Autonomous Character-Scene Interaction Synthesis from Text Instruction
作者: Nan Jiang, Zimo He, Zi Wang, Hongjie Li, Yixin Chen, Siyuan Huang, Yixin Zhu
分类: cs.CV
发布日期: 2024-10-04 (更新: 2024-10-08)
💡 一句话要点
提出基于文本指令的自主角色-场景交互动作合成框架
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱五:交互与反应 (Interaction & Reaction)
关键词: 动作合成 文本指令 场景交互 扩散模型 自主调度 机器人控制 虚拟现实
📋 核心要点
- 现有方法在3D环境中合成人类动作,尤其是在涉及复杂活动时,需要大量用户定义的路点和阶段转换,自动化程度低。
- 该论文提出了一种基于文本指令和目标位置,自动合成多阶段场景交互动作的框架,核心是自回归扩散模型和自主调度器。
- 实验结果表明,该方法能够生成高质量、与环境和文本指令对齐的多阶段动作,验证了其有效性。
📝 摘要(中文)
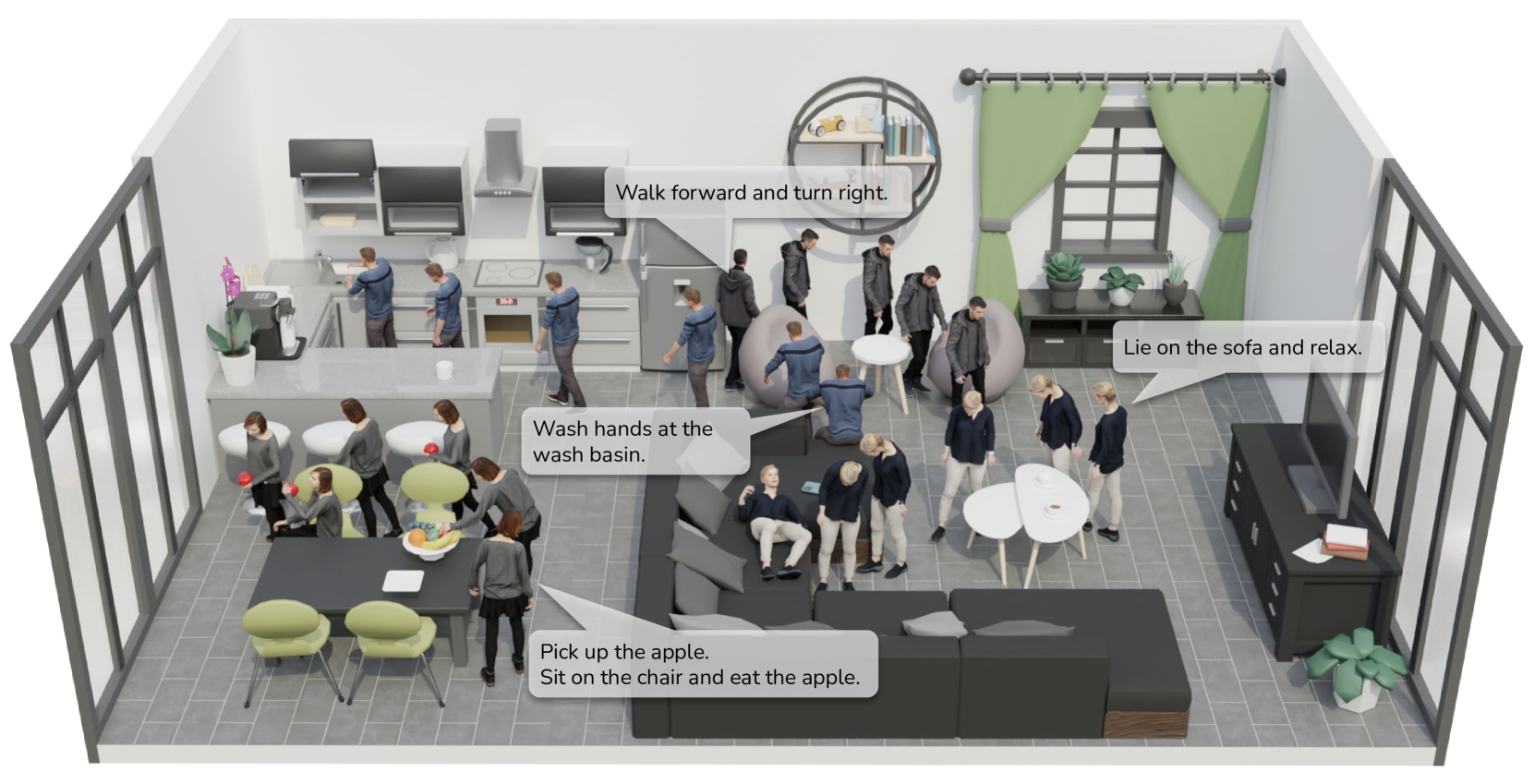
本文提出了一种综合框架,用于直接从单个文本指令和目标位置合成多阶段的、感知场景的交互动作。该方法采用自回归扩散模型来合成下一个动作片段,并使用自主调度器来预测每个动作阶段的转换。为了确保合成的动作与环境无缝集成,本文提出了一种场景表示,该表示同时考虑了起始位置和目标位置的局部感知。通过将帧嵌入与语言输入相结合,进一步增强了生成动作的连贯性。此外,为了支持模型训练,本文还提出了一个全面的动作捕捉数据集,该数据集包含120个室内场景中40种动作类型的16小时动作序列,每个动作序列都带有精确的语言描述。实验结果表明,该方法在生成与环境和文本条件紧密对齐的高质量多阶段动作方面是有效的。
🔬 方法详解
