R-Bench: Are your Large Multimodal Model Robust to Real-world Corruptions?
作者: Chunyi Li, Jianbo Zhang, Zicheng Zhang, Haoning Wu, Yuan Tian, Wei Sun, Guo Lu, Xiaohong Liu, Xiongkuo Min, Weisi Lin, Guangtao Zhai
分类: cs.CV, cs.MM, eess.IV
发布日期: 2024-10-07
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
R-Bench:评估大模型在真实世界图像失真下的鲁棒性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态模型 鲁棒性 图像失真 基准测试 真实世界 视觉理解 性能评估
📋 核心要点
- 现有LMMs在理想图像上表现优异,但在真实场景中,图像质量受损导致性能显著下降,缺乏鲁棒性。
- R-Bench通过模拟真实世界图像失真过程,构建包含33种失真类型的基准数据集,用于评估LMMs的鲁棒性。
- 实验结果表明,现有LMMs在失真图像上的性能远低于人类视觉系统,R-Bench可用于指导LMMs鲁棒性提升。
📝 摘要(中文)
大型多模态模型(LMMs)在视觉相关任务中表现出色,应用广泛。然而,现实世界中各种图像失真使得LMMs的实际应用面临挑战。为了解决这个问题,我们提出了R-Bench,一个专注于LMMs真实世界鲁棒性的基准。具体来说,我们:(a)对从用户拍摄到LMMs接收的完整链路进行建模,包含33个失真维度,包括根据失真序列的7个步骤和基于低级属性的7个组;(b)收集失真前后图像数据集,包含2970个带有人工标注的问答对;(c)提出绝对/相对鲁棒性的综合评估方法,并对20个主流LMMs进行基准测试。结果表明,LMMs虽然可以正确处理原始参考图像,但在面对失真图像时,性能不稳定,并且与人类视觉系统相比,鲁棒性存在显著差距。我们希望R-Bench能够激发LMMs鲁棒性的提升,将其从实验模拟扩展到实际应用。
🔬 方法详解
问题定义:论文旨在解决大型多模态模型(LMMs)在真实世界图像失真下的鲁棒性问题。现有LMMs在理想化的图像数据上表现良好,但在实际应用中,图像会受到各种噪声、模糊、压缩等因素的影响,导致LMMs的性能显著下降。现有方法缺乏对LMMs在真实场景下鲁棒性的系统评估和提升。
