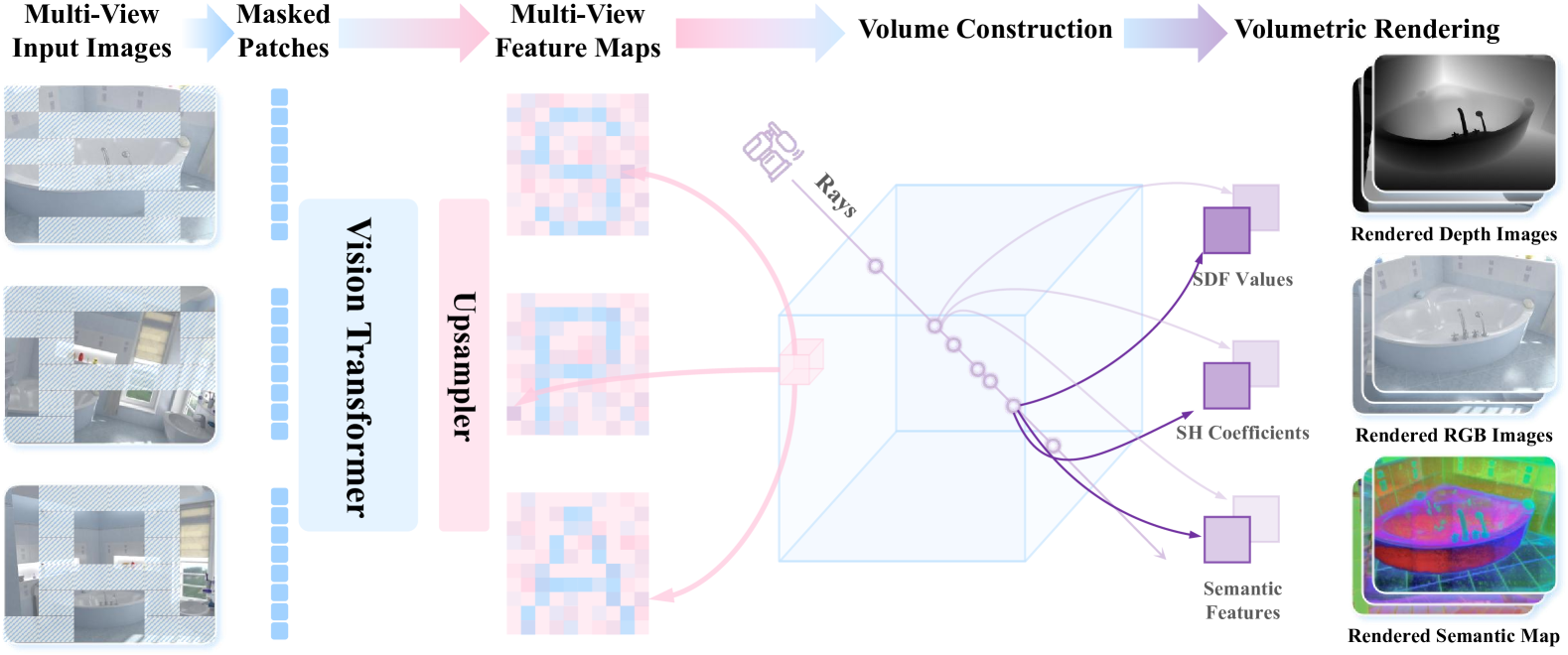
问题定义:现有具身智能的表征学习方法通常依赖于2D图像特征,缺乏对环境的3D空间结构的理解,导致智能体在复杂环境中的导航、操作等任务中表现不佳。现有方法难以有效利用多视角信息,无法建立一致的3D场景表征。
核心思路:SPA的核心在于通过可微神经渲染技术,将多视角图像信息融合到Vision Transformer (ViT)中,赋予ViT内在的3D空间感知能力。通过学习从多视角图像重建3D场景,智能体可以更好地理解环境的几何结构和空间关系。
技术框架:SPA框架主要包含以下几个模块:1) 多视角图像输入:从多个视角获取环境图像。2) 可微神经渲染模块:利用神经渲染技术,从多视角图像中重建3D场景。3) Vision Transformer (ViT):使用ViT提取图像特征,并融合从神经渲染模块获得的3D空间信息。4) 表征学习模块:通过对比学习等方法,学习有效的具身智能表征。整体流程是,多视角图像经过神经渲染模块得到3D信息,与ViT提取的图像特征融合,最终学习到具有空间感知的表征。
关键创新:SPA的关键创新在于将可微神经渲染与Vision Transformer相结合,实现了端到端的3D空间感知表征学习。与传统方法相比,SPA能够更有效地利用多视角信息,学习到更鲁棒、更具泛化能力的3D场景表征。
关键设计:SPA的关键设计包括:1) 使用NeRF (Neural Radiance Fields) 作为可微神经渲染模块,实现高质量的3D场景重建。2) 设计特定的融合机制,将神经渲染模块输出的3D信息与ViT提取的图像特征进行有效融合。3) 使用对比学习损失函数,鼓励智能体学习到对环境变化具有不变性的表征。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
SPA在268个任务和8个模拟器上的综合评估中,始终优于10多种最先进的表征方法,包括专门为具身智能、视觉任务和多模态应用设计的模型。SPA在多个真实世界实验中也表现出良好的性能。值得注意的是,SPA在取得优异性能的同时,使用了更少的训练数据,表明其具有更高的学习效率。
🎯 应用场景
SPA框架具有广泛的应用前景,可应用于机器人导航、物体操作、场景理解等领域。通过增强智能体的3D空间感知能力,可以提高机器人在复杂环境中的适应性和鲁棒性。该研究成果对于推动具身智能的发展具有重要意义,有望应用于自动驾驶、智能家居、工业自动化等领域。
📄 摘要(原文)
In this paper, we introduce SPA, a novel representation learning framework that emphasizes the importance of 3D spatial awareness in embodied AI. Our approach leverages differentiable neural rendering on multi-view images to endow a vanilla Vision Transformer (ViT) with intrinsic spatial understanding. We present the most comprehensive evaluation of embodied representation learning to date, covering 268 tasks across 8 simulators with diverse policies in both single-task and language-conditioned multi-task scenarios. The results are compelling: SPA consistently outperforms more than 10 state-of-the-art representation methods, including those specifically designed for embodied AI, vision-centric tasks, and multi-modal applications, while using less training data. Furthermore, we conduct a series of real-world experiments to confirm its effectiveness in practical scenarios. These results highlight the critical role of 3D spatial awareness for embodied representation learning. Our strongest model takes more than 6000 GPU hours to train and we are committed to open-sourcing all code and model weights to foster future research in embodied representation learning. Project Page: https://haoyizhu.github.io/spa/.