An X-Ray Is Worth 15 Features: Sparse Autoencoders for Interpretable Radiology Report Generation
作者: Ahmed Abdulaal, Hugo Fry, Nina Montaña-Brown, Ayodeji Ijishakin, Jack Gao, Stephanie Hyland, Daniel C. Alexander, Daniel C. Castro
分类: cs.CV, cs.AI
发布日期: 2024-10-04
💡 一句话要点
提出SAE-Rad,利用稀疏自编码器提升放射报告生成的可解释性与效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 放射报告生成 稀疏自编码器 可解释性AI 多模态推理 医学图像分析
📋 核心要点
- 现有视觉-语言模型在放射报告生成中存在幻觉问题,可解释性差,且需要大量计算资源进行微调。
- SAE-Rad利用稀疏自编码器将视觉Transformer的潜在表示分解为人类可解释的特征,并结合现成的语言模型生成报告。
- SAE-Rad在MIMIC-CXR数据集上取得了与SOTA模型相当的性能,同时显著降低了计算成本,并提高了报告的可解释性。
📝 摘要(中文)
放射科服务面临前所未有的需求,促使人们对自动放射报告生成产生浓厚兴趣。现有的视觉-语言模型(VLMs)存在幻觉、缺乏可解释性且需要昂贵的微调。我们引入SAE-Rad,它使用稀疏自编码器(SAEs)将预训练视觉Transformer的潜在表示分解为人类可解释的特征。我们的混合架构结合了最先进的SAE进展,在保持稀疏性的同时实现了准确的潜在重建。通过使用现成的语言模型,我们将ground-truth报告提炼为每个SAE特征的放射学描述,然后将这些描述编译成每张图像的完整报告,从而无需为此任务微调大型模型。据我们所知,SAE-Rad代表了首次将机械可解释性技术明确用于下游多模态推理任务的实例。在MIMIC-CXR数据集上,与最先进的模型相比,SAE-Rad实现了具有竞争力的放射学特定指标,同时使用的计算资源明显更少。定性分析表明,SAE-Rad学习了有意义的视觉概念,并生成与专家解释紧密一致的报告。我们的结果表明,SAE可以增强医疗保健中的多模态推理,为现有VLM提供更具可解释性的替代方案。
🔬 方法详解
问题定义:论文旨在解决放射报告自动生成任务中,现有视觉-语言模型(VLMs)存在的幻觉问题、可解释性差以及需要大量计算资源进行微调的问题。现有方法通常依赖于端到端的微调,这不仅耗费资源,而且生成的报告难以理解其推理过程。
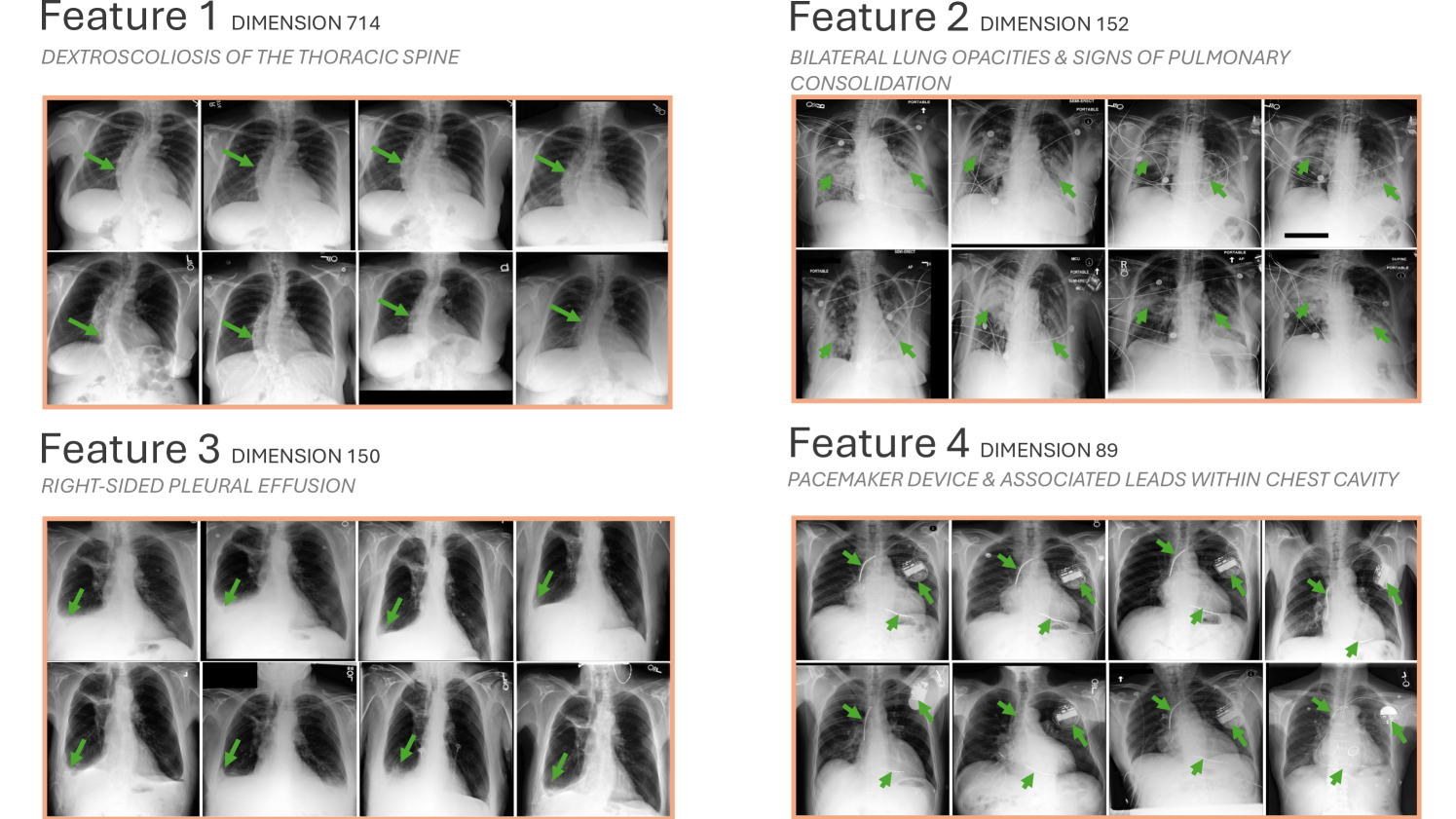
核心思路:论文的核心思路是利用稀疏自编码器(SAEs)将预训练视觉Transformer提取的图像特征分解为一组人类可解释的视觉概念。通过将这些概念与放射学描述关联,并使用语言模型将它们组合成完整的报告,从而实现可解释且高效的报告生成。这种方法避免了对大型VLM进行端到端微调的需要。
技术框架:SAE-Rad的整体架构包含以下几个主要模块:1) 预训练的视觉Transformer:用于提取图像的潜在表示。2) 稀疏自编码器(SAEs):将潜在表示分解为稀疏的、人类可解释的特征。3) 放射学描述蒸馏:使用现成的语言模型将ground-truth报告提炼为每个SAE特征的放射学描述。4) 报告生成:将SAE特征对应的放射学描述组合成完整的报告。
关键创新:该论文最重要的技术创新点在于将机械可解释性技术(即稀疏自编码器)显式地应用于下游多模态推理任务(放射报告生成)。与现有方法相比,SAE-Rad不依赖于端到端的黑盒模型,而是通过分解潜在表示来提高模型的可解释性。
关键设计:SAE-Rad的关键设计包括:1) 使用L1正则化来鼓励SAE的稀疏性,从而使每个特征对应于一个特定的视觉概念。2) 使用现成的语言模型进行放射学描述蒸馏,避免了对大型语言模型进行微调的需要。3) 混合架构,结合了最先进的SAE进展,实现了准确的潜在重建,同时保持了稀疏性。具体的参数设置和网络结构细节在论文中有详细描述(未知)。
