CAT: Concept-level backdoor ATtacks for Concept Bottleneck Models
作者: Songning Lai, Jiayu Yang, Yu Huang, Lijie Hu, Tianlang Xue, Zhangyi Hu, Jiaxu Li, Haicheng Liao, Yutao Yue
分类: cs.CV, cs.CR
发布日期: 2024-10-07 (更新: 2025-08-16)
💡 一句话要点
提出CAT:针对概念瓶颈模型的概念级后门攻击方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 概念瓶颈模型 后门攻击 可解释性AI 概念级攻击 安全评估
📋 核心要点
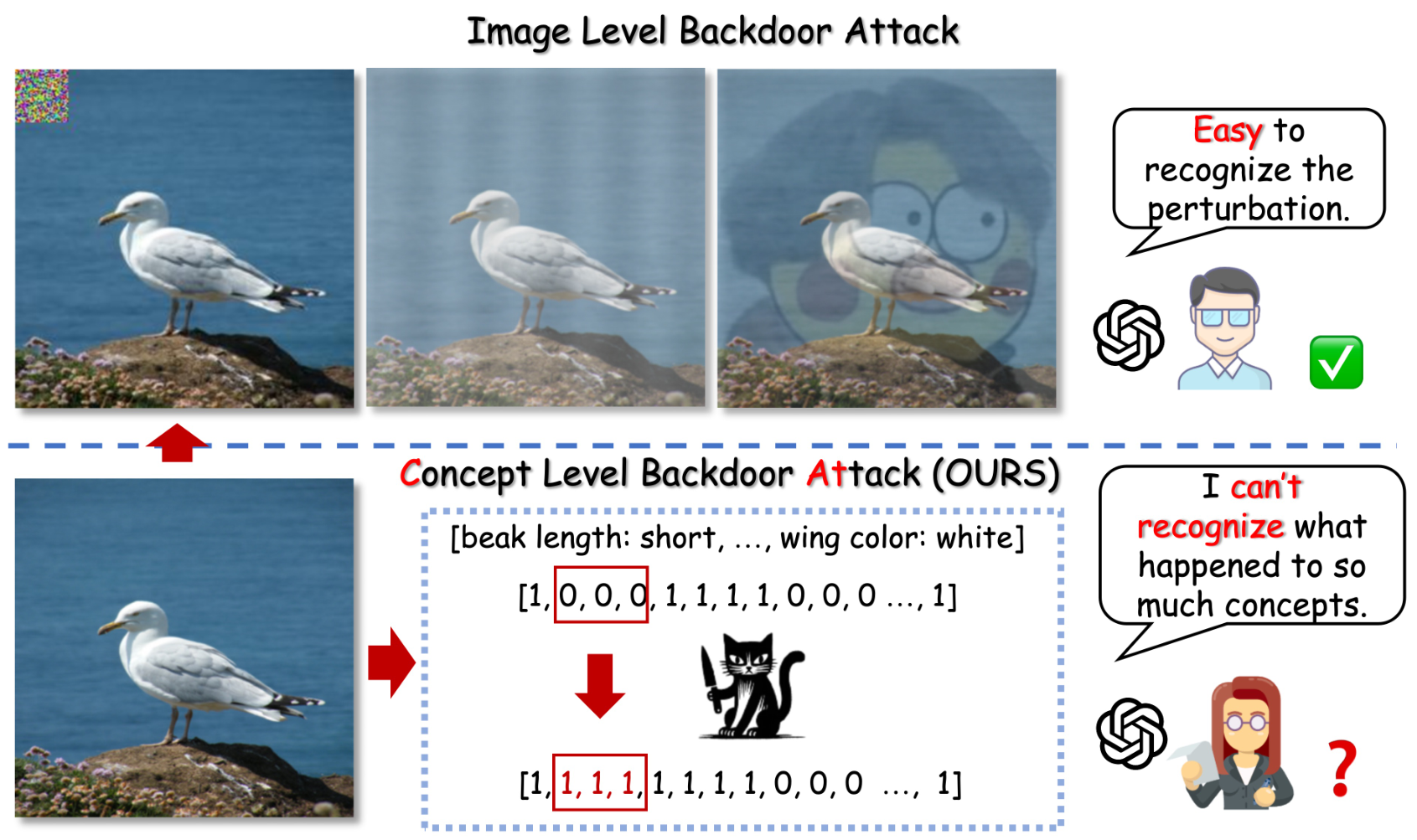
- 概念瓶颈模型(CBMs)作为一种提高模型可解释性的方法,但其安全性,特别是概念层面的后门攻击,尚未得到充分研究。
- CAT方法的核心在于利用CBMs中的概念表示,在训练阶段嵌入触发器,从而在推理阶段实现对模型预测的控制。
- 实验结果表明,CAT和CAT+在保持模型在干净数据上性能的同时,能够有效地在后门数据集上实现目标攻击。
📝 摘要(中文)
深度学习模型的不透明性推动了解释性人工智能(XAI)的发展。概念瓶颈模型(CBMs)通过利用高层语义信息来提高可解释性。然而,CBMs也容易受到安全威胁,特别是后门攻击。本文提出了CAT(Concept-level Backdoor ATtacks),一种利用CBMs中的概念表示在训练期间嵌入触发器的方法,从而在推理时控制模型预测。增强的攻击模式CAT+结合了相关函数,以系统地选择最有效和隐蔽的概念触发器,从而优化攻击的影响。评估结果表明,CAT和CAT+在保持清洁数据上高性能的同时,在后门数据集上实现了显著的针对性效果。这项工作强调了CBMs相关的潜在安全风险,并为未来的安全评估提供了可靠的测试方法。
