Mono-InternVL: Pushing the Boundaries of Monolithic Multimodal Large Language Models with Endogenous Visual Pre-training
作者: Gen Luo, Xue Yang, Wenhan Dou, Zhaokai Wang, Jiawen Liu, Jifeng Dai, Yu Qiao, Xizhou Zhu
分类: cs.CV, cs.CL
发布日期: 2024-10-10 (更新: 2025-03-13)
备注: Accepted by CVPR 2025
🔗 代码/项目: GITHUB
💡 一句话要点
Mono-InternVL:通过内生视觉预训练提升单体多模态大语言模型性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉预训练 混合专家模型 单体模型 内生学习
📋 核心要点
- 现有单体多模态大语言模型预训练易出现优化不稳定和灾难性遗忘,限制了模型性能。
- 提出Mono-InternVL,通过内生视觉预训练(EViP)将视觉知识稳定地嵌入到预训练LLM中。
- 实验表明,Mono-InternVL在多个基准测试中超越现有单体MLLM,并降低了首token延迟。
📝 摘要(中文)
本文关注将视觉编码和语言解码集成到单个LLM中的单体多模态大语言模型(MLLM)。现有单体MLLM的预训练策略常面临优化不稳定或灾难性遗忘问题。为解决此问题,核心思想是将新的视觉参数空间嵌入到预训练的LLM中,从而在冻结LLM的同时,稳定地从噪声数据中学习视觉知识。基于此,提出了Mono-InternVL,一种通过多模态混合专家结构无缝集成一组视觉专家的新型单体MLLM。此外,提出了一种创新的预训练策略,即内生视觉预训练(EViP),旨在最大化Mono-InternVL的视觉能力。EViP被设计为视觉专家的渐进式学习过程,旨在充分利用从噪声数据到高质量数据的视觉知识。在16个基准测试上进行了大量实验,结果表明Mono-InternVL在16个多模态基准测试中的13个上优于现有的单体MLLM,例如在OCRBench上比Emu3高出80分。与模块化基线InternVL-1.5相比,Mono-InternVL在保持相当的多模态性能的同时,最多可减少67%的首token延迟。代码和模型已发布。