🖼️ 关键图片


📊 实验亮点
SAE-Rad在MIMIC-CXR数据集上取得了与最先进模型具有竞争力的放射学特定指标,同时显著降低了计算资源的使用。定性分析表明,SAE-Rad能够学习到有意义的视觉概念,并生成与专家解读高度一致的报告,验证了其可解释性和有效性。具体的性能提升幅度与基线模型的对比数据在论文中有详细描述(未知)。
🎯 应用场景
SAE-Rad具有广泛的应用前景,可用于辅助放射科医生进行报告撰写,提高诊断效率和准确性。该方法还可以应用于其他医学图像分析任务,例如病灶检测和分割,以及其他需要可解释性AI的领域。未来,该研究可以促进医疗AI的透明化和可信度,从而更好地服务于临床实践。
📄 摘要(原文)
Radiological services are experiencing unprecedented demand, leading to increased interest in automating radiology report generation. Existing Vision-Language Models (VLMs) suffer from hallucinations, lack interpretability, and require expensive fine-tuning. We introduce SAE-Rad, which uses sparse autoencoders (SAEs) to decompose latent representations from a pre-trained vision transformer into human-interpretable features. Our hybrid architecture combines state-of-the-art SAE advancements, achieving accurate latent reconstructions while maintaining sparsity. Using an off-the-shelf language model, we distil ground-truth reports into radiological descriptions for each SAE feature, which we then compile into a full report for each image, eliminating the need for fine-tuning large models for this task. To the best of our knowledge, SAE-Rad represents the first instance of using mechanistic interpretability techniques explicitly for a downstream multi-modal reasoning task. On the MIMIC-CXR dataset, SAE-Rad achieves competitive radiology-specific metrics compared to state-of-the-art models while using significantly fewer computational resources for training. Qualitative analysis reveals that SAE-Rad learns meaningful visual concepts and generates reports aligning closely with expert interpretations. Our results suggest that SAEs can enhance multimodal reasoning in healthcare, providing a more interpretable alternative to existing VLMs.