A transition towards virtual representations of visual scenes
作者: Américo Pereira, Pedro Carvalho, Luís Côrte-Real
分类: cs.CV
发布日期: 2024-10-10
💡 一句话要点
提出一种面向3D虚拟合成的视觉场景理解架构,实现统一灵活的场景描述。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视觉场景理解 3D虚拟合成 虚拟现实 增强现实 场景描述
📋 核心要点
- 现有视觉场景理解方法缺乏统一框架,难以适应复杂系统和新兴的虚拟现实应用。
- 论文提出一种架构,将视觉场景理解与3D虚拟合成相结合,实现灵活统一的场景描述。
- 通过概念验证系统,验证了所提架构在实际应用中的可用性,并展示了其潜在价值。
📝 摘要(中文)
视觉场景理解是计算机视觉中的一项基本任务,旨在从视觉数据中提取有意义的信息。传统方法通常采用针对特定应用场景的、互不关联的专用算法。在设计包含视觉和语义数据处理的复杂系统时,尤其是在虚拟或增强现实应用激增的今天,这种方式显得笨拙。为了解决这个问题,我们提出了一种架构,旨在应对视觉场景理解和描述的挑战,最终实现可适应、统一和连贯的3D虚拟合成。此外,我们还展示了该方案在多个应用领域的用途,并提供了一个概念验证系统,以进一步证明其在实践中的可用性。
🔬 方法详解
问题定义:现有视觉场景理解方法通常针对特定任务和应用场景设计,缺乏通用性和灵活性。在构建复杂的、需要将视觉理解结果用于3D虚拟合成的系统时,这种碎片化的方法会带来诸多不便,例如数据格式不兼容、算法难以集成等。因此,需要一种统一的框架,能够灵活地处理各种视觉场景,并将其转化为可用于虚拟合成的表示形式。
核心思路:论文的核心思路是将视觉场景理解过程转化为对场景的虚拟表示的构建。通过构建一个中间的、统一的虚拟表示,可以解耦视觉理解和虚拟合成两个过程,从而提高系统的灵活性和可扩展性。这种虚拟表示应该包含场景的几何信息、语义信息以及其他相关属性,以便于后续的虚拟合成。
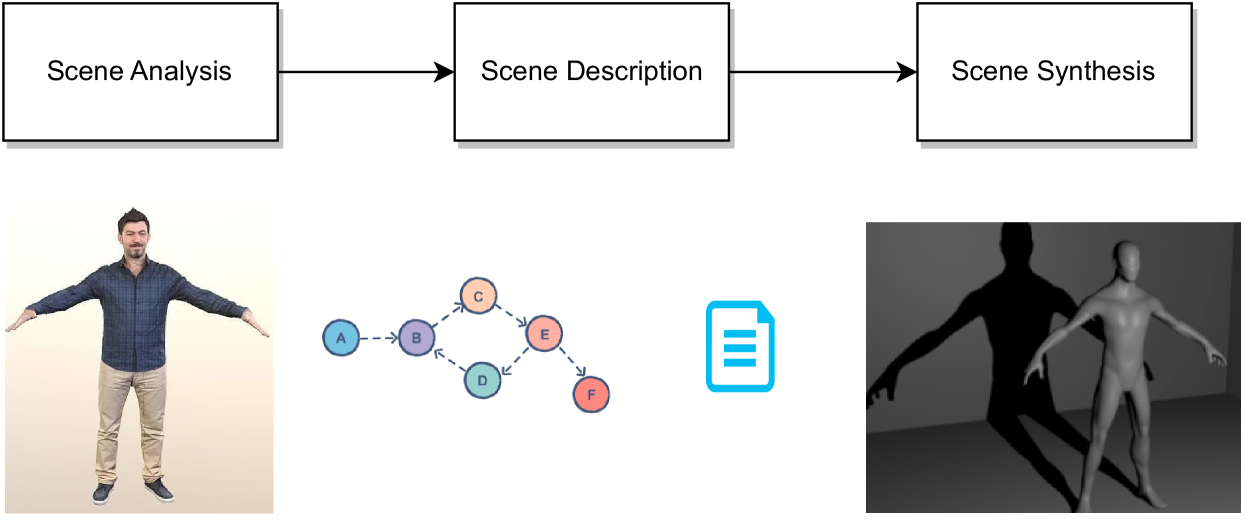
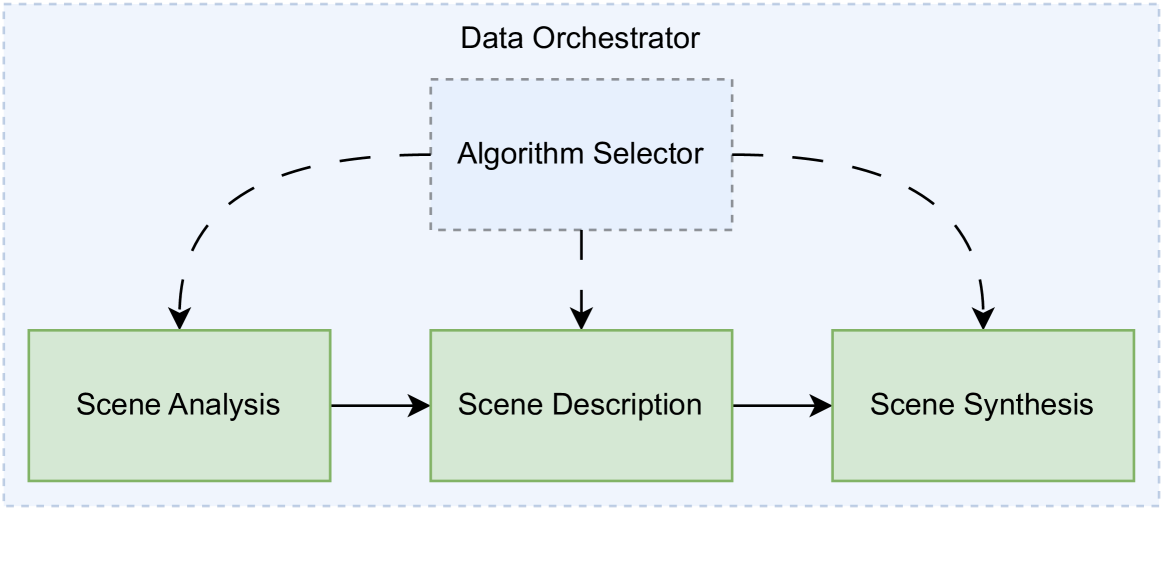
技术框架:论文提出的架构包含以下几个主要模块:1) 视觉数据输入模块,负责接收各种类型的视觉数据,例如图像、视频、点云等;2) 场景理解模块,负责从视觉数据中提取场景的几何信息和语义信息,例如物体检测、场景分割、深度估计等;3) 虚拟表示构建模块,负责将场景理解的结果转化为统一的虚拟表示,例如3D模型、场景图等;4) 虚拟合成模块,负责根据虚拟表示生成3D虚拟场景,并进行渲染和显示。
关键创新:论文的关键创新在于提出了将视觉场景理解与3D虚拟合成相结合的统一架构。与传统方法相比,该架构具有更高的灵活性和可扩展性,可以更好地适应各种应用场景。此外,论文还提出了一种基于虚拟表示的场景描述方法,可以更有效地表达场景的几何信息和语义信息。
关键设计:论文中没有详细描述关键参数设置、损失函数或网络结构等技术细节。概念验证系统采用的具体算法和技术未知。
🖼️ 关键图片

📊 实验亮点
论文提出了一个概念验证系统,验证了所提架构在实际应用中的可行性。虽然论文没有提供具体的性能数据或与其他基线的比较,但该系统展示了将视觉场景理解与3D虚拟合成相结合的潜力,为未来的研究奠定了基础。
🎯 应用场景
该研究成果可应用于虚拟现实、增强现实、机器人导航、智能监控等领域。例如,在虚拟现实游戏中,可以利用该技术自动生成逼真的游戏场景;在机器人导航中,可以帮助机器人理解周围环境,从而实现自主导航;在智能监控中,可以自动识别异常事件,并进行报警。
📄 摘要(原文)
Visual scene understanding is a fundamental task in computer vision that aims to extract meaningful information from visual data. It traditionally involves disjoint and specialized algorithms for different tasks that are tailored for specific application scenarios. This can be cumbersome when designing complex systems that include processing of visual and semantic data extracted from visual scenes, which is even more noticeable nowadays with the influx of applications for virtual or augmented reality. When designing a system that employs automatic visual scene understanding to enable a precise and semantically coherent description of the underlying scene, which can be used to fuel a visualization component with 3D virtual synthesis, the lack of flexibility and unified frameworks become more prominent. To alleviate this issue and its inherent problems, we propose an architecture that addresses the challenges of visual scene understanding and description towards a 3D virtual synthesis that enables an adaptable, unified and coherent solution. Furthermore, we expose how our proposition can be of use into multiple application areas. Additionally, we also present a proof of concept system that employs our architecture to further prove its usability in practice.