VEDIT: Latent Prediction Architecture For Procedural Video Representation Learning
作者: Han Lin, Tushar Nagarajan, Nicolas Ballas, Mido Assran, Mojtaba Komeili, Mohit Bansal, Koustuv Sinha
分类: cs.CV, cs.LG
发布日期: 2024-10-04
备注: 10 pages
💡 一句话要点
VEDIT:基于潜在空间预测的程序性视频表征学习框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 程序性视频理解 潜在空间预测 扩散Transformer 动作预测 程序规划
📋 核心要点
- 现有程序性视频表征学习方法依赖大规模预训练和语言监督,计算成本高昂,且对噪声文本监督的有效性未充分验证。
- VEDIT利用冻结的预训练视觉编码器,在潜在空间进行预测,通过迭代去噪学习鲁棒表征,无需额外预训练或语言监督。
- 实验表明,VEDIT在长程动作预测、步骤预测、任务分类和程序规划任务上均取得了显著的性能提升,达到或超过了当前最优水平。
📝 摘要(中文)
程序性视频表征学习旨在学习一个智能体,使其能够在给定当前视频输入(通常结合文本标注)的情况下,预测未来。现有方法通常依赖于视觉编码器和预测模型的大规模预训练,并使用语言监督。然而,以往工作尚未充分验证这种计算密集型预训练在学习带有噪声文本监督的视频片段序列时的必要性和有效性。本文表明,一个强大的、现成的、冻结的预训练视觉编码器,以及一个精心设计的预测模型,可以在预测和程序规划中实现最先进的性能,而无需预训练预测模型,也无需额外的语言或ASR监督。该方法利用公开可用的视觉编码器的潜在嵌入空间,而不是从像素空间学习表征。通过以观察到的步骤的冻结片段级嵌入为条件来预测未见步骤的动作,预测模型能够通过迭代去噪学习鲁棒的预测表征,并利用扩散Transformer的最新进展。在四个数据集(NIV、CrossTask、COIN和Ego4D-v2)上的五个程序学习任务的实证研究表明,该模型在长程动作预测方面优于强大的基线(Verb ED@20提高+2.6%,Noun ED@20提高+3.1%),并在步骤预测(+5.0%)、任务分类(+3.8%)和程序规划任务(成功率提高高达+2.28%,mAcc提高+3.39%,mIoU提高+0.90%)方面显著提高了SoTA。
🔬 方法详解
问题定义:程序性视频表征学习旨在预测视频中未见步骤的动作,并进行程序规划。现有方法的痛点在于依赖大规模的视觉编码器和预测模型的预训练,以及额外的语言监督,计算成本高昂,且对噪声文本监督的有效性存疑。
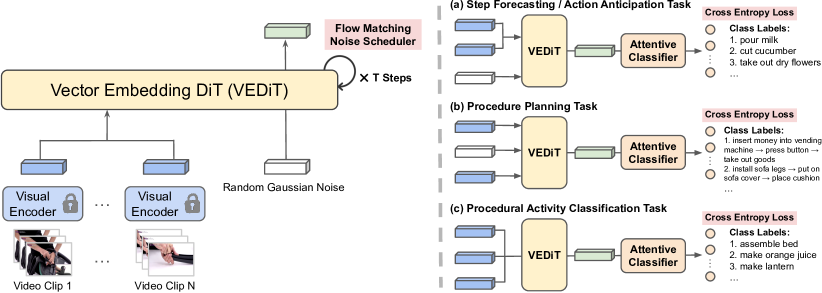
核心思路:VEDIT的核心思路是利用一个强大的、现成的、冻结的预训练视觉编码器,避免从像素空间直接学习,而是在视觉编码器的潜在嵌入空间进行预测。通过迭代去噪学习鲁棒的表征,从而减少对大规模预训练和额外语言监督的依赖。
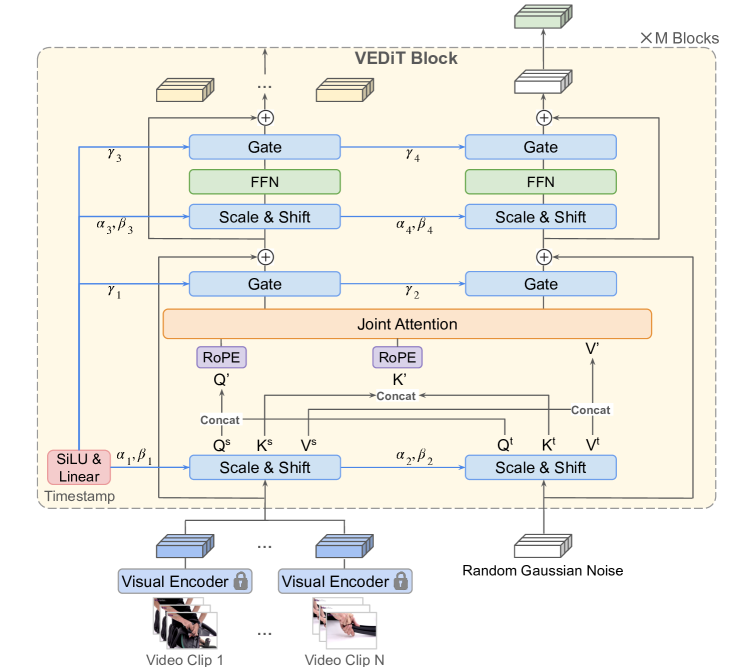
技术框架:VEDIT的整体框架包括:1) 使用预训练的视觉编码器提取视频片段的嵌入特征;2) 使用预测模型,以观察到的步骤的嵌入特征为条件,预测未见步骤的动作;3) 使用迭代去噪方法,提高预测模型的鲁棒性。该框架避免了对预测模型进行预训练,也无需额外的语言或ASR监督。
关键创新:VEDIT最重要的技术创新点在于利用了预训练视觉编码器的潜在空间进行预测,并结合迭代去噪方法,从而在无需额外预训练和语言监督的情况下,实现了最先进的性能。这与现有方法依赖大规模预训练和语言监督形成了本质区别。
关键设计:VEDIT的关键设计包括:1) 使用冻结的预训练视觉编码器,避免了对视觉编码器的微调;2) 使用扩散Transformer作为预测模型,利用其强大的生成能力;3) 使用迭代去噪方法,提高预测模型的鲁棒性;4) 损失函数的设计旨在最小化预测动作与真实动作之间的差异。
🖼️ 关键图片
📊 实验亮点
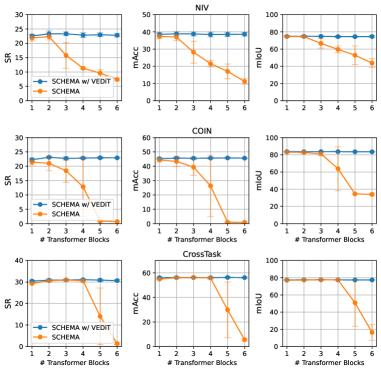
VEDIT在五个程序学习任务上取得了显著的性能提升。在长程动作预测方面,Verb ED@20提高了+2.6%,Noun ED@20提高了+3.1%。在步骤预测方面,提高了+5.0%。在任务分类方面,提高了+3.8%。在程序规划任务方面,成功率提高高达+2.28%,mAcc提高+3.39%,mIoU提高+0.90%。
