SG-Nav: Online 3D Scene Graph Prompting for LLM-based Zero-shot Object Navigation
作者: Hang Yin, Xiuwei Xu, Zhenyu Wu, Jie Zhou, Jiwen Lu
分类: cs.CV, cs.RO
发布日期: 2024-10-10
备注: Accepted to NeurIPS 2024. Project page: https://bagh2178.github.io/SG-Nav/
💡 一句话要点
SG-Nav:基于LLM和在线3D场景图提示的零样本物体导航
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 零样本学习 物体导航 3D场景图 大型语言模型 机器人 环境感知 思维链提示
📋 核心要点
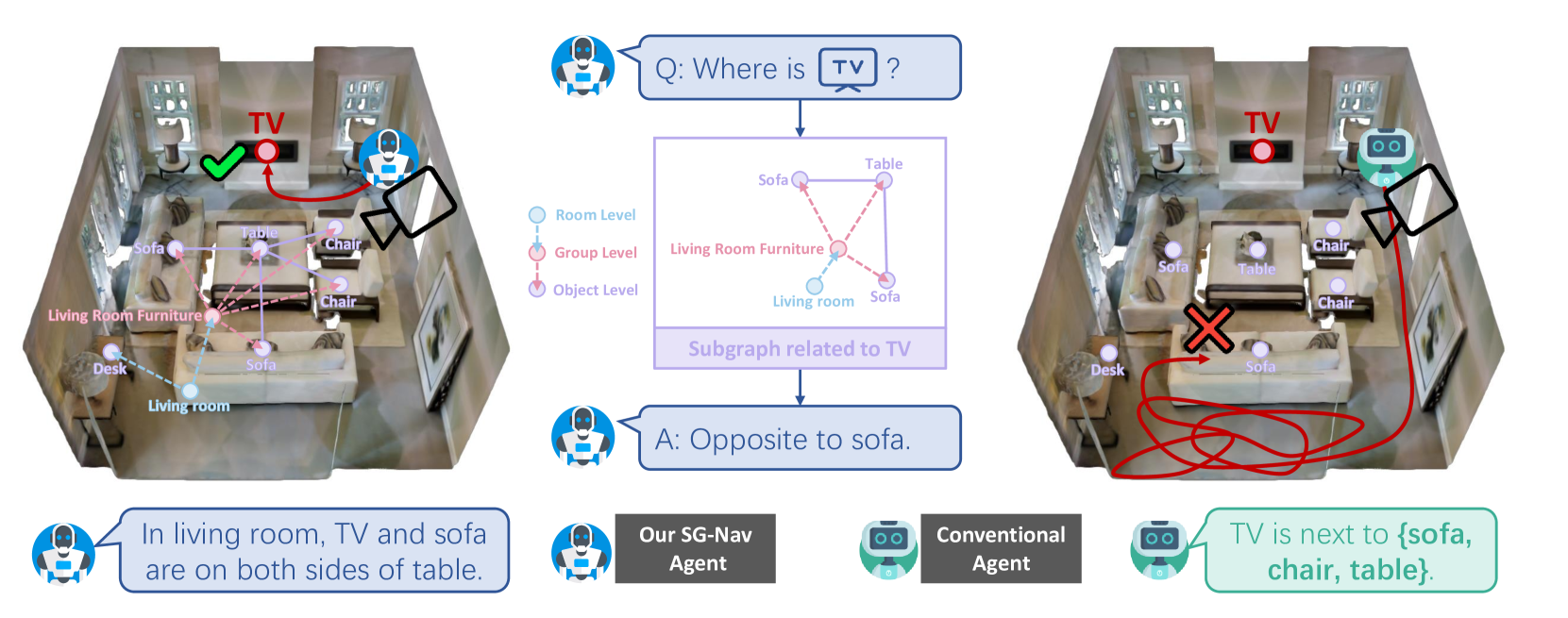
- 现有零样本物体导航方法依赖于局部文本信息,缺乏全局场景理解,限制了LLM的推理能力。
- SG-Nav利用3D场景图编码环境信息,并设计分层思维链提示,引导LLM进行场景上下文推理。
- 实验结果表明,SG-Nav在多个benchmark上显著超越现有零样本方法,甚至在MP3D上超过了监督方法。
📝 摘要(中文)
本文提出了一种新的零样本物体导航框架。现有的方法通常使用空间上临近物体的文本来提示LLM,缺乏足够的场景上下文进行深入推理。为了更好地保留环境信息并充分利用LLM的推理能力,我们提出使用3D场景图来表示观察到的场景。该场景图以LLM友好的结构编码物体、组和房间之间的关系,为此我们设计了一种分层的思维链提示,通过遍历节点和边来帮助LLM根据场景上下文推理目标位置。此外,受益于场景图表示,我们进一步设计了一种重感知机制,使物体导航框架具备纠正感知错误的能力。在MP3D、HM3D和RoboTHOR环境中的大量实验表明,SG-Nav在所有基准测试中超越了先前的最先进零样本方法,SR提升超过10%,并且决策过程是可解释的。据我们所知,SG-Nav是第一个在具有挑战性的MP3D基准测试中实现甚至高于监督物体导航方法性能的零样本方法。
🔬 方法详解
问题定义:现有的零样本物体导航方法主要依赖于局部感知的文本信息来提示大型语言模型(LLM),缺乏对整个场景的上下文理解。这种局部信息不足以支持LLM进行深入的推理,导致导航性能受限。此外,现有的方法通常难以纠正感知错误,进一步降低了导航的鲁棒性。
