Unraveling Cross-Modality Knowledge Conflicts in Large Vision-Language Models
作者: Tinghui Zhu, Qin Liu, Fei Wang, Zhengzhong Tu, Muhao Chen
分类: cs.CV, cs.CL
发布日期: 2024-10-04 (更新: 2024-10-11)
备注: Website: https://darthzhu.github.io/cross-modality-knowledge-conflict/
💡 一句话要点
提出跨模态参数知识冲突检测与缓解方法,提升大视觉语言模型性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 跨模态学习 知识冲突 对比学习 动态解码 视觉问答 多模态推理
📋 核心要点
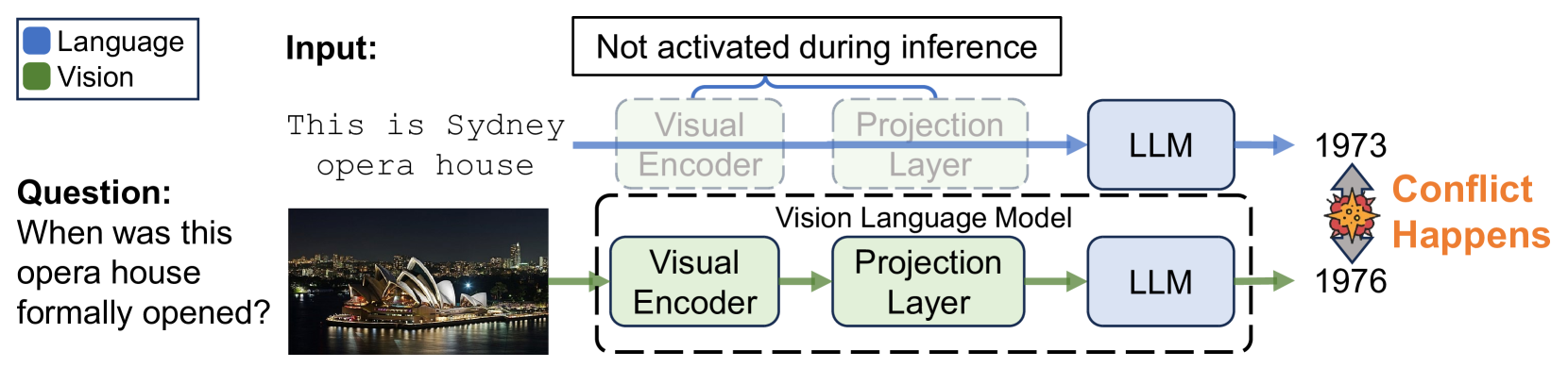
- 现有大型视觉语言模型存在视觉和语言模态知识不一致导致的参数知识冲突问题。
- 通过检测、解释和缓解跨模态参数知识冲突,提升模型在多模态任务中的推理能力。
- 提出的动态对比解码和prompt策略在ViQuAE和InfoSeek数据集上验证了有效性,提高了模型准确率。
📝 摘要(中文)
大型视觉语言模型(LVLMs)在捕捉和推理多模态输入方面表现出令人印象深刻的能力。然而,这些模型容易出现参数知识冲突,这种冲突源于其视觉和语言组件之间表示知识的不一致。本文正式定义了$ extbf{跨模态参数知识冲突}$问题,并提出了一种系统的方法来检测、解释和缓解这些冲突。我们引入了一个pipeline,用于识别视觉和文本答案之间的冲突,表明最近的LVLMs中存在持续较高的跨模态冲突率,而与模型大小无关。我们进一步研究了这些冲突如何干扰推理过程,并提出了一个对比度量来区分冲突样本和其他样本。基于这些见解,我们开发了一种新的动态对比解码方法,该方法基于答案置信度消除从置信度较低的模态组件推断出的不良logits。对于不提供logits的模型,我们还引入了两种基于prompt的策略来缓解冲突。我们的方法在ViQuAE和InfoSeek数据集上都取得了有希望的准确性提升。具体来说,使用LLaVA-34B,我们提出的动态对比解码平均提高了2.24%的准确率。
🔬 方法详解
问题定义:论文旨在解决大型视觉语言模型(LVLMs)中存在的跨模态参数知识冲突问题。现有LVLMs在处理多模态输入时,由于视觉和语言组件之间知识表示的不一致,导致模型产生错误的推理结果。这种冲突会降低模型在视觉问答等任务中的准确性。