🔬 方法详解
问题定义:现有单体多模态大语言模型(MLLM)的预训练过程容易出现优化不稳定和灾难性遗忘的问题。这是因为在训练过程中,视觉和语言模态的知识需要同时学习,容易导致模型在学习新知识时忘记已有的知识。此外,噪声数据也会影响模型的学习效果。
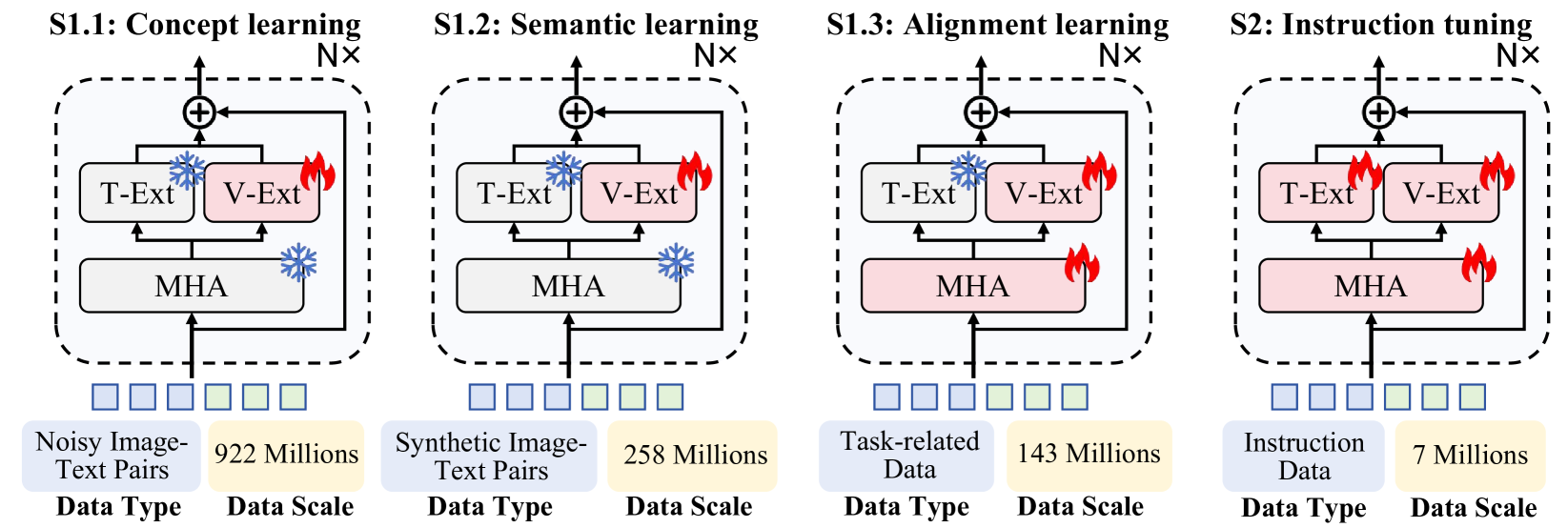
核心思路:论文的核心思路是将视觉知识的学习过程与语言知识的学习过程解耦。具体来说,是将一个新的视觉参数空间嵌入到一个预训练好的LLM中,并且在训练视觉参数时冻结LLM的参数。这样可以保证在学习视觉知识的同时,不会影响到LLM已有的语言知识,从而避免灾难性遗忘。同时,通过渐进式的学习策略,逐步从噪声数据中提取高质量的视觉知识。
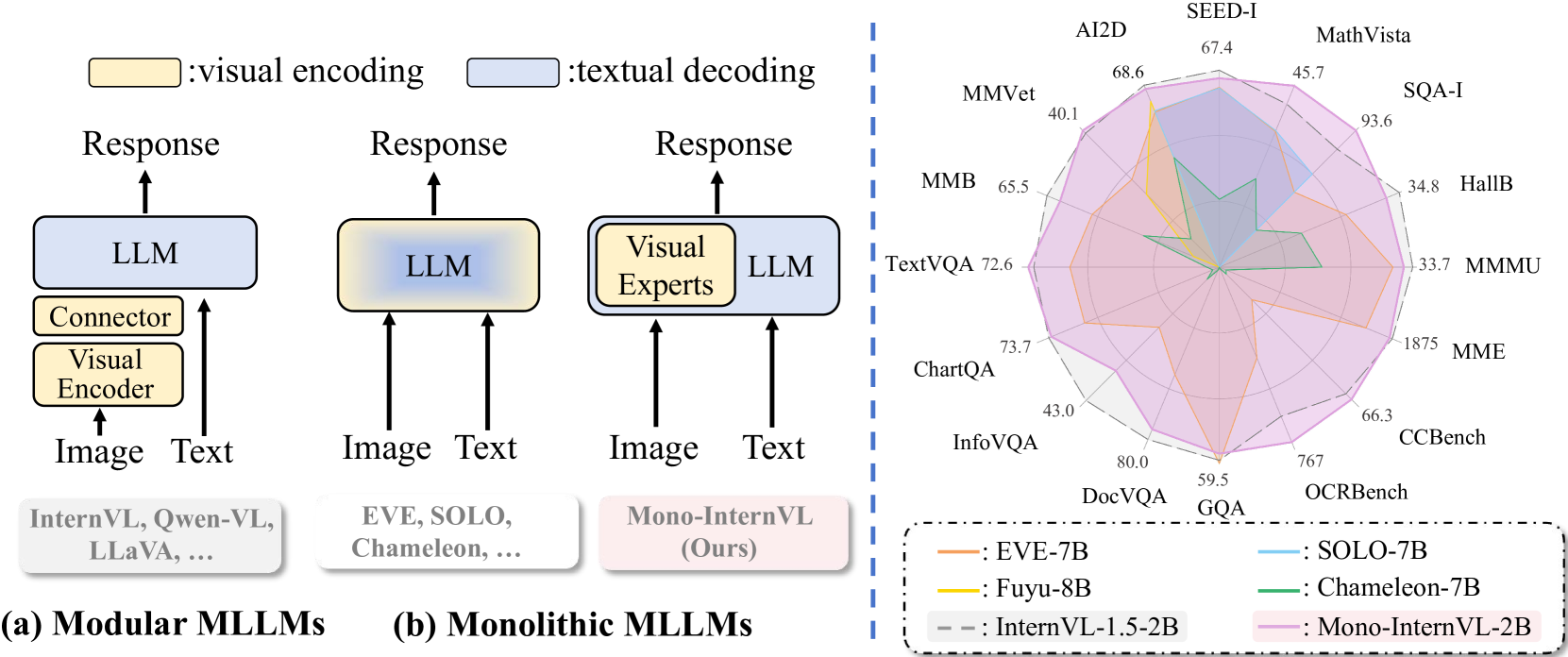
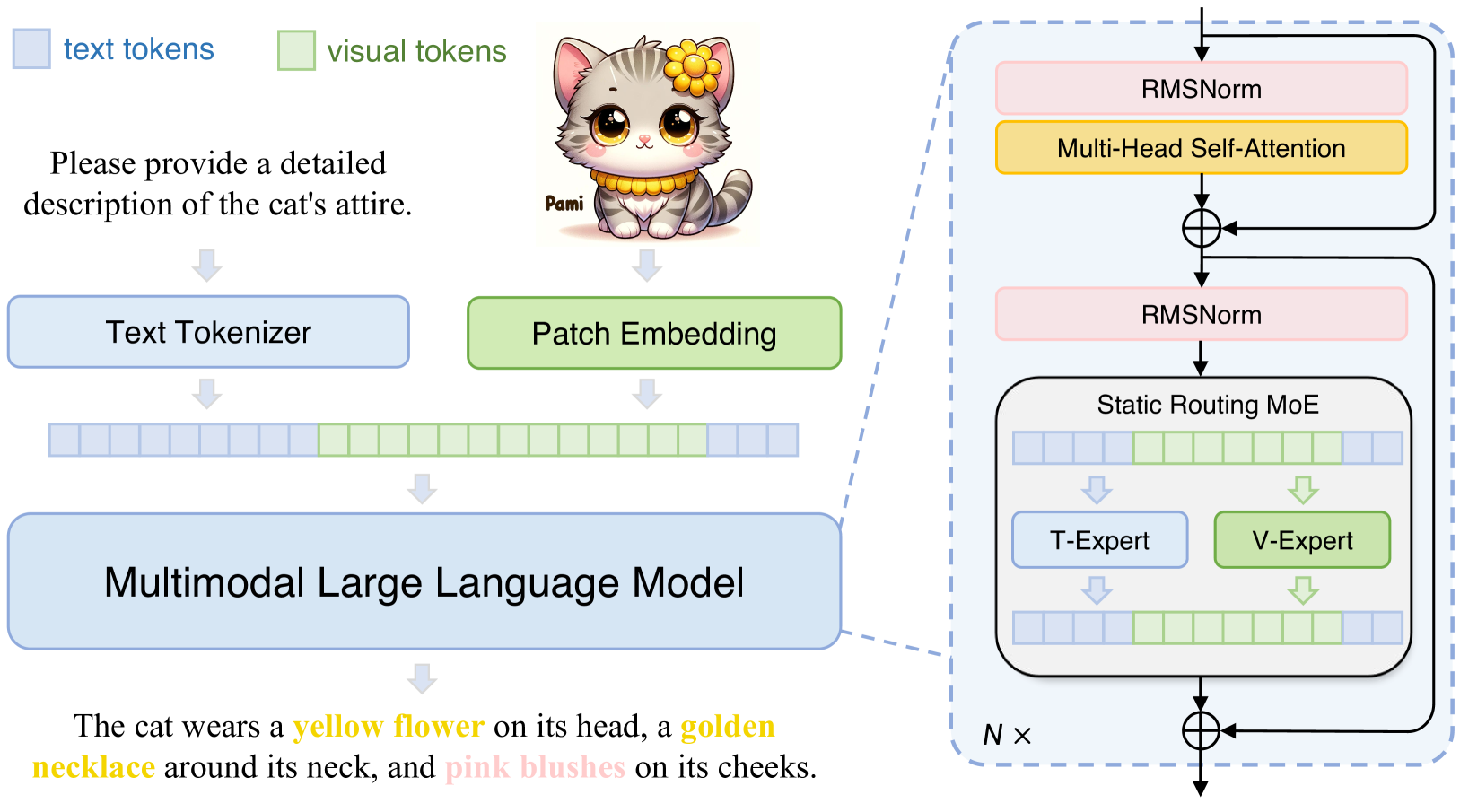
技术框架:Mono-InternVL的整体架构包含一个预训练的LLM和一组视觉专家。视觉专家通过一个多模态混合专家(MoE)结构集成到LLM中。预训练过程分为两个阶段:首先,使用内生视觉预训练(EViP)策略训练视觉专家,使其能够从噪声数据中学习视觉知识。然后,将训练好的视觉专家集成到LLM中,并进行微调,以使模型能够更好地理解和处理多模态数据。
关键创新:论文的关键创新在于提出了内生视觉预训练(EViP)策略。EViP是一种渐进式的学习策略,它首先使用大量的噪声数据训练视觉专家,然后逐步使用高质量的数据进行微调。这种策略可以有效地利用噪声数据中的信息,并提高模型的鲁棒性。此外,通过MoE结构集成视觉专家,可以提高模型的容量和表达能力。
关键设计:EViP包含多个阶段,每个阶段使用不同质量的数据进行训练。损失函数包括图像文本匹配损失、图像描述生成损失等。MoE结构中的专家数量和路由策略需要根据具体任务进行调整。具体参数设置未知。
