Towards Realistic UAV Vision-Language Navigation: Platform, Benchmark, and Methodology
作者: Xiangyu Wang, Donglin Yang, Ziqin Wang, Hohin Kwan, Jinyu Chen, Wenjun Wu, Hongsheng Li, Yue Liao, Si Liu
分类: cs.CV, cs.RO
发布日期: 2024-10-09 (更新: 2024-10-10)
💡 一句话要点
提出OpenUAV平台与UAV-Need-Help基准,解决无人机视觉-语言导航的真实性问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 无人机导航 视觉语言导航 多模态学习 大语言模型 强化学习
📋 核心要点
- 现有无人机视觉-语言导航研究主要沿用地面机器人设定,忽略了无人机运动特性和环境复杂性。
- 论文提出OpenUAV平台和UAV-Need-Help基准,并设计UAV导航LLM,以应对真实无人机导航挑战。
- 实验结果表明,所提方法优于基线模型,但与人类水平仍有差距,表明该任务具有挑战性。
📝 摘要(中文)
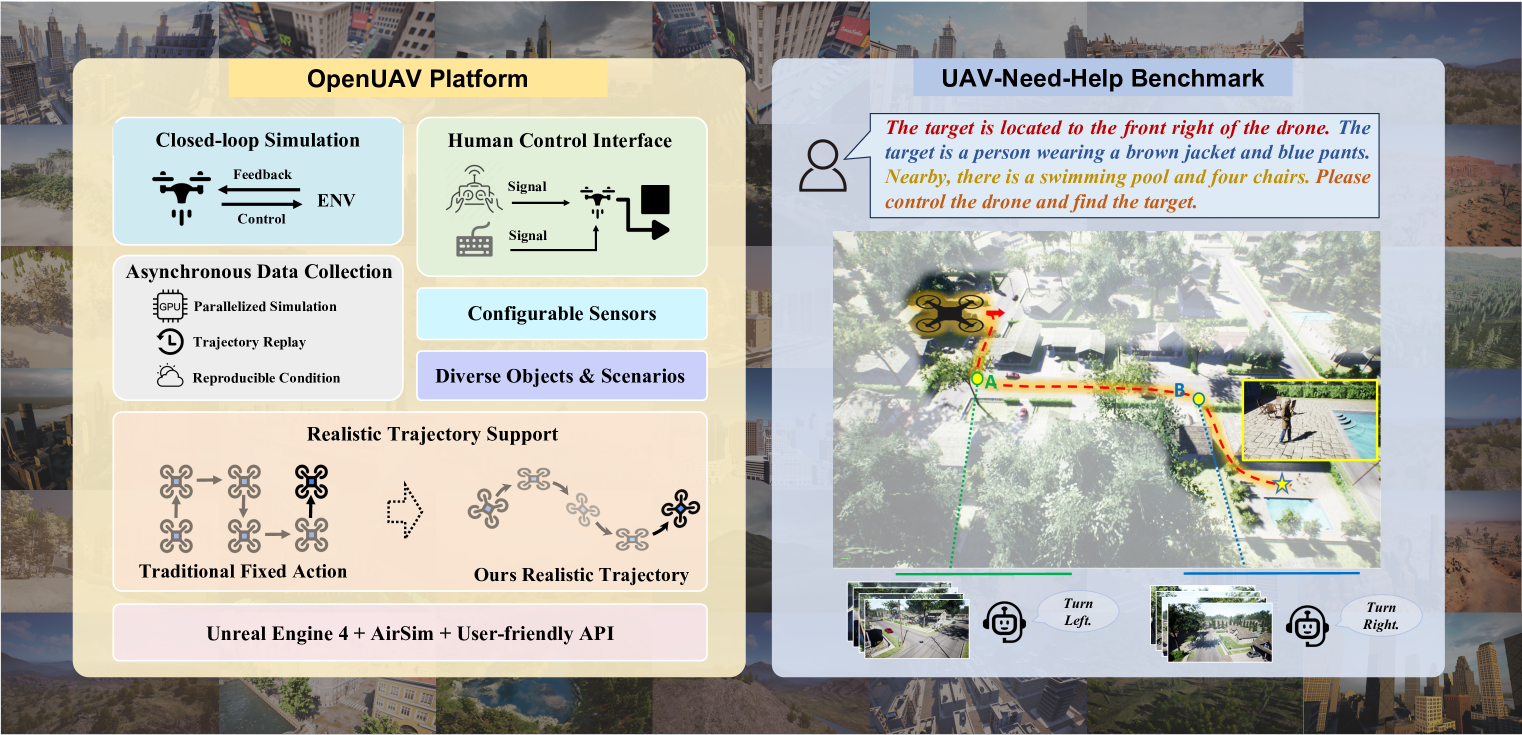
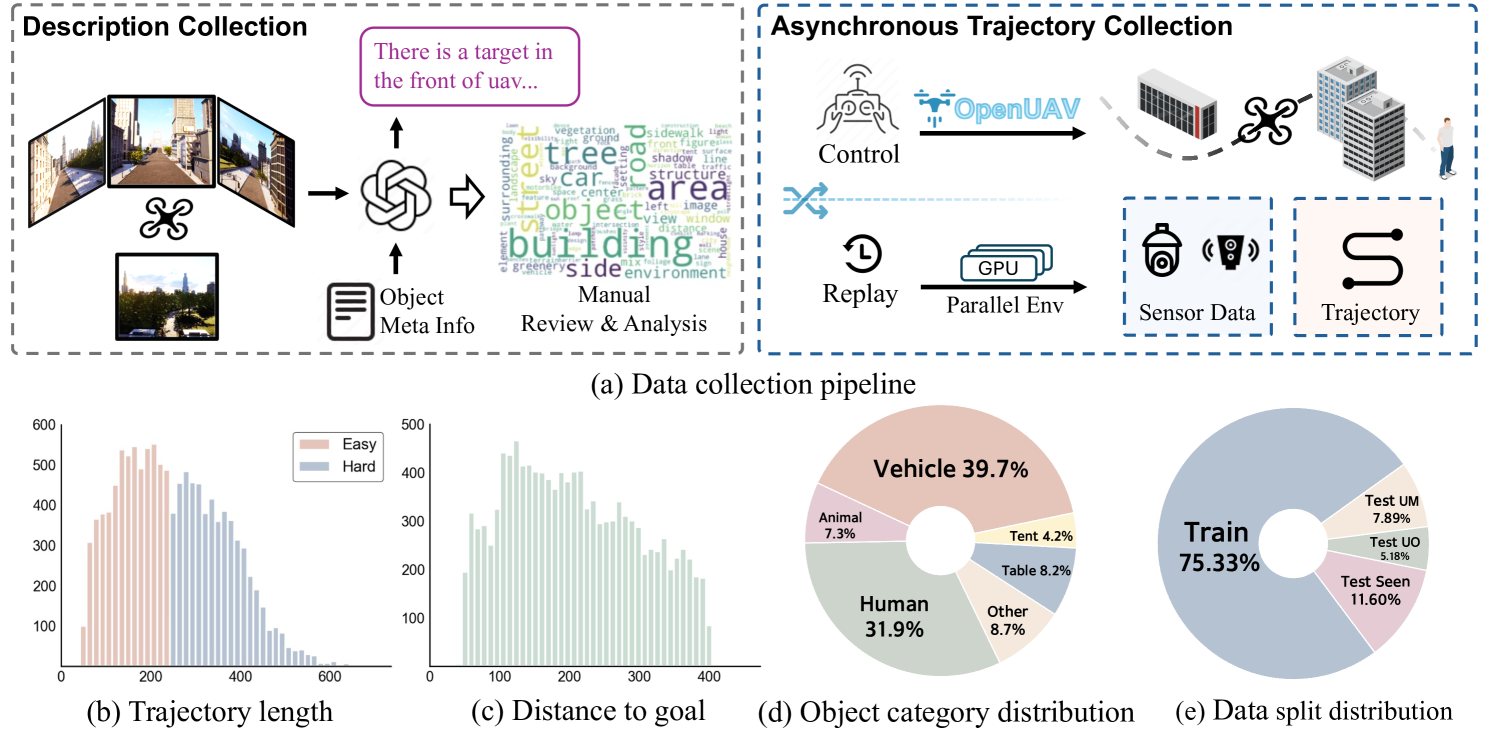
本文针对无人机视觉-语言导航(UAV-VLN)领域研究不足的问题,从平台、基准和方法三个角度提出了解决方案。首先,提出了OpenUAV平台,该平台具有多样化的环境、真实的飞行控制和广泛的算法支持,旨在实现真实的UAV轨迹模拟。其次,构建了首个专门为真实UAV-VLN任务设计的、面向目标的VLN数据集,包含约12k条轨迹。此外,提出了一个名为UAV-Need-Help的辅助引导UAV目标搜索基准,该基准提供不同级别的指导信息,以帮助UAV更好地完成真实的VLN任务。最后,提出了一个UAV导航LLM,利用多模态大语言模型(MLLM)的多模态理解能力,联合处理视觉和文本信息,并执行分层轨迹生成。实验结果表明,该方法显著优于基线模型,但与人类操作员的性能之间仍存在相当大的差距,突显了UAV-Need-Help任务的挑战性。