🎯 应用场景
VEDIT在机器人操作、自动驾驶、智能助手等领域具有广泛的应用前景。例如,可以用于训练机器人学习执行复杂的程序性任务,或者帮助自动驾驶系统预测行人的行为。该研究降低了程序性视频表征学习的计算成本和数据需求,有望加速相关技术的落地。
📄 摘要(原文)
Procedural video representation learning is an active research area where the objective is to learn an agent which can anticipate and forecast the future given the present video input, typically in conjunction with textual annotations. Prior works often rely on large-scale pretraining of visual encoders and prediction models with language supervision. However, the necessity and effectiveness of extending compute intensive pretraining to learn video clip sequences with noisy text supervision have not yet been fully validated by previous works. In this work, we show that a strong off-the-shelf frozen pretrained visual encoder, along with a well designed prediction model, can achieve state-of-the-art (SoTA) performance in forecasting and procedural planning without the need for pretraining the prediction model, nor requiring additional supervision from language or ASR. Instead of learning representations from pixel space, our method utilizes the latent embedding space of publicly available vision encoders. By conditioning on frozen clip-level embeddings from observed steps to predict the actions of unseen steps, our prediction model is able to learn robust representations for forecasting through iterative denoising - leveraging the recent advances in diffusion transformers (Peebles & Xie, 2023). Empirical studies over a total of five procedural learning tasks across four datasets (NIV, CrossTask, COIN and Ego4D-v2) show that our model advances the strong baselines in long-horizon action anticipation (+2.6% in Verb ED@20, +3.1% in Noun ED@20), and significantly improves the SoTA in step forecasting (+5.0%), task classification (+3.8%), and procedure planning tasks (up to +2.28% in success rate, +3.39% in mAcc, and +0.90% in mIoU).