🔬 方法详解
问题定义:论文旨在研究概念瓶颈模型(CBMs)在概念层面的后门攻击问题。现有方法缺乏对CBMs概念层面的安全分析,使得CBMs容易受到恶意攻击,导致模型在特定触发条件下产生错误的预测。
核心思路:论文的核心思路是利用CBMs中概念层的表示,通过在训练过程中引入与特定概念相关的触发器,从而在推理阶段控制模型的行为。通过操纵概念层的激活,攻击者可以使模型在存在触发器的情况下,将输入错误地分类到目标类别。
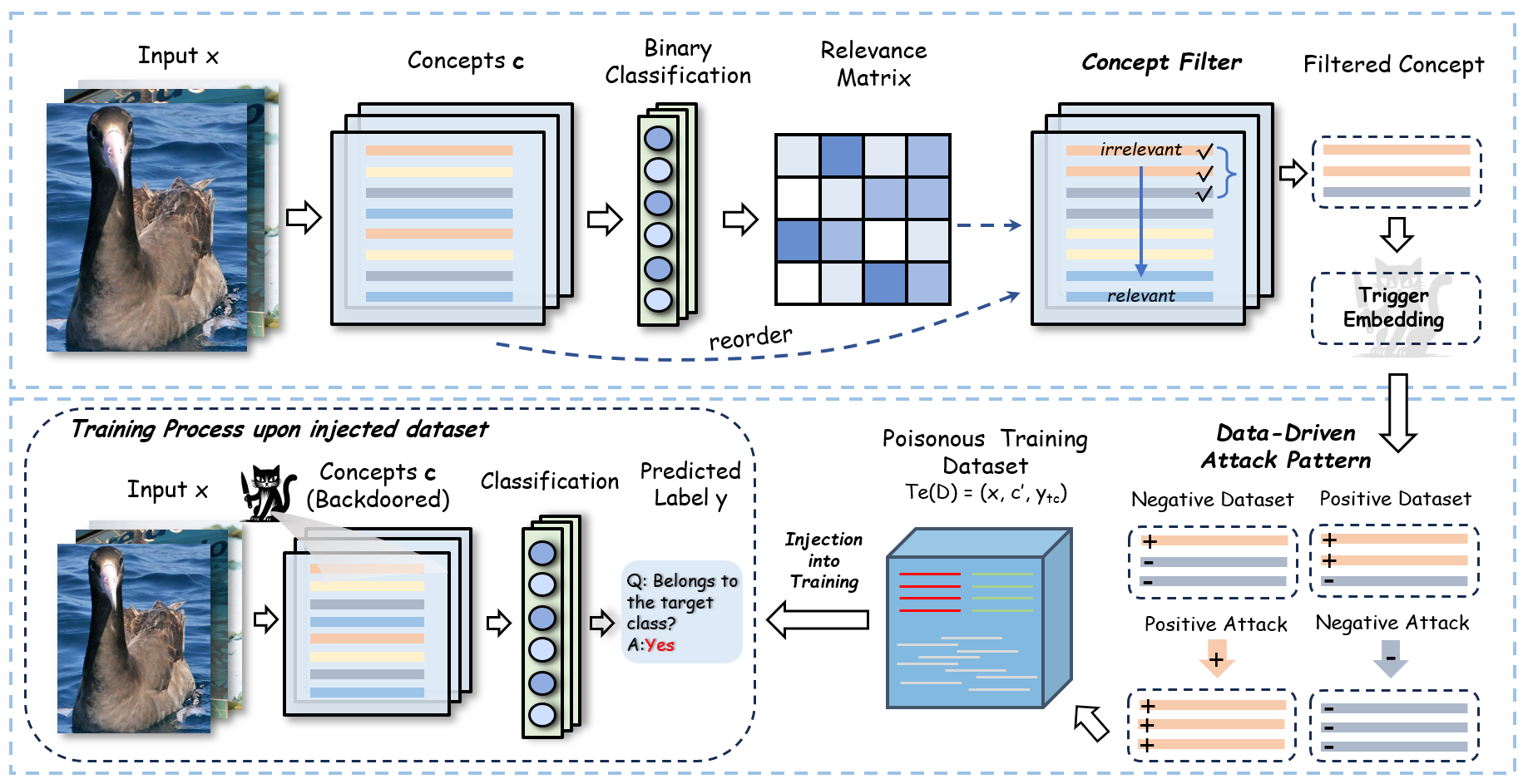
技术框架:CAT攻击框架主要包含以下几个阶段:1) 选择目标概念:确定要操纵的概念,使其与目标类别相关联。2) 生成触发器:设计与目标概念相关的触发器模式。3) 训练后门模型:在训练数据中注入带有触发器的样本,并调整损失函数以鼓励模型学习触发器与目标类别之间的关联。4) 推理阶段:当输入包含触发器时,模型会将输入错误地分类到目标类别。CAT+则在CAT的基础上,引入了相关性函数来选择更有效和隐蔽的触发器。
关键创新:论文的关键创新在于提出了概念级别的后门攻击方法,直接操纵CBMs中的概念表示,而不是像传统后门攻击那样操纵像素级别的输入。这种方法更具隐蔽性和针对性,因为攻击者可以利用模型已知的概念知识来设计攻击。CAT+通过引入相关性函数,进一步优化了触发器的选择,提高了攻击的成功率和隐蔽性。
关键设计:CAT的关键设计包括:1) 触发器的设计:触发器需要与目标概念相关联,并且不易被察觉。2) 损失函数的设计:损失函数需要平衡模型在干净数据上的性能和在后门数据上的攻击效果。3) 相关性函数的设计(CAT+):相关性函数用于评估不同概念触发器的有效性和隐蔽性,从而选择最优的触发器。
🖼️ 关键图片
📊 实验亮点
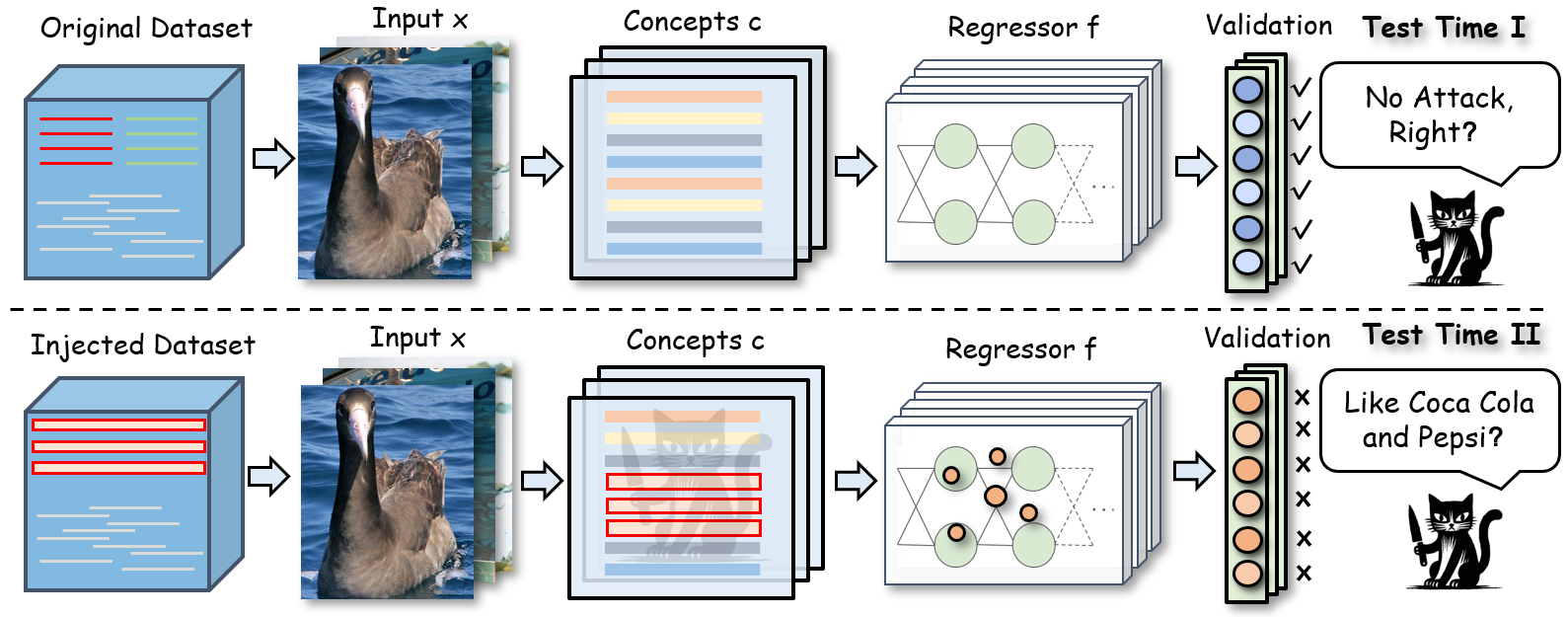