核心思路:论文的核心思路是通过检测和缓解视觉和语言模态之间的知识冲突来提高LVLMs的性能。具体来说,首先识别出视觉和文本答案之间的冲突,然后根据模态的置信度动态地调整模型的输出,从而减少冲突的影响。
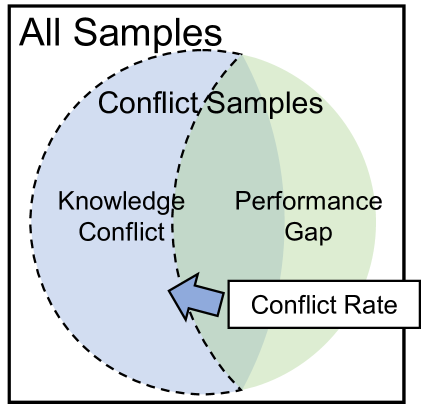
技术框架:论文提出的方法包含以下几个主要阶段:1) 冲突检测:构建pipeline识别视觉和文本答案之间的冲突。2) 冲突分析:使用对比度量来区分冲突样本和其他样本,分析冲突对推理过程的影响。3) 冲突缓解:针对提供logits的模型,提出动态对比解码方法;针对不提供logits的模型,提出prompt-based策略。
关键创新:论文的关键创新在于提出了动态对比解码方法,该方法能够根据视觉和语言模态的置信度动态地调整模型的输出。这种方法能够有效地消除来自置信度较低的模态组件的干扰,从而提高模型的准确性。此外,论文还提出了两种prompt-based策略,用于缓解不提供logits的模型的冲突。
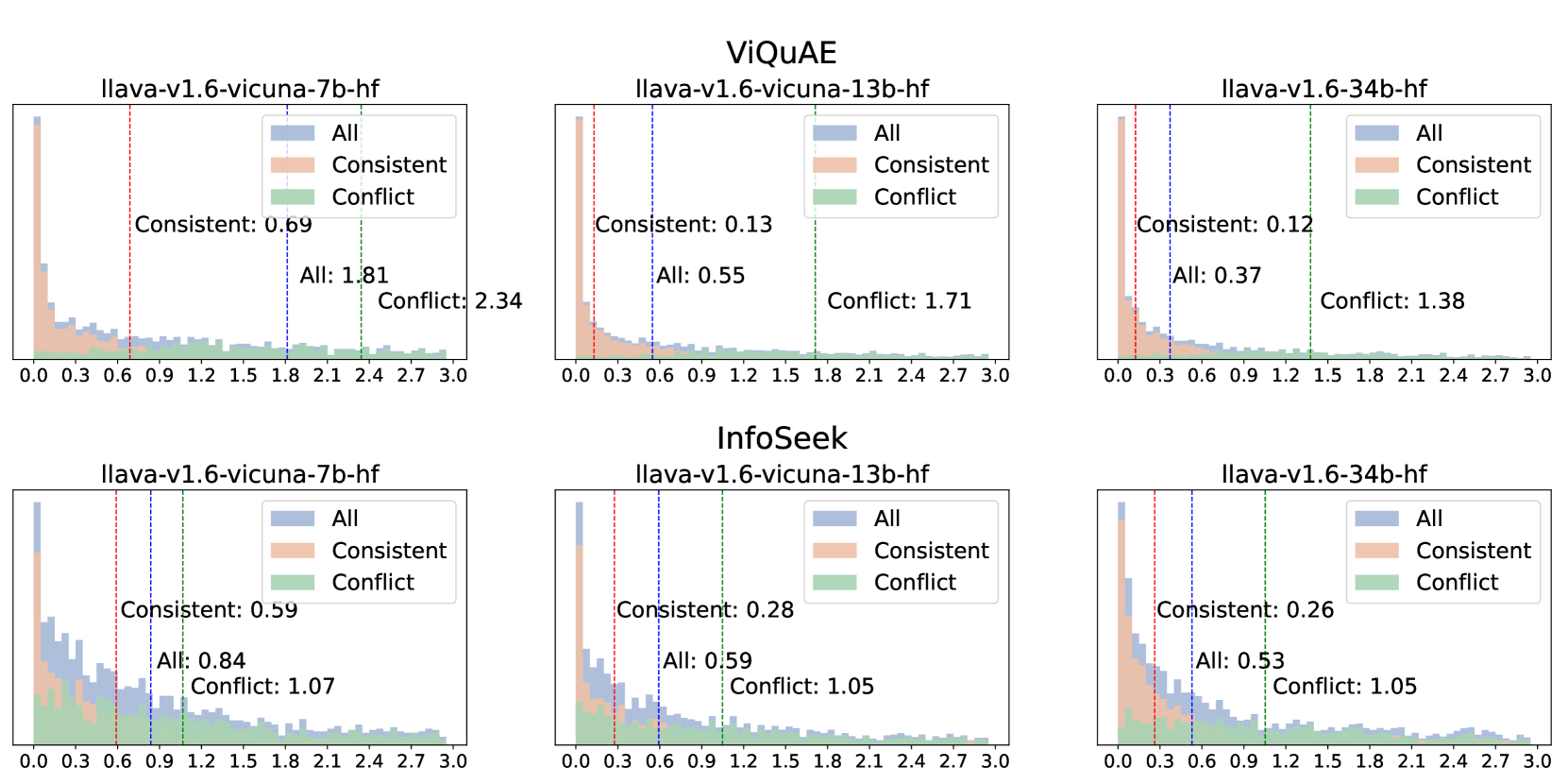
关键设计:动态对比解码的关键设计在于使用对比损失函数来训练模型,使得模型能够区分冲突样本和其他样本。具体来说,对于每个样本,模型会生成一个视觉答案和一个文本答案,然后计算这两个答案之间的相似度。如果这两个答案之间存在冲突,则相似度会较低,否则相似度会较高。模型的目标是最大化非冲突样本的相似度,同时最小化冲突样本的相似度。对于prompt-based策略,关键在于设计合适的prompt,引导模型关注更可靠的模态信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,论文提出的动态对比解码方法和prompt-based策略在ViQuAE和InfoSeek数据集上都取得了显著的性能提升。例如,使用LLaVA-34B模型,动态对比解码方法平均提高了2.24%的准确率。这些结果验证了该方法在缓解跨模态知识冲突方面的有效性。
🎯 应用场景
该研究成果可应用于各种需要多模态信息融合的场景,例如视觉问答、图像描述、机器人导航等。通过缓解跨模态知识冲突,可以提高模型在这些任务中的准确性和可靠性,从而提升用户体验和应用价值。未来,该方法有望扩展到更多模态和更复杂的任务中。
📄 摘要(原文)
Large Vision-Language Models (LVLMs) have demonstrated impressive capabilities for capturing and reasoning over multimodal inputs. However, these models are prone to parametric knowledge conflicts, which arise from inconsistencies of represented knowledge between their vision and language components. In this paper, we formally define the problem of $\textbf{cross-modality parametric knowledge conflict}$ and present a systematic approach to detect, interpret, and mitigate them. We introduce a pipeline that identifies conflicts between visual and textual answers, showing a persistently high conflict rate across modalities in recent LVLMs regardless of the model size. We further investigate how these conflicts interfere with the inference process and propose a contrastive metric to discern the conflicting samples from the others. Building on these insights, we develop a novel dynamic contrastive decoding method that removes undesirable logits inferred from the less confident modality components based on answer confidence. For models that do not provide logits, we also introduce two prompt-based strategies to mitigate the conflicts. Our methods achieve promising improvements in accuracy on both the ViQuAE and InfoSeek datasets. Specifically, using LLaVA-34B, our proposed dynamic contrastive decoding improves an average accuracy of 2.24%.