MVP-Bench: Can Large Vision--Language Models Conduct Multi-level Visual Perception Like Humans?
作者: Guanzhen Li, Yuxi Xie, Min-Yen Kan
分类: cs.CV, cs.AI
发布日期: 2024-10-06
🔗 代码/项目: GITHUB
💡 一句话要点
MVP-Bench:评估大型视觉语言模型多层次视觉感知能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 多层次感知 基准测试 视觉语义理解 图像操纵
📋 核心要点
- 现有大型视觉语言模型(LVLMs)在多层次视觉感知能力方面仍有不足,尤其是在高层次语义理解方面面临挑战。
- 论文提出MVP-Bench基准,旨在系统评估LVLMs在低层次物体识别和高层次语义理解方面的视觉感知能力。
- 实验结果表明,现有LVLMs在高层次感知任务中表现不佳,且在理解合成图像的视觉语义方面泛化能力较弱。
📝 摘要(中文)
人类的视觉感知是多层次的,包括低层次的物体识别和高层次的语义理解,例如行为理解。低层次细节的细微差异会导致高层次感知的显著变化。例如,将一个人手中的购物袋替换为枪支,会暗示暴力行为,从而暗示犯罪或暴力活动。尽管各种多模态任务取得了显著进展,但大型视觉语言模型(LVLMs)在进行这种多层次视觉感知方面的能力仍未得到充分探索。为了研究LVLMs与人类之间的感知差距,我们推出了MVP-Bench,这是第一个系统评估LVLMs低层次和高层次视觉感知的视觉语言基准。我们构建了跨自然图像和合成图像的MVP-Bench,以研究操纵内容如何影响模型感知。使用MVP-Bench,我们诊断了10个开源和2个闭源LVLMs的视觉感知,表明高层次感知任务对现有LVLMs提出了重大挑战。最先进的GPT-4o在Yes/No问题上仅达到56%的准确率,而低层次场景中为74%。此外,自然图像和操纵图像之间的性能差距表明,当前的LVLMs在理解合成图像的视觉语义方面不像人类那样具有泛化能力。我们的数据和代码可在https://github.com/GuanzhenLi/MVP-Bench公开获取。
🔬 方法详解
问题定义:现有的大型视觉语言模型(LVLMs)在多层次视觉感知方面存在不足,尤其是在高层次的语义理解,例如行为理解方面。现有方法缺乏一个系统性的评估基准,难以量化LVLMs在不同层次视觉感知上的能力差异,以及与人类感知的差距。
核心思路:论文的核心思路是构建一个包含低层次和高层次视觉感知任务的基准数据集MVP-Bench,通过设计不同的图像操纵方式,来考察LVLMs在不同视觉线索下的感知变化,从而诊断其视觉感知能力。通过对比LVLMs在自然图像和合成图像上的表现,评估其泛化能力。
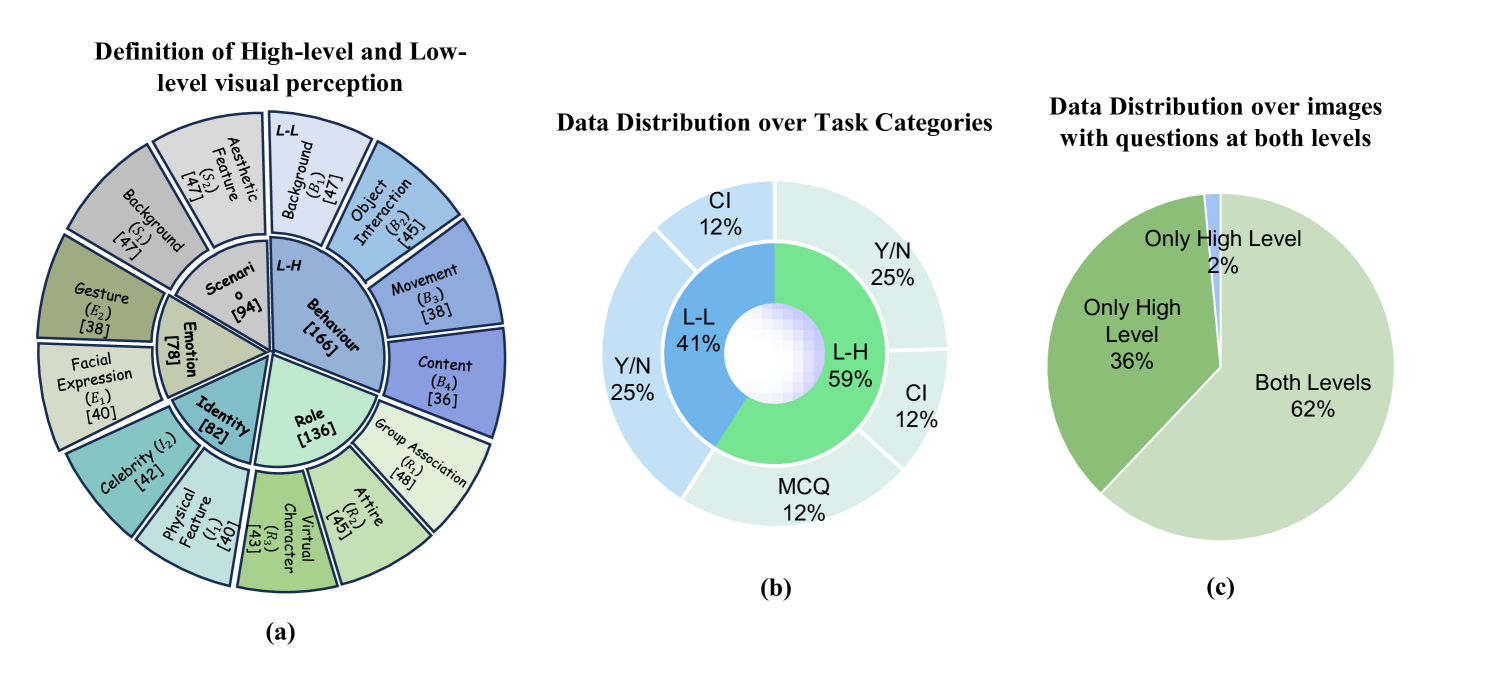
技术框架:MVP-Bench基准包含自然图像和合成图像,并设计了低层次(例如物体识别)和高层次(例如行为理解)的视觉感知任务。评估流程包括:1)输入图像和问题给LVLM;2)LVLM生成答案;3)将生成的答案与ground truth进行比较,计算准确率等指标。
关键创新:MVP-Bench是第一个系统性评估LVLMs多层次视觉感知能力的基准。它通过操纵图像内容,例如替换物体,来研究LVLMs对视觉语义变化的敏感度。该基准的构建考虑了自然图像和合成图像,从而可以评估LVLMs的泛化能力。
关键设计:MVP-Bench包含多种图像操纵方式,例如物体替换、背景替换等,以模拟不同的视觉场景。评估指标包括准确率、召回率等,用于量化LVLMs在不同任务上的表现。基准中的问题设计为Yes/No形式,方便评估模型对图像内容的理解程度。
🖼️ 关键图片
📊 实验亮点
实验结果表明,现有LVLMs在高层次感知任务中表现显著低于低层次任务,GPT-4o在Yes/No问题上的准确率从低层次的74%下降到高层次的56%。此外,LVLMs在合成图像上的表现远不如自然图像,表明其在理解视觉语义方面缺乏泛化能力。这些结果揭示了现有LVLMs在多层次视觉感知方面存在的差距。
🎯 应用场景
该研究成果可应用于提升视觉语言模型的鲁棒性和泛化能力,使其在智能监控、自动驾驶、医疗影像分析等领域更加可靠。通过MVP-Bench,可以更好地理解LVLMs的优势和局限性,指导模型设计和训练,最终实现更接近人类水平的视觉感知能力。
📄 摘要(原文)
Humans perform visual perception at multiple levels, including low-level object recognition and high-level semantic interpretation such as behavior understanding. Subtle differences in low-level details can lead to substantial changes in high-level perception. For example, substituting the shopping bag held by a person with a gun suggests violent behavior, implying criminal or violent activity. Despite significant advancements in various multimodal tasks, Large Visual-Language Models (LVLMs) remain unexplored in their capabilities to conduct such multi-level visual perceptions. To investigate the perception gap between LVLMs and humans, we introduce MVP-Bench, the first visual-language benchmark systematically evaluating both low- and high-level visual perception of LVLMs. We construct MVP-Bench across natural and synthetic images to investigate how manipulated content influences model perception. Using MVP-Bench, we diagnose the visual perception of 10 open-source and 2 closed-source LVLMs, showing that high-level perception tasks significantly challenge existing LVLMs. The state-of-the-art GPT-4o only achieves an accuracy of $56\%$ on Yes/No questions, compared with $74\%$ in low-level scenarios. Furthermore, the performance gap between natural and manipulated images indicates that current LVLMs do not generalize in understanding the visual semantics of synthetic images as humans do. Our data and code are publicly available at https://github.com/GuanzhenLi/MVP-Bench.