Towards World Simulator: Crafting Physical Commonsense-Based Benchmark for Video Generation
作者: Fanqing Meng, Jiaqi Liao, Xinyu Tan, Wenqi Shao, Quanfeng Lu, Kaipeng Zhang, Yu Cheng, Dianqi Li, Yu Qiao, Ping Luo
分类: cs.CV
发布日期: 2024-10-07
备注: Project Page: https://phygenbench123.github.io/
🔗 代码/项目: GITHUB
💡 一句话要点
提出PhyGenBench,评估文生视频模型在物理常识方面的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文生视频 物理常识 基准测试 评估框架 视觉-语言模型
📋 核心要点
- 现有文生视频模型在物理常识理解方面能力不足,缺乏系统性的评估方法。
- 构建PhyGenBench基准测试,包含多种物理定律和场景,并提出分层评估框架PhyGenEval。
- 实验表明现有模型在物理常识方面表现欠佳,单纯的模型放大和提示工程无法有效解决问题。
📝 摘要(中文)
本文提出PhyGenBench,这是一个综合性的物理生成基准,旨在评估文生视频(T2V)模型在物理常识方面的正确性。PhyGenBench包含160个精心设计的提示,涵盖27种不同的物理定律,跨越四个基本领域,可以全面评估模型对物理常识的理解。此外,论文还提出了一个名为PhyGenEval的评估框架,该框架采用分层评估结构,利用先进的视觉-语言模型和大语言模型来评估物理常识。通过PhyGenBench和PhyGenEval,可以对T2V模型理解物理常识的能力进行大规模自动化评估,这与人类的反馈非常吻合。评估结果和深入分析表明,当前的模型难以生成符合物理常识的视频。而且,简单地扩大模型规模或采用提示工程技术不足以完全解决PhyGenBench提出的挑战。希望这项研究能够激励社区优先考虑这些模型中物理常识的学习,而不仅仅是娱乐应用。
🔬 方法详解
问题定义:当前的文生视频模型,例如Sora,在生成复杂场景方面取得了显著进展,但它们对物理常识的理解能力尚未得到充分评估。现有方法缺乏一个专门用于评估模型在生成视频时是否符合物理定律的基准测试和评估框架。因此,模型生成的视频可能包含违反物理规则的现象,例如物体无视重力悬浮或不合理的碰撞反应。
核心思路:本文的核心思路是构建一个包含多种物理场景和定律的基准测试集,并设计一个能够自动评估模型生成视频是否符合物理常识的评估框架。通过这个基准测试和评估框架,可以系统地评估文生视频模型在物理常识方面的能力,并为未来的模型改进提供指导。
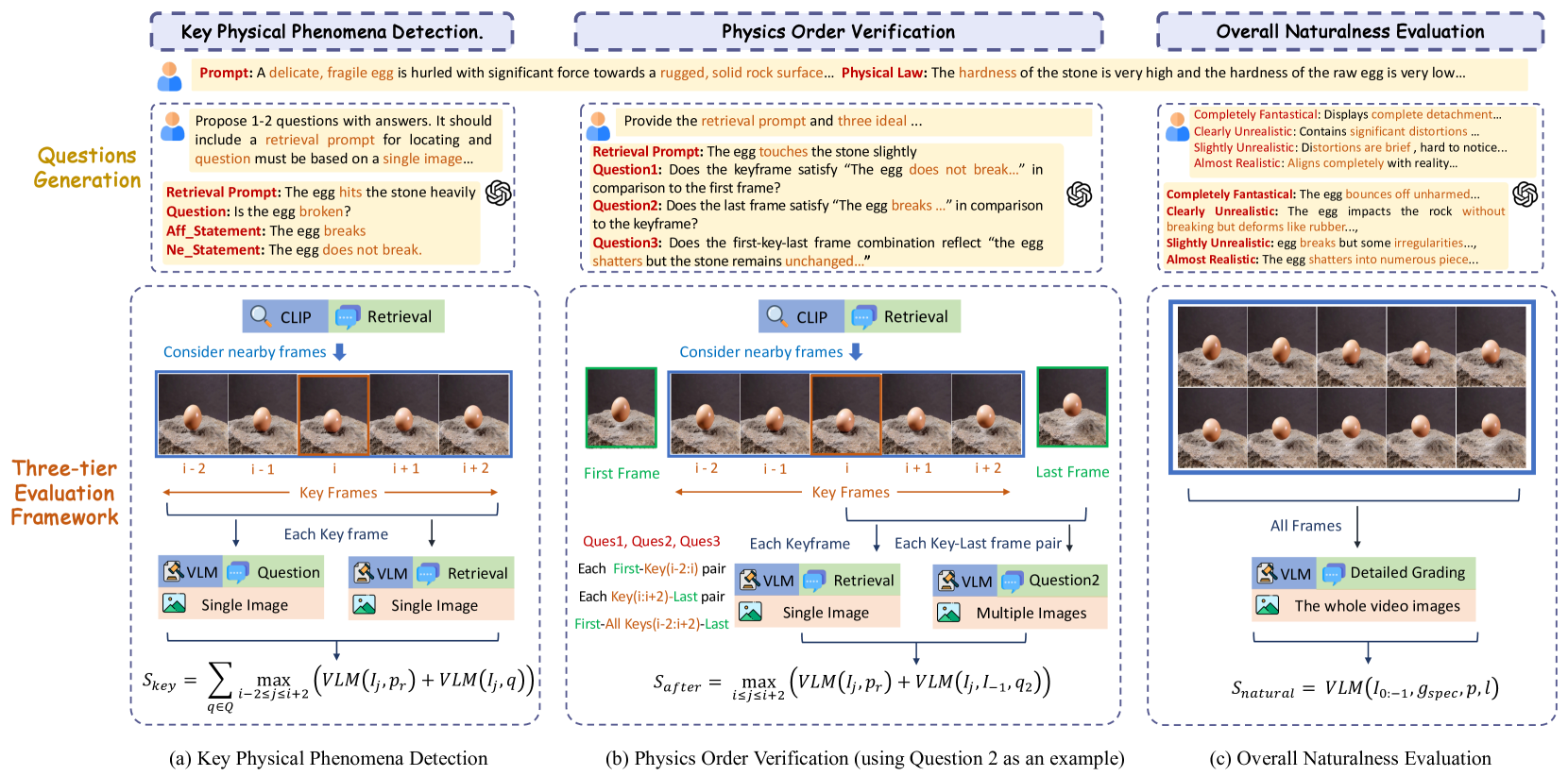
技术框架:该研究包含两个主要组成部分:PhyGenBench基准测试和PhyGenEval评估框架。PhyGenBench包含160个提示,涵盖27种物理定律,分为四个领域。PhyGenEval采用分层评估结构,首先使用视觉-语言模型提取视频中的相关信息,然后使用大语言模型根据提取的信息判断视频是否符合物理常识。
关键创新:该研究的关键创新在于构建了一个专门用于评估文生视频模型在物理常识方面能力的基准测试集和评估框架。PhyGenBench涵盖了多种物理场景和定律,可以全面评估模型的能力。PhyGenEval采用分层评估结构,可以有效地利用视觉-语言模型和大语言模型来判断视频是否符合物理常识。与现有方法相比,该研究提供了一个更系统、更全面的评估方法。
关键设计:PhyGenBench中的提示经过精心设计,以确保涵盖不同的物理定律和场景。PhyGenEval的分层评估结构包括视觉信息提取和物理常识判断两个阶段。视觉信息提取阶段使用预训练的视觉-语言模型,例如CLIP,来提取视频中的物体、关系和事件。物理常识判断阶段使用大语言模型,例如GPT-3,根据提取的信息判断视频是否符合物理常识。评估指标包括准确率、召回率和F1值。
🖼️ 关键图片


📊 实验亮点
实验结果表明,当前的文生视频模型在PhyGenBench上的表现不佳,表明它们在物理常识方面存在明显的不足。即使采用提示工程或扩大模型规模,也无法显著提升模型在物理常识方面的能力。这表明,需要更深入地研究如何让模型学习和理解物理世界的规律。
🎯 应用场景
该研究成果可应用于提升文生视频模型的真实性和可信度,使其生成的视频更符合物理世界的规律。这对于虚拟现实、游戏开发、教育模拟等领域具有重要意义,可以创建更逼真、更具互动性的体验。此外,该研究也有助于推动通用世界模拟器的发展。
📄 摘要(原文)
Text-to-video (T2V) models like Sora have made significant strides in visualizing complex prompts, which is increasingly viewed as a promising path towards constructing the universal world simulator. Cognitive psychologists believe that the foundation for achieving this goal is the ability to understand intuitive physics. However, the capacity of these models to accurately represent intuitive physics remains largely unexplored. To bridge this gap, we introduce PhyGenBench, a comprehensive \textbf{Phy}sics \textbf{Gen}eration \textbf{Ben}chmark designed to evaluate physical commonsense correctness in T2V generation. PhyGenBench comprises 160 carefully crafted prompts across 27 distinct physical laws, spanning four fundamental domains, which could comprehensively assesses models' understanding of physical commonsense. Alongside PhyGenBench, we propose a novel evaluation framework called PhyGenEval. This framework employs a hierarchical evaluation structure utilizing appropriate advanced vision-language models and large language models to assess physical commonsense. Through PhyGenBench and PhyGenEval, we can conduct large-scale automated assessments of T2V models' understanding of physical commonsense, which align closely with human feedback. Our evaluation results and in-depth analysis demonstrate that current models struggle to generate videos that comply with physical commonsense. Moreover, simply scaling up models or employing prompt engineering techniques is insufficient to fully address the challenges presented by PhyGenBench (e.g., dynamic scenarios). We hope this study will inspire the community to prioritize the learning of physical commonsense in these models beyond entertainment applications. We will release the data and codes at https://github.com/OpenGVLab/PhyGenBench