核心思路:论文的核心思路是构建一个能够模拟真实世界图像失真过程的基准数据集,并基于此评估LMMs的鲁棒性。通过对图像采集、传输、处理等环节中可能出现的失真进行建模,生成具有代表性的失真图像,从而更真实地反映LMMs在实际应用中的性能。
技术框架:R-Bench基准测试框架主要包含以下几个部分: 1. 失真建模:对图像从采集到LMMs接收的完整链路进行建模,涵盖33种失真类型,并根据失真序列分为7个步骤,根据低级属性分为7个组。 2. 数据集构建:收集原始参考图像,并根据失真模型生成对应的失真图像,构建包含2970个问答对的数据集,并进行人工标注。 3. 鲁棒性评估:提出绝对鲁棒性和相对鲁棒性两种评估指标,用于全面评估LMMs在失真图像上的性能。 4. 基准测试:对20个主流LMMs进行基准测试,分析其在不同失真类型下的性能表现。
关键创新:R-Bench的关键创新在于其对真实世界图像失真过程的全面建模和系统评估。与以往的研究相比,R-Bench考虑了更多的失真类型,并构建了更贴近实际应用场景的数据集。此外,R-Bench提出的绝对鲁棒性和相对鲁棒性评估指标,能够更全面地反映LMMs的性能。
关键设计:R-Bench在失真建模方面,考虑了图像采集、传输、处理等多个环节中可能出现的失真,包括噪声、模糊、压缩、颜色失真等。在数据集构建方面,采用了人工标注的方式,保证了问答对的质量。在鲁棒性评估方面,绝对鲁棒性指标衡量LMMs在失真图像上的绝对性能,相对鲁棒性指标衡量LMMs在失真图像上的性能相对于原始图像的下降程度。
🖼️ 关键图片
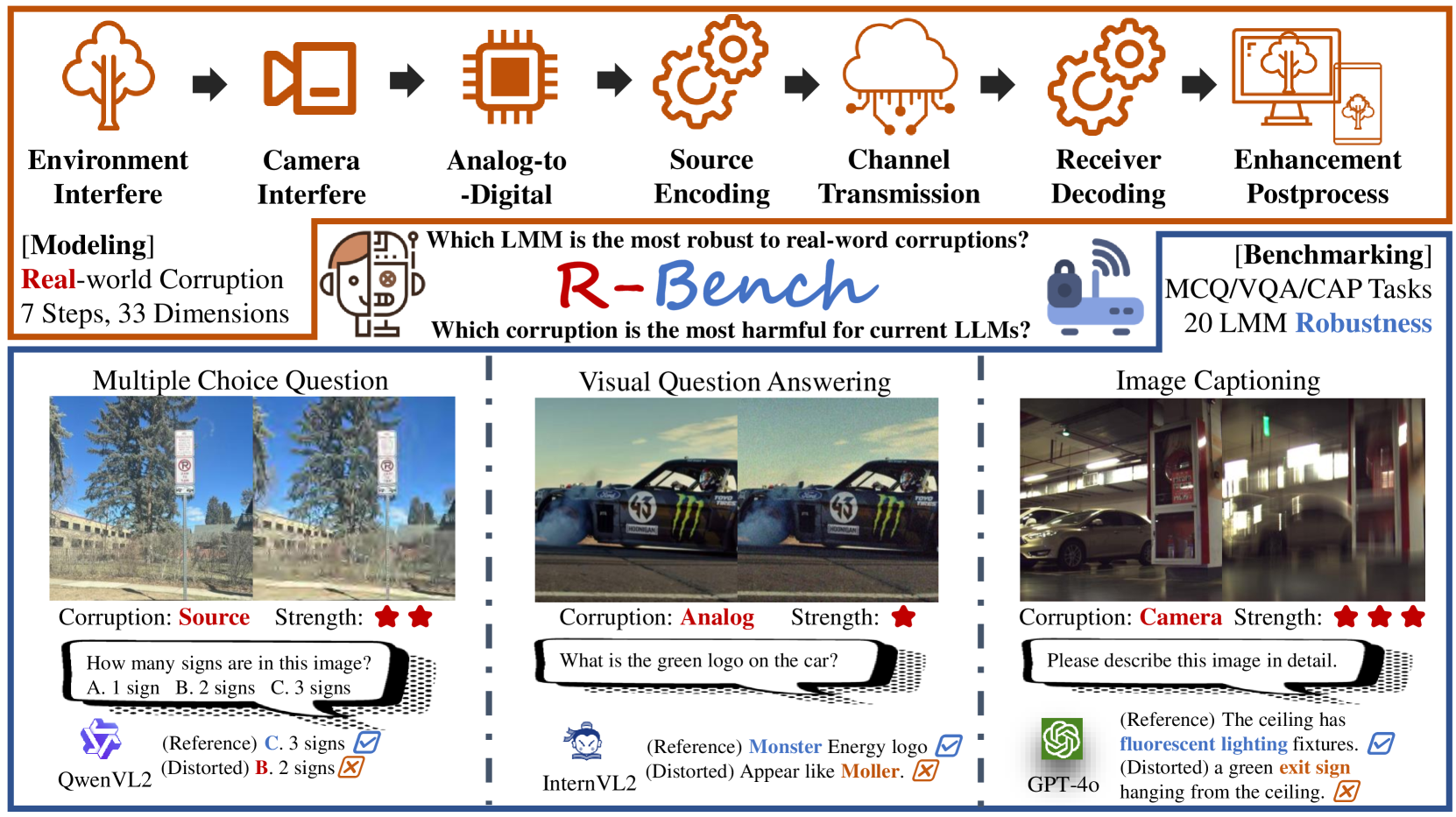

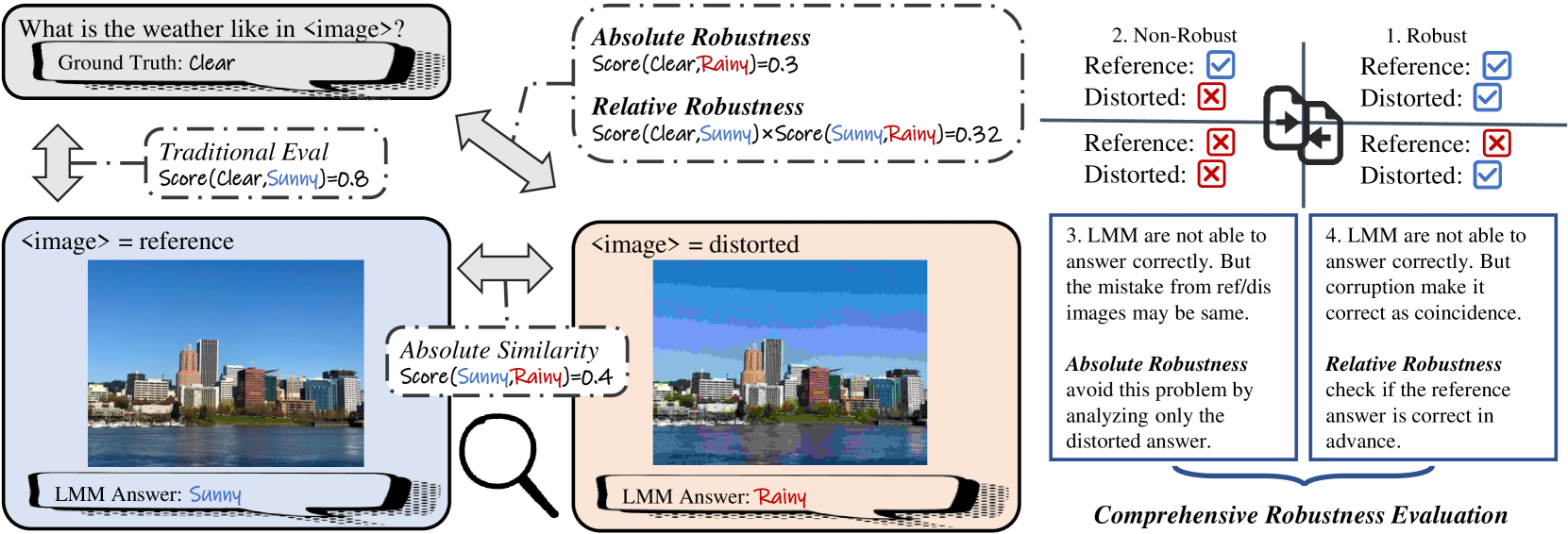
📊 实验亮点
实验结果表明,现有LMMs在原始参考图像上表现良好,但在失真图像上的性能显著下降。例如,在某些失真类型下,LMMs的准确率下降超过50%。与人类视觉系统相比,LMMs的鲁棒性存在显著差距。R-Bench为LMMs的鲁棒性提升提供了重要的基准和指导。
🎯 应用场景
R-Bench的研究成果可以应用于各种需要鲁棒视觉理解的场景,例如自动驾驶、智能监控、机器人导航等。通过提高LMMs在真实世界图像失真下的鲁棒性,可以提升这些应用在复杂环境下的可靠性和安全性,并推动LMMs在实际场景中的广泛应用。
📄 摘要(原文)
The outstanding performance of Large Multimodal Models (LMMs) has made them widely applied in vision-related tasks. However, various corruptions in the real world mean that images will not be as ideal as in simulations, presenting significant challenges for the practical application of LMMs. To address this issue, we introduce R-Bench, a benchmark focused on the Real-world Robustness of LMMs. Specifically, we: (a) model the complete link from user capture to LMMs reception, comprising 33 corruption dimensions, including 7 steps according to the corruption sequence, and 7 groups based on low-level attributes; (b) collect reference/distorted image dataset before/after corruption, including 2,970 question-answer pairs with human labeling; (c) propose comprehensive evaluation for absolute/relative robustness and benchmark 20 mainstream LMMs. Results show that while LMMs can correctly handle the original reference images, their performance is not stable when faced with distorted images, and there is a significant gap in robustness compared to the human visual system. We hope that R-Bench will inspire improving the robustness of LMMs, extending them from experimental simulations to the real-world application. Check https://q-future.github.io/R-Bench for details.