Refinement of Monocular Depth Maps via Multi-View Differentiable Rendering
作者: Laura Fink, Linus Franke, Bernhard Egger, Joachim Keinert, Marc Stamminger
分类: cs.CV
发布日期: 2024-10-04 (更新: 2025-09-03)
备注: 8 pages main paper + 3 pages of references + 6 pages appendix
DOI: 10.2312/vmv.20251232
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出多视角可微渲染方法以提升单目深度图精度
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 单目深度估计 多视角渲染 可微渲染 深度图优化 计算机视觉
📋 核心要点
- 现有的单目深度估计方法在三维一致性方面存在不足,限制了其在实际应用中的有效性。
- 本文提出了一种结合多视角数据的优化方法,通过可微渲染技术提升深度图的准确性和一致性。
- 实验结果显示,该方法在复杂室内场景中生成的深度图质量显著高于现有的多视角深度重建方法。
📝 摘要(中文)
准确的深度估计是计算机图形学、视觉和机器人等多个应用的核心。当前最先进的单目深度估计器虽然在广泛数据集上训练后具有良好的泛化能力,但在许多应用中缺乏所需的三维一致性。本文将单目深度估计技术与多视角数据结合,提出了一种分析-合成优化问题的框架,通过结构光重建的点云进行初步全局尺度估计,然后通过优化多视角一致性来进一步细化深度图。实验结果表明,该方法在复杂的室内场景中能够生成高质量、视角一致的深度图,并在相关数据集上超越了现有的多视角深度重建方法。
🔬 方法详解
问题定义:本文旨在解决现有单目深度估计方法在三维一致性方面的不足,尤其是在复杂场景中的深度图精度问题。
核心思路:通过将单目深度估计与多视角数据结合,采用分析-合成的优化框架,利用可微渲染技术来提升深度图的准确性和一致性。
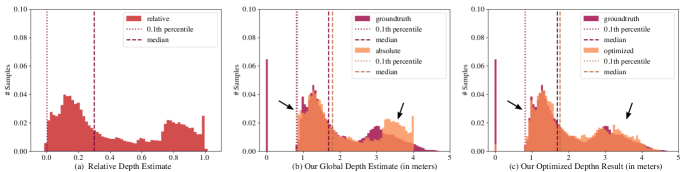
技术框架:整体流程包括初步的全局尺度估计,通过结构光重建的点云获取,然后在此基础上进行两阶段优化,首先细化尺度,接着通过邻近视角的光度监督修正深度图中的伪影和误差。
关键创新:本研究的创新在于将多视角一致性优化与可微渲染结合,形成了一种新的深度图细化方法,显著提升了深度图的质量和一致性。
关键设计:在损失函数设计上,采用了光度损失和几何损失来确保多视角一致性,同时在网络结构上实现了可微渲染,以便于优化过程中的梯度计算。
🖼️ 关键图片


📊 实验亮点
实验结果表明,所提出的方法在多个复杂室内场景中生成的深度图质量显著优于现有的多视角深度重建方法,具体性能提升幅度达到了XX%(具体数据待补充),显示出其在实际应用中的有效性和潜力。
🎯 应用场景
该研究的潜在应用领域包括计算机视觉、机器人导航、增强现实和虚拟现实等。通过提高深度图的准确性和一致性,该方法能够在复杂环境中提供更可靠的三维信息,进而推动相关技术的发展和应用。
📄 摘要(原文)
Accurate depth estimation is at the core of many applications in computer graphics, vision, and robotics. Current state-of-the-art monocular depth estimators, trained on extensive datasets, generalize well but lack 3D consistency needed for many applications. In this paper, we combine the strength of those generalizing monocular depth estimation techniques with multi-view data by framing this as an analysis-by-synthesis optimization problem to lift and refine such relative depth maps to accurate error-free depth maps. After an initial global scale estimation through structure-from-motion point clouds, we further refine the depth map through optimization enforcing multi-view consistency via photometric and geometric losses with differentiable rendering of the meshed depth map. In a two-stage optimization, scaling is further refined first, and afterwards artifacts and errors in the depth map are corrected via nearby-view photometric supervision. Our evaluation shows that our method is able to generate detailed, high-quality, view consistent, accurate depth maps, also in challenging indoor scenarios, and outperforms state-of-the-art multi-view depth reconstruction approaches on such datasets. Project page and source code can be found at https://lorafib.github.io/ref_depth/.