核心思路:SG-Nav的核心思路是利用3D场景图来表示环境,从而为LLM提供更丰富的场景上下文信息。场景图能够编码物体、组和房间之间的关系,使LLM能够更好地理解环境的结构和语义。通过设计合适的提示策略,引导LLM在场景图中进行推理,从而实现更准确的物体导航。
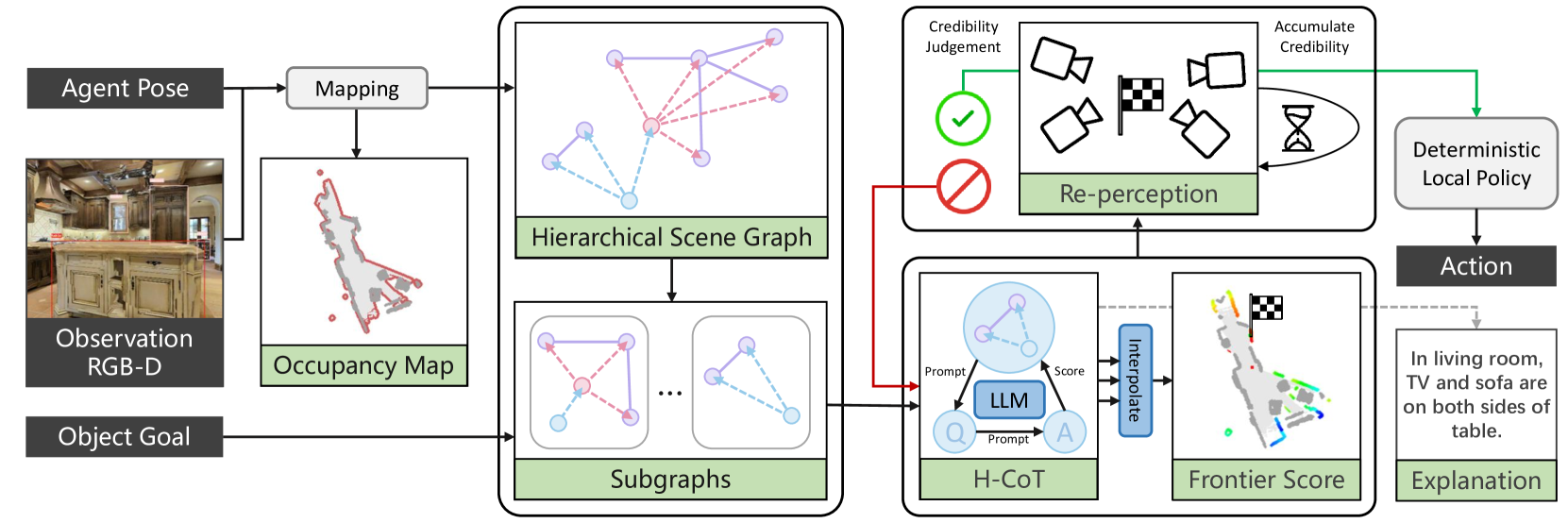
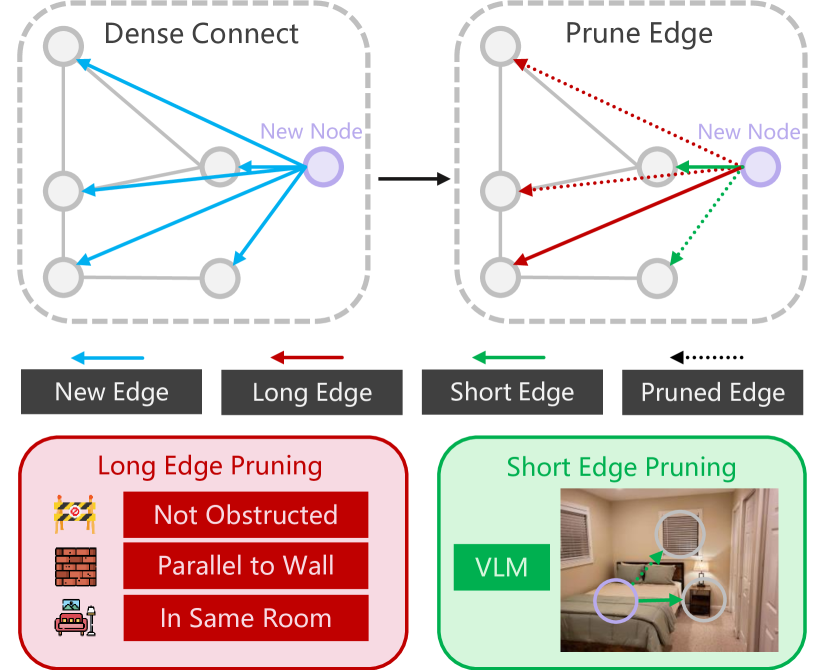
技术框架:SG-Nav的整体框架包括以下几个主要模块:1) 场景感知模块:负责从环境中获取视觉信息,并构建3D场景图。2) 场景图提示模块:将场景图转换为LLM可以理解的文本提示,包括分层思维链提示。3) LLM推理模块:利用LLM对提示进行推理,生成导航指令。4) 运动控制模块:根据LLM的指令控制机器人进行运动。5) 重感知模块:在导航过程中,不断更新场景图,并纠正感知错误。
关键创新:SG-Nav的关键创新在于以下几个方面:1) 提出了一种基于3D场景图的场景表示方法,能够有效地编码环境的结构和语义信息。2) 设计了一种分层思维链提示策略,引导LLM在场景图中进行推理,从而实现更准确的物体导航。3) 引入了一种重感知机制,能够纠正感知错误,提高导航的鲁棒性。
关键设计:场景图的构建依赖于3D重建和物体识别技术。分层思维链提示包括多个步骤,例如:确定当前位置、识别目标物体可能存在的区域、规划导航路径等。重感知机制通过比较当前观测和场景图中的信息,检测并纠正感知错误。具体的参数设置和网络结构等技术细节在论文中进行了详细描述(未知)。
🖼️ 关键图片
📊 实验亮点
SG-Nav在MP3D、HM3D和RoboTHOR等多个benchmark上取得了显著的性能提升。在所有基准测试中,SG-Nav超越了先前的最先进零样本方法,SR提升超过10%。特别是在具有挑战性的MP3D基准测试中,SG-Nav甚至实现了高于监督物体导航方法的性能,证明了该方法的有效性和优越性。
🎯 应用场景
SG-Nav具有广泛的应用前景,例如:家庭服务机器人、仓储物流机器人、自动驾驶等领域。该方法可以使机器人在复杂的环境中自主导航,完成各种任务,例如:寻找物品、清洁房间、搬运货物等。此外,SG-Nav还可以应用于虚拟现实和增强现实等领域,为用户提供更智能、更自然的交互体验。
📄 摘要(原文)
In this paper, we propose a new framework for zero-shot object navigation. Existing zero-shot object navigation methods prompt LLM with the text of spatially closed objects, which lacks enough scene context for in-depth reasoning. To better preserve the information of environment and fully exploit the reasoning ability of LLM, we propose to represent the observed scene with 3D scene graph. The scene graph encodes the relationships between objects, groups and rooms with a LLM-friendly structure, for which we design a hierarchical chain-of-thought prompt to help LLM reason the goal location according to scene context by traversing the nodes and edges. Moreover, benefit from the scene graph representation, we further design a re-perception mechanism to empower the object navigation framework with the ability to correct perception error. We conduct extensive experiments on MP3D, HM3D and RoboTHOR environments, where SG-Nav surpasses previous state-of-the-art zero-shot methods by more than 10% SR on all benchmarks, while the decision process is explainable. To the best of our knowledge, SG-Nav is the first zero-shot method that achieves even higher performance than supervised object navigation methods on the challenging MP3D benchmark.