问题定义:现有方法在3D场景中合成角色动作时,尤其是在涉及复杂交互(如行走、抓取物体等)时,需要人工指定大量的路点和状态转移,这使得动画制作过程繁琐且难以自动化。因此,如何仅通过简单的文本指令和目标位置,自动生成符合场景约束的多阶段交互动作,是一个亟待解决的问题。
核心思路:该论文的核心思路是利用自回归扩散模型逐步生成动作片段,并使用自主调度器预测动作阶段的转换。通过结合场景信息和语言指令,引导模型生成与环境和用户意图相符的动作。这种方法旨在减少人工干预,实现更智能、更自然的动作合成。
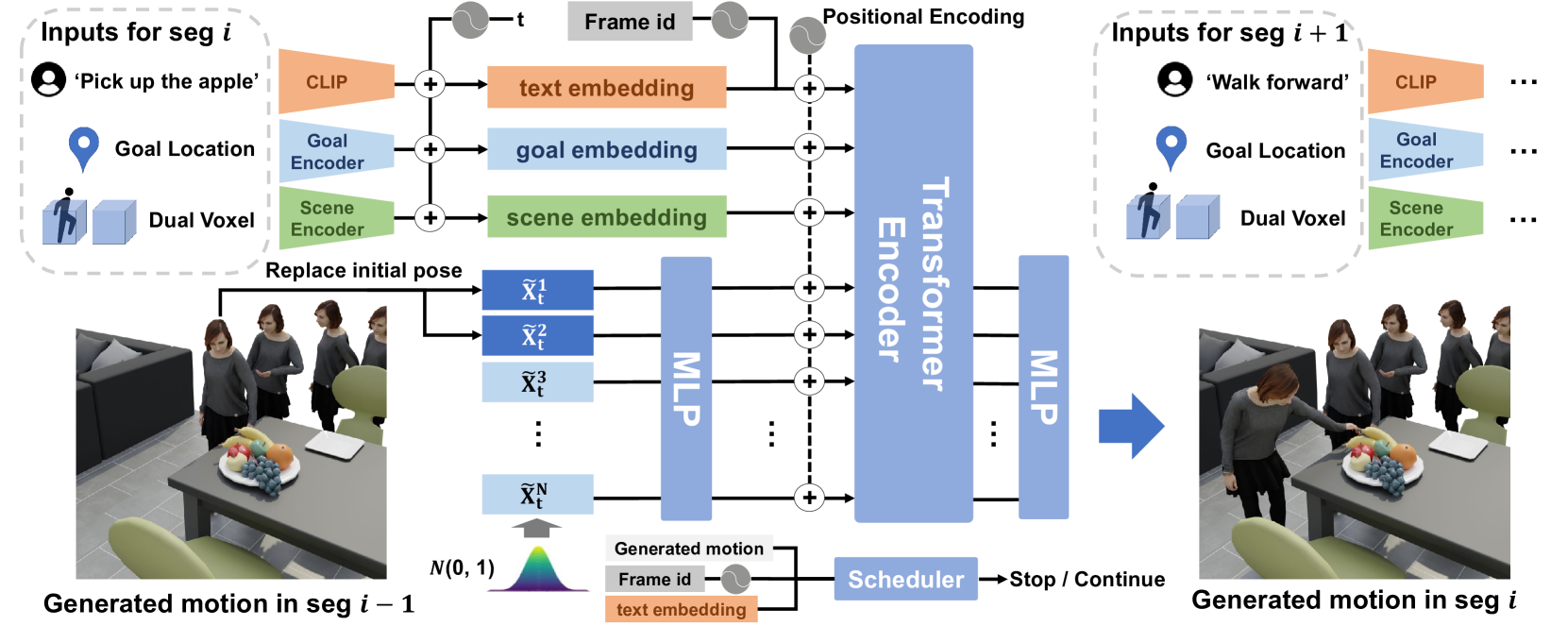
技术框架:该框架主要包含以下几个模块:1) 场景表示模块:用于提取起始位置和目标位置的局部场景信息。2) 动作生成模块:采用自回归扩散模型,根据当前状态、场景信息和文本指令,生成下一个动作片段。3) 动作调度模块:使用自主调度器预测动作阶段的转换,例如从行走切换到抓取。4) 融合模块:将帧嵌入与语言输入相结合,增强生成动作的连贯性。整个流程是:输入文本指令和目标位置,场景表示模块提取场景特征,动作生成模块和动作调度模块协同工作,逐步生成完整的交互动作序列。
关键创新:该论文的关键创新在于:1) 提出了一个端到端的框架,可以直接从文本指令和目标位置生成多阶段交互动作,无需人工指定路点和状态转移。2) 提出了一个自主调度器,可以自动预测动作阶段的转换,使得动作序列更加自然流畅。3) 提出了一个场景表示方法,同时考虑了起始位置和目标位置的局部场景信息,使得生成的动作与环境更加协调。
关键设计:在动作生成模块中,使用了扩散模型,通过逐步去噪的方式生成动作。在场景表示模块中,使用了卷积神经网络提取局部场景特征。在动作调度模块中,使用了循环神经网络预测动作阶段的转换概率。损失函数包括动作重建损失、场景对齐损失和语言一致性损失。具体参数设置和网络结构细节在论文中有详细描述,此处未知。
🖼️ 关键图片
📊 实验亮点
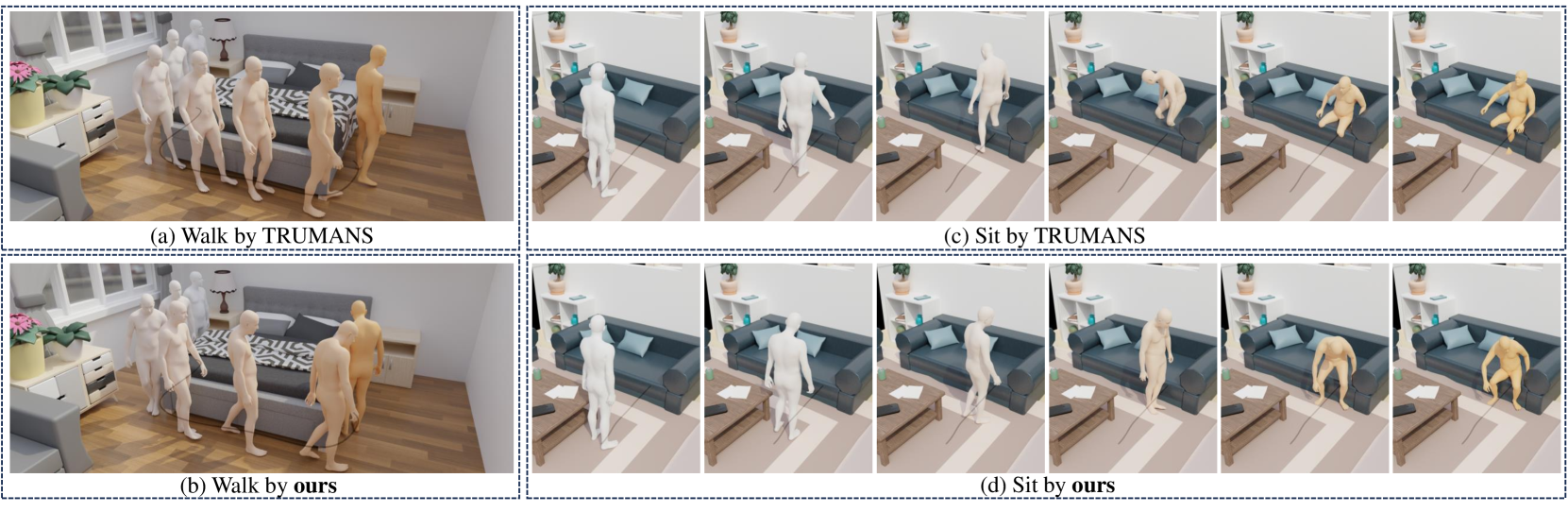
