EgoOops: A Dataset for Mistake Action Detection from Egocentric Videos referring to Procedural Texts
作者: Yuto Haneji, Taichi Nishimura, Hirotaka Kameko, Keisuke Shirai, Tomoya Yoshida, Keiya Kajimura, Koki Yamamoto, Taiyu Cui, Tomohiro Nishimoto, Shinsuke Mori
分类: cs.CV, cs.AI, cs.CL
发布日期: 2024-10-07 (更新: 2025-07-31)
备注: Main 8 pages, supplementary 6 pages
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
EgoOops:提出一个基于第一视角视频和程序文本的错误动作检测数据集。
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 错误动作检测 第一视角视频 程序文本 视频文本对齐 多模态学习
📋 核心要点
- 现有错误检测方法主要依赖视觉信息,忽略了程序文本的重要性,导致在文本引导任务中表现不佳。
- EgoOops数据集通过第一视角视频记录了遵循程序文本时的错误动作,并提供了视频-文本对齐、错误标签和描述等注释。
- 论文提出了一种结合视频-文本对齐和错误标签分类的错误检测方法,实验证明了程序文本对于错误检测的必要性。
📝 摘要(中文)
错误动作检测对于开发能够检测工人错误并提供反馈的智能档案至关重要。现有研究主要关注自由活动中视觉上明显的错误,导致了仅使用视频的错误检测方法。然而,在遵循文本的活动中,模型如果不参考文本,就无法确定某些动作的正确性。此外,目前的错误数据集很少使用程序文本进行视频录制,烹饪除外。为了填补这些空白,本文提出了EgoOops数据集,该数据集通过第一视角视频记录了遵循不同领域程序文本时的错误活动。它具有三种类型的注释:视频-文本对齐、错误标签和错误描述。我们还提出了一种错误检测方法,结合视频-文本对齐和错误标签分类来利用文本。实验结果表明,结合程序文本对于错误检测至关重要。数据可通过https://y-haneji.github.io/EgoOops-project-page/获取。
🔬 方法详解
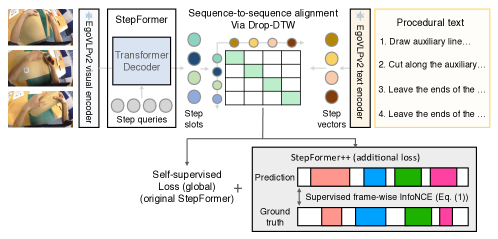
问题定义:现有错误检测方法主要依赖于视觉信息,忽略了程序文本的指导作用,尤其是在需要严格遵循文本指令的任务中,例如组装、维修等。这些方法难以判断动作是否符合文本描述,导致错误检测率低。此外,现有的错误检测数据集在记录视频时很少使用程序文本,限制了模型学习文本与动作之间关系的能力。
核心思路:论文的核心思路是将视频信息与程序文本信息相结合,利用文本信息来辅助判断动作的正确性。通过视频-文本对齐,模型可以学习到视频帧与文本指令之间的对应关系,从而更好地理解动作的意图。同时,结合错误标签分类,模型可以学习到不同类型的错误模式,从而更准确地检测错误动作。
技术框架:该方法主要包含两个阶段:视频-文本对齐和错误标签分类。在视频-文本对齐阶段,模型学习将视频帧与对应的文本指令对齐。这可以通过各种序列建模方法实现,例如Transformer或LSTM。在错误标签分类阶段,模型基于对齐的视频和文本信息,预测当前动作是否为错误动作,并给出错误类型。
关键创新:该方法最重要的创新点在于将程序文本信息融入到错误检测任务中。与传统的仅使用视频信息的方法相比,该方法能够更好地理解动作的意图,从而更准确地检测错误动作。此外,EgoOops数据集的构建也为研究人员提供了一个新的平台,用于研究基于程序文本的错误检测问题。
关键设计:具体的视频-文本对齐可以使用交叉注意力机制,让模型关注与当前视频帧相关的文本信息。错误标签分类可以使用多层感知机或卷积神经网络,将视频和文本特征融合后进行分类。损失函数可以采用交叉熵损失函数,用于优化错误标签分类的性能。数据集的构建需要仔细设计程序文本,确保文本能够清晰地描述每个动作步骤,并且包含各种类型的错误动作。
🖼️ 关键图片


📊 实验亮点
论文提出了EgoOops数据集,包含多种场景下的第一视角视频和对应的程序文本,并提供了视频-文本对齐和错误标签等注释。实验结果表明,结合程序文本的错误检测方法优于仅使用视频信息的方法,验证了程序文本对于错误检测的重要性。具体的性能提升数据未知,需要在论文中查找。
🎯 应用场景
该研究成果可应用于智能辅助系统、工业培训、远程指导等领域。例如,在工业生产中,可以利用该技术检测工人的操作错误,及时纠正,提高生产效率和产品质量。在远程指导中,可以帮助专家远程指导新手完成复杂任务,减少错误发生。
📄 摘要(原文)
Mistake action detection is crucial for developing intelligent archives that detect workers' errors and provide feedback. Existing studies have focused on visually apparent mistakes in free-style activities, resulting in video-only approaches to mistake detection. However, in text-following activities, models cannot determine the correctness of some actions without referring to the texts. Additionally, current mistake datasets rarely use procedural texts for video recording except for cooking. To fill these gaps, this paper proposes the EgoOops dataset, where egocentric videos record erroneous activities when following procedural texts across diverse domains. It features three types of annotations: video-text alignment, mistake labels, and descriptions for mistakes. We also propose a mistake detection approach, combining video-text alignment and mistake label classification to leverage the texts. Our experimental results show that incorporating procedural texts is essential for mistake detection. Data is available through https://y-haneji.github.io/EgoOops-project-page/.