Efficient High-Resolution Visual Representation Learning with State Space Model for Human Pose Estimation
作者: Hao Zhang, Yongqiang Ma, Wenqi Shao, Ping Luo, Nanning Zheng, Kaipeng Zhang
分类: cs.CV
发布日期: 2024-10-04 (更新: 2025-08-15)
🔗 代码/项目: GITHUB
💡 一句话要点
提出HRVMamba,利用动态视觉状态空间模型高效学习高分辨率人体姿态表示
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人体姿态估计 状态空间模型 高分辨率表示学习 动态视觉状态空间 可变形卷积
📋 核心要点
- 现有ViT模型在高分辨率输入下计算复杂度高,限制了其在资源受限设备上的应用。
- 提出动态视觉状态空间(DVSS)块,通过多尺度卷积和可变形操作增强局部空间表示和语义聚合。
- HRVMamba在人体姿