🖼️ 关键图片
📊 实验亮点
Mono-InternVL在16个多模态基准测试中的13个上超越了现有单体MLLM,例如在OCRBench上比Emu3高出80分。与模块化基线InternVL-1.5相比,Mono-InternVL在保持相当的多模态性能的同时,最多可减少67%的首token延迟。这些结果表明,Mono-InternVL在性能和效率方面都具有显著优势。
🎯 应用场景
Mono-InternVL具有广泛的应用前景,例如图像描述、视觉问答、图像检索、OCR等。该模型可以应用于智能客服、自动驾驶、智能家居等领域,提高人机交互的效率和智能化水平。未来,可以通过进一步优化模型结构和训练策略,提高模型的性能和泛化能力。
📄 摘要(原文)
In this paper, we focus on monolithic Multimodal Large Language Models (MLLMs) that integrate visual encoding and language decoding into a single LLM. In particular, we identify that existing pre-training strategies for monolithic MLLMs often suffer from unstable optimization or catastrophic forgetting. To address this issue, our core idea is to embed a new visual parameter space into a pre-trained LLM, thereby stably learning visual knowledge from noisy data while freezing the LLM. Based on this principle, we present Mono-InternVL, a novel monolithic MLLM that seamlessly integrates a set of visual experts via a multimodal mixture-of-experts structure. Moreover, we propose an innovative pre-training strategy to maximize the visual capability of Mono-InternVL, namely Endogenous Visual Pre-training (EViP). In particular, EViP is designed as a progressive learning process for visual experts, which aims to fully exploit the visual knowledge from noisy data to high-quality data. To validate our approach, we conduct extensive experiments on 16 benchmarks. Experimental results confirm the superior performance of Mono-InternVL than existing monolithic MLLMs on 13 of 16 multimodal benchmarks, e.g., +80 points over Emu3 on OCRBench. Compared to the modular baseline, i.e., InternVL-1.5, Mono-InternVL still retains comparable multimodal performance while reducing up to 67% first token latency. Code and model are released at https://github.com/OpenGVLab/Mono-InternVL.