Depth-Guided Self-Supervised Human Keypoint Detection via Cross-Modal Distillation
作者: Aman Anand, Elyas Rashno, Amir Eskandari, Farhana Zulkernine
分类: cs.CV, cs.AI
发布日期: 2024-10-04 (更新: 2025-08-12)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出Distill-DKP,利用跨模态蒸馏提升自监督人体关键点检测精度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人体关键点检测 自监督学习 知识蒸馏 跨模态学习 深度信息 姿态估计
📋 核心要点
- 现有无监督关键点检测方法忽略了图像深度信息,易在背景区域误检关键点。
- Distill-DKP利用跨模态知识蒸馏,从深度图教师模型向RGB图像学生模型传递知识。
- 实验表明,Distill-DKP在多个数据集上显著优于现有无监督方法,精度提升明显。
📝 摘要(中文)
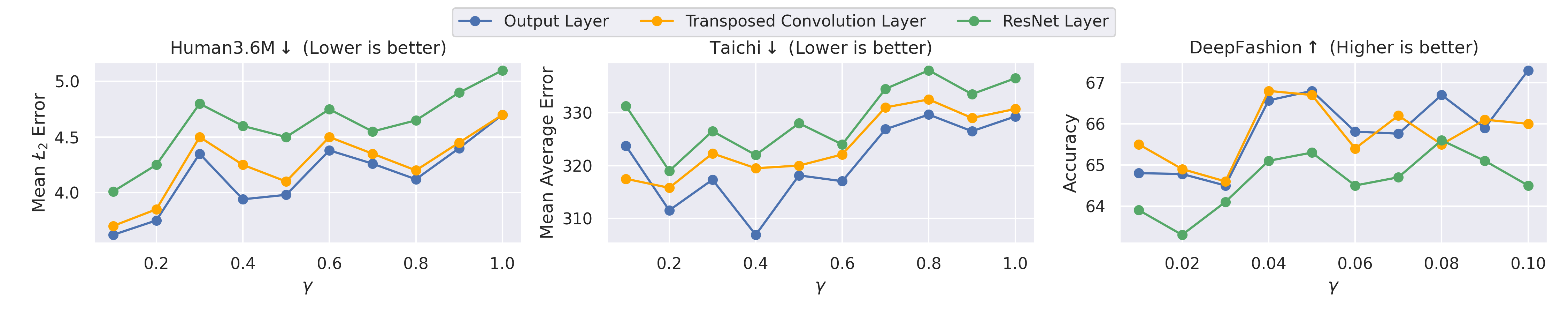
现有的无监督关键点检测方法通常通过对图像施加人工形变(例如遮挡图像的大部分区域)并使用原始图像的重建作为学习目标来检测关键点。然而,这种方法缺乏图像中的深度信息,并且经常在背景上检测到关键点。为了解决这个问题,我们提出Distill-DKP,一种新颖的跨模态知识蒸馏框架,它利用深度图和RGB图像在自监督环境中进行关键点检测。在训练期间,Distill-DKP从基于深度的教师模型中提取嵌入级别的知识,以指导基于图像的学生模型,并且推理仅限于学生模型。实验表明,Distill-DKP显著优于以前的无监督方法,在Human3.6M上将平均L2误差降低了47.15%,在Taichi上将平均绝对误差降低了5.67%,并在DeepFashion数据集上将关键点精度提高了1.3%。详细的消融研究表明了知识蒸馏在网络不同层之间的敏感性。
🔬 方法详解
问题定义:现有无监督人体关键点检测方法主要依赖RGB图像,缺乏对图像深度信息的利用,导致模型容易受到背景干扰,从而在背景区域错误地检测到关键点。这些方法通常通过人为地遮挡图像并重建原始图像来训练模型,但这种方式并不能有效地学习到人体结构的内在表示。
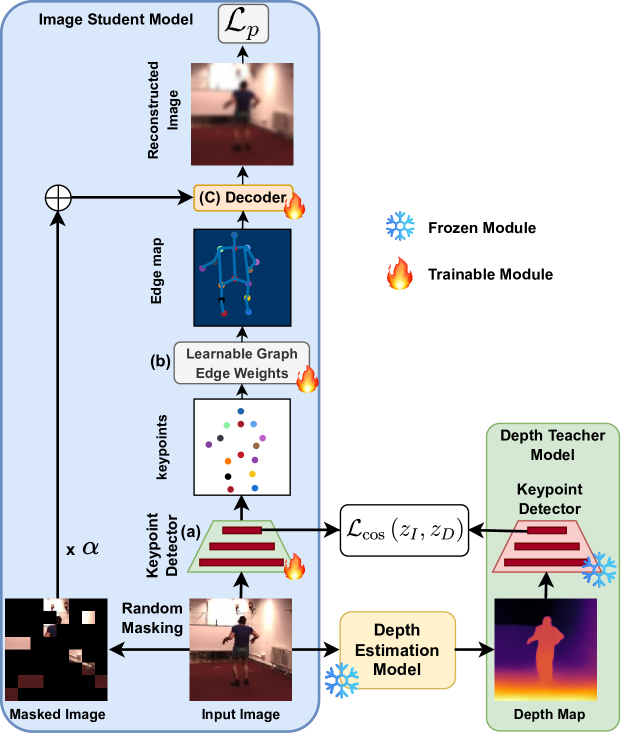
核心思路:Distill-DKP的核心思路是利用深度信息作为监督信号,通过知识蒸馏的方式,将深度模态的知识迁移到RGB模态,从而提升RGB图像关键点检测的准确性。通过让RGB学生模型学习深度教师模型的嵌入表示,可以有效地利用深度信息,同时保持推理阶段只使用RGB图像的效率。
技术框架:Distill-DKP框架包含一个基于深度图的教师模型和一个基于RGB图像的学生模型。首先,使用深度图训练教师模型,使其能够准确地检测深度图中的关键点。然后,利用教师模型的嵌入层输出作为知识,指导学生模型的训练。学生模型的目标是学习教师模型的嵌入表示,从而在RGB图像上也能准确地检测到关键点。推理阶段只使用训练好的学生模型。
关键创新:Distill-DKP的关键创新在于提出了跨模态知识蒸馏的方法,将深度信息引入到RGB图像的关键点检测中。与传统的知识蒸馏方法不同,Distill-DKP利用了不同模态的信息,从而能够更有效地提升学生模型的性能。此外,该方法在自监督学习框架下进行,无需人工标注的关键点信息。
关键设计:Distill-DKP的关键设计包括:1) 使用深度图训练教师模型,确保教师模型能够提供高质量的知识;2) 在嵌入层进行知识蒸馏,使得学生模型能够学习到更丰富的特征表示;3) 设计合适的损失函数,例如L2损失,来衡量学生模型和教师模型嵌入表示之间的差异;4) 精心选择教师模型和学生模型的网络结构,例如使用ResNet作为骨干网络,并根据数据集的特点进行调整。
🖼️ 关键图片

📊 实验亮点
Distill-DKP在Human3.6M数据集上将平均L2误差降低了47.15%,在Taichi数据集上将平均绝对误差降低了5.67%,并在DeepFashion数据集上将关键点精度提高了1.3%。这些结果表明,Distill-DKP显著优于现有的无监督关键点检测方法,证明了跨模态知识蒸馏的有效性。
🎯 应用场景
Distill-DKP在人体姿态估计、动作识别、人机交互等领域具有广泛的应用前景。该方法可以应用于智能监控、虚拟现实、游戏开发等场景,提升相关应用的性能和用户体验。未来,该方法可以扩展到其他模态的数据,例如红外图像、点云数据等,从而进一步提升关键点检测的准确性和鲁棒性。
📄 摘要(原文)
Existing unsupervised keypoint detection methods apply artificial deformations to images such as masking a significant portion of images and using reconstruction of original image as a learning objective to detect keypoints. However, this approach lacks depth information in the image and often detects keypoints on the background. To address this, we propose Distill-DKP, a novel cross-modal knowledge distillation framework that leverages depth maps and RGB images for keypoint detection in a self-supervised setting. During training, Distill-DKP extracts embedding-level knowledge from a depth-based teacher model to guide an image-based student model with inference restricted to the student. Experiments show that Distill-DKP significantly outperforms previous unsupervised methods by reducing mean L2 error by 47.15% on Human3.6M, mean average error by 5.67% on Taichi, and improving keypoints accuracy by 1.3% on DeepFashion dataset. Detailed ablation studies demonstrate the sensitivity of knowledge distillation across different layers of the network. Project Page: https://23wm13.github.io/distill-dkp/