实验结果表明,该方法能够生成高质量、与环境和文本指令对齐的多阶段动作。与现有方法相比,该方法在动作质量、场景适应性和语言一致性方面均有显著提升。论文还构建了一个包含16小时动作序列的大规模数据集,为相关研究提供了重要的数据支持。具体性能数据和提升幅度未知。
🎯 应用场景
该研究成果可广泛应用于游戏开发、虚拟现实、机器人控制等领域。例如,在游戏开发中,可以根据玩家的文本指令自动生成游戏角色的动作,提高开发效率和游戏体验。在虚拟现实中,可以根据用户的语音指令,生成虚拟角色的交互动作,增强沉浸感。在机器人控制中,可以根据用户的指令,控制机器人完成复杂的任务。
📄 摘要(原文)
Synthesizing human motions in 3D environments, particularly those with complex activities such as locomotion, hand-reaching, and human-object interaction, presents substantial demands for user-defined waypoints and stage transitions. These requirements pose challenges for current models, leading to a notable gap in automating the animation of characters from simple human inputs. This paper addresses this challenge by introducing a comprehensive framework for synthesizing multi-stage scene-aware interaction motions directly from a single text instruction and goal location. Our approach employs an auto-regressive diffusion model to synthesize the next motion segment, along with an autonomous scheduler predicting the transition for each action stage. To ensure that the synthesized motions are seamlessly integrated within the environment, we propose a scene representation that considers the local perception both at the start and the goal location. We further enhance the coherence of the generated motion by integrating frame embeddings with language input. Additionally, to support model training, we present a comprehensive motion-captured dataset comprising 16 hours of motion sequences in 120 indoor scenes covering 40 types of motions, each annotated with precise language descriptions. Experimental results demonstrate the efficacy of our method in generating high-quality, multi-stage motions closely aligned with environmental and textual conditions.