Deciphering Cross-Modal Alignment in Large Vision-Language Models with Modality Integration Rate
作者: Qidong Huang, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Yuhang Cao, Jiaqi Wang, Dahua Lin, Weiming Zhang, Nenghai Yu
分类: cs.CV, cs.CL
发布日期: 2024-10-09 (更新: 2024-10-16)
备注: Project page: https://github.com/shikiw/Modality-Integration-Rate
🔗 代码/项目: GITHUB
💡 一句话要点
提出模态融合率(MIR)指标,用于评估大规模视觉语言模型(LVLM)预训练质量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 预训练 模态融合 评估指标 跨模态对齐
📋 核心要点
- 现有LVLM预训练质量评估方法(如损失、困惑度)在跨模态对齐时表现不佳,缺乏有效指标阻碍了相关研究。
- 提出模态融合率(MIR),从模态间分布距离角度评估预训练质量,指标与模型微调后的性能正相关。
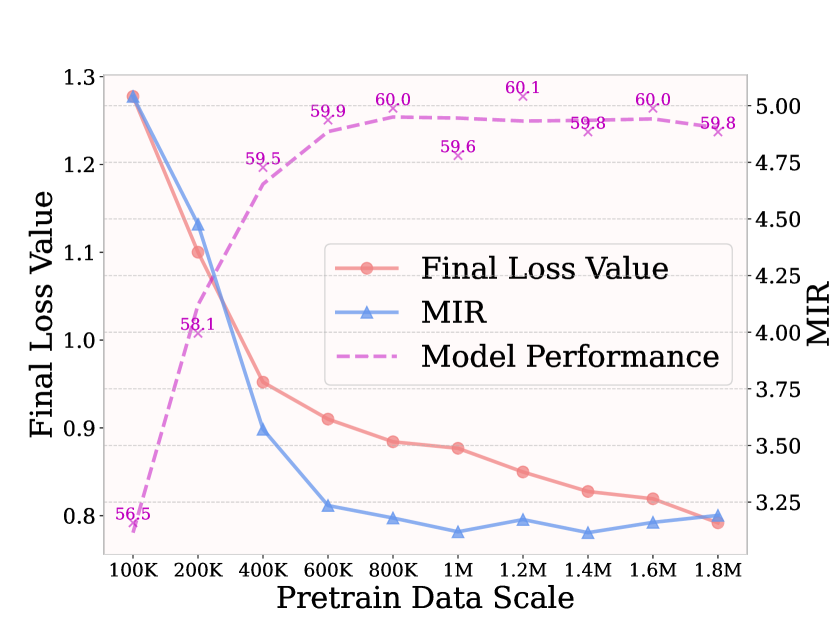
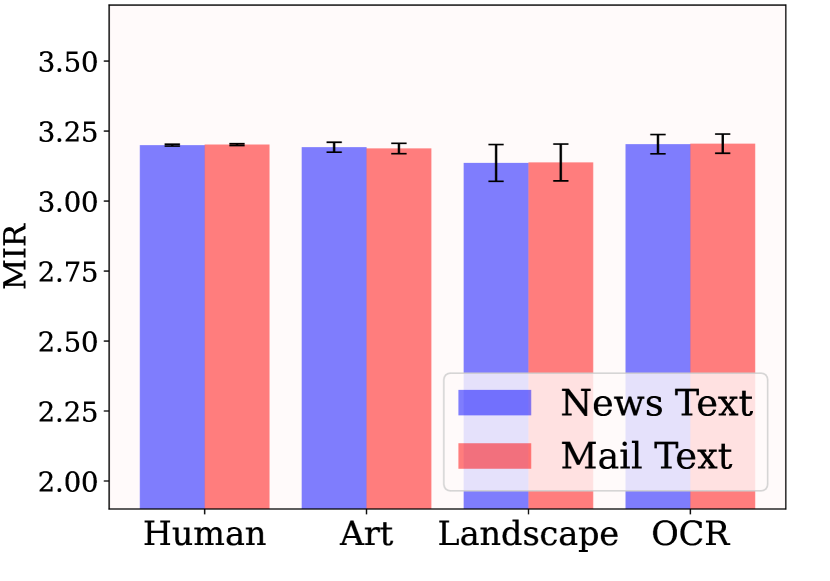
- 实验表明MIR在训练数据选择、训练策略和模型架构设计方面具有指导意义,能够提升预训练效果。
📝 摘要(中文)
本文提出了一种有效、鲁棒且通用的指标——模态融合率(MIR),用于评估大规模视觉语言模型(LVLM)的多模态预训练质量。大规模预训练在构建强大的LVLM中起着关键作用,但如何在没有昂贵的监督微调阶段的情况下评估其训练质量仍未得到充分探索。损失、困惑度和上下文评估结果通常被用作大型语言模型(LLM)的预训练指标,但我们观察到,当将训练良好的LLM与新的模态对齐时,这些指标的指示性较差。由于缺乏合适的指标,LVLM在关键的预训练阶段的研究受到了极大的阻碍,包括训练数据的选择、高效的模块设计等。本文从模态间分布距离的角度评估预训练质量,提出的MIR具有以下特点:1)有效:能够代表预训练质量,并与监督微调后的基准性能呈正相关。2)鲁棒:对不同的训练/评估数据具有鲁棒性。3)通用:可推广到不同的训练配置和架构选择。我们进行了一系列预训练实验,以探索MIR的有效性,并观察到令人满意的结果,即MIR可以指示训练数据选择、训练策略安排和模型架构设计,从而获得更好的预训练结果。我们希望MIR能够成为构建强大LVLM的有用指标,并激发后续关于不同领域模态对齐的研究。
🔬 方法详解
问题定义:论文旨在解决大规模视觉语言模型(LVLM)预训练阶段缺乏有效评估指标的问题。现有方法,如损失、困惑度等,在评估跨模态对齐质量时表现不佳,无法有效指导训练数据的选择、模块设计和训练策略的制定。这阻碍了LVLM的进一步发展。
核心思路:论文的核心思路是从模态间分布距离的角度来评估预训练质量。作者认为,一个好的LVLM预训练模型应该能够很好地将视觉和语言模态融合在一起,因此可以通过衡量两种模态的分布距离来评估融合程度。模态融合率(MIR)正是基于这一思路提出的。
技术框架:论文提出的MIR指标的计算流程大致如下:首先,使用预训练的LVLM模型分别提取视觉和语言模态的特征表示。然后,计算两种模态特征表示之间的距离,例如使用KL散度或Wasserstein距离等。最后,将计算得到的距离归一化,得到MIR值。MIR值越高,表示模态融合程度越高,预训练质量越好。
关键创新:论文的关键创新在于提出了模态融合率(MIR)这一指标,它提供了一种新的视角来评估LVLM的预训练质量。与传统的指标相比,MIR更关注模态间的对齐程度,能够更有效地反映LVLM的跨模态理解能力。此外,MIR具有鲁棒性和通用性,可以应用于不同的训练数据、训练配置和模型架构。
关键设计:MIR的具体计算公式需要根据所使用的距离度量方法进行调整。例如,如果使用KL散度,则MIR可以定义为:MIR = 1 - KL(P||Q),其中P和Q分别表示视觉和语言模态的特征分布。归一化方法也很重要,可以采用Min-Max归一化或Z-score归一化等。此外,特征提取器的选择也会影响MIR的计算结果,通常可以使用预训练的视觉和语言编码器。
🖼️ 关键图片
📊 实验亮点