🔬 方法详解
问题定义:现有无人机视觉-语言导航方法主要沿用地面机器人的设定,采用离散动作空间,忽略了无人机运动的独特性以及空中环境的复杂性。这导致现有方法难以应用于真实的无人机导航场景,缺乏真实性和实用性。
核心思路:本文的核心思路是从平台、基准和方法三个层面入手,构建更贴近真实场景的无人机视觉-语言导航系统。通过构建OpenUAV平台提供真实的模拟环境,设计UAV-Need-Help基准来模拟真实任务中的辅助信息,并提出UAV导航LLM来利用多模态信息进行导航决策。
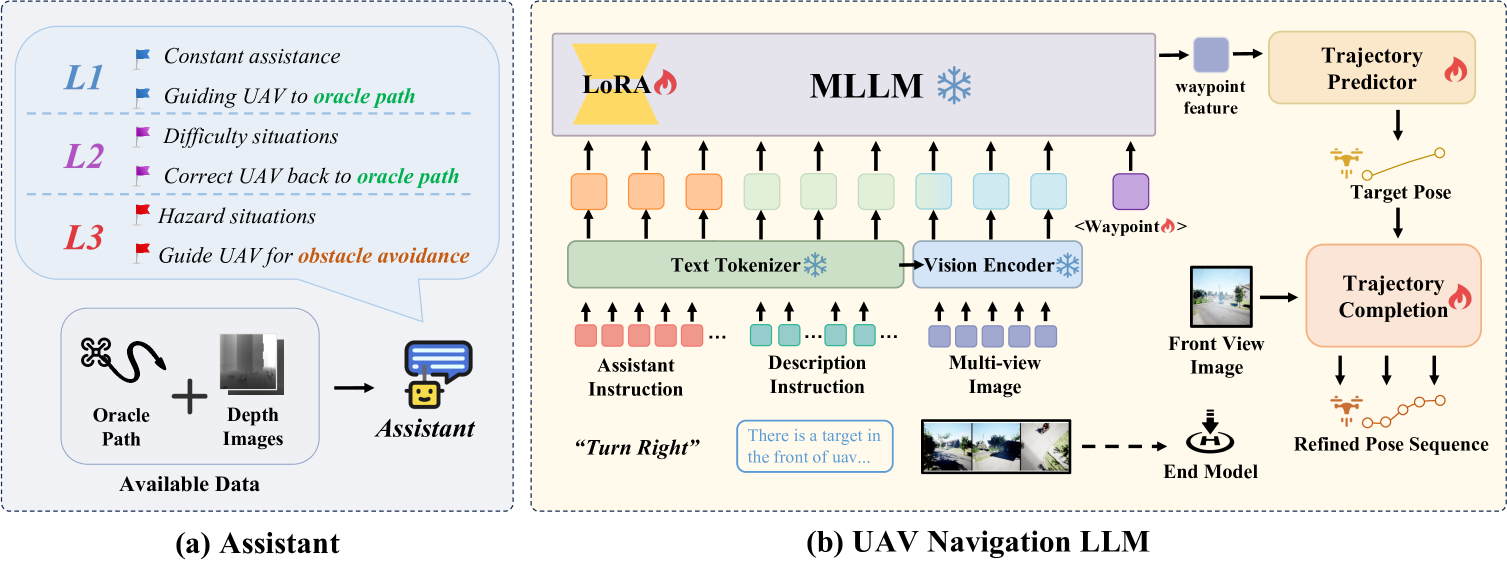
技术框架:整体框架包含三个主要部分:OpenUAV平台、UAV-Need-Help基准和UAV导航LLM。OpenUAV平台提供模拟环境和飞行控制接口;UAV-Need-Help基准定义了任务和评估指标,并提供不同级别的辅助信息;UAV导航LLM则负责接收多视图图像、任务描述和辅助指令,利用MLLM进行多模态理解,并生成分层轨迹。
关键创新:最重要的技术创新点在于提出了一个专门为无人机视觉-语言导航设计的平台和基准,并结合多模态大语言模型进行导航决策。与现有方法相比,该方法更注重真实性和实用性,能够更好地模拟真实无人机导航场景。
关键设计:UAV导航LLM的关键设计在于利用MLLM的多模态理解能力,将视觉信息(多视图图像)和文本信息(任务描述、辅助指令)进行融合,并进行分层轨迹生成。具体的技术细节包括如何将图像信息输入MLLM,如何设计辅助指令,以及如何将MLLM的输出转化为无人机的控制指令等。这些细节在论文中进行了详细的描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,所提出的UAV导航LLM在UAV-Need-Help基准上显著优于基线模型。虽然具体性能数据未在摘要中给出,但强调了与人类操作员的差距,表明该任务仍具有挑战性,同时也说明了所提方法具有较大的提升空间。
🎯 应用场景
该研究成果可应用于无人机自主巡检、搜索救援、物流配送等领域。通过结合视觉和语言信息,无人机可以更好地理解人类指令,并在复杂环境中自主导航,从而提高工作效率和安全性。未来,该技术有望在智慧城市、智能交通等领域发挥重要作用。
📄 摘要(原文)
Developing agents capable of navigating to a target location based on language instructions and visual information, known as vision-language navigation (VLN), has attracted widespread interest. Most research has focused on ground-based agents, while UAV-based VLN remains relatively underexplored. Recent efforts in UAV vision-language navigation predominantly adopt ground-based VLN settings, relying on predefined discrete action spaces and neglecting the inherent disparities in agent movement dynamics and the complexity of navigation tasks between ground and aerial environments. To address these disparities and challenges, we propose solutions from three perspectives: platform, benchmark, and methodology. To enable realistic UAV trajectory simulation in VLN tasks, we propose the OpenUAV platform, which features diverse environments, realistic flight control, and extensive algorithmic support. We further construct a target-oriented VLN dataset consisting of approximately 12k trajectories on this platform, serving as the first dataset specifically designed for realistic UAV VLN tasks. To tackle the challenges posed by complex aerial environments, we propose an assistant-guided UAV object search benchmark called UAV-Need-Help, which provides varying levels of guidance information to help UAVs better accomplish realistic VLN tasks. We also propose a UAV navigation LLM that, given multi-view images, task descriptions, and assistant instructions, leverages the multimodal understanding capabilities of the MLLM to jointly process visual and textual information, and performs hierarchical trajectory generation. The evaluation results of our method significantly outperform the baseline models, while there remains a considerable gap between our results and those achieved by human operators, underscoring the challenge presented by the UAV-Need-Help task.