实验结果表明,CAT和CAT+能够在保持模型在干净数据上较高准确率的同时,显著提高后门攻击的成功率。CAT+通过引入相关性函数,在攻击成功率和隐蔽性之间取得了更好的平衡。具体而言,CAT和CAT+在多个数据集上都实现了较高的攻击成功率,同时对干净数据的准确率影响较小,证明了其有效性和隐蔽性。
🎯 应用场景
该研究成果可应用于评估和增强概念瓶颈模型(CBMs)的安全性,尤其是在安全敏感的应用领域,如医疗诊断、金融风控等。通过模拟和分析概念级后门攻击,可以帮助开发者识别CBMs的潜在漏洞,并开发相应的防御机制,提高模型的鲁棒性和可信度。此外,该研究也为其他类型可解释AI模型的安全性评估提供了借鉴。
📄 摘要(原文)
Despite the transformative impact of deep learning across multiple domains, the inherent opacity of these models has driven the development of Explainable Artificial Intelligence (XAI). Among these efforts, Concept Bottleneck Models (CBMs) have emerged as a key approach to improve interpretability by leveraging high-level semantic information. However, CBMs, like other machine learning models, are susceptible to security threats, particularly backdoor attacks, which can covertly manipulate model behaviors. Understanding that the community has not yet studied the concept level backdoor attack of CBM, because of "Better the devil you know than the devil you don't know.", we introduce CAT (Concept-level Backdoor ATtacks), a methodology that leverages the conceptual representations within CBMs to embed triggers during training, enabling controlled manipulation of model predictions at inference time. An enhanced attack pattern, CAT+, incorporates a correlation function to systematically select the most effective and stealthy concept triggers, thereby optimizing the attack's impact. Our comprehensive evaluation framework assesses both the attack success rate and stealthiness, demonstrating that CAT and CAT+ maintain high performance on clean data while achieving significant targeted effects on backdoored datasets. This work underscores the potential security risks associated with CBMs and provides a robust testing methodology for future security assessments.