实验结果表明,MIR指标与LVLM在下游任务上的性能具有很强的相关性。例如,使用MIR指导训练数据选择可以显著提升LVLM在图像描述、视觉问答等任务上的准确率。此外,MIR还能够有效指导模型架构设计和训练策略的制定,从而获得更好的预训练效果。
🎯 应用场景
该研究成果可应用于大规模视觉语言模型的预训练阶段,帮助研究人员选择更合适的训练数据、设计更有效的模型架构和训练策略,从而提升LVLM的性能。此外,该方法也可推广到其他多模态学习领域,例如语音-文本、视频-文本等。
📄 摘要(原文)
We present the Modality Integration Rate (MIR), an effective, robust, and generalized metric to indicate the multi-modal pre-training quality of Large Vision Language Models (LVLMs). Large-scale pre-training plays a critical role in building capable LVLMs, while evaluating its training quality without the costly supervised fine-tuning stage is under-explored. Loss, perplexity, and in-context evaluation results are commonly used pre-training metrics for Large Language Models (LLMs), while we observed that these metrics are less indicative when aligning a well-trained LLM with a new modality. Due to the lack of proper metrics, the research of LVLMs in the critical pre-training stage is hindered greatly, including the training data choice, efficient module design, etc. In this paper, we propose evaluating the pre-training quality from the inter-modal distribution distance perspective and present MIR, the Modality Integration Rate, which is 1) \textbf{Effective} to represent the pre-training quality and show a positive relation with the benchmark performance after supervised fine-tuning. 2) \textbf{Robust} toward different training/evaluation data. 3) \textbf{Generalize} across training configurations and architecture choices. We conduct a series of pre-training experiments to explore the effectiveness of MIR and observe satisfactory results that MIR is indicative about training data selection, training strategy schedule, and model architecture design to get better pre-training results. We hope MIR could be a helpful metric for building capable LVLMs and inspire the following research about modality alignment in different areas. Our code is at: https://github.com/shikiw/Modality-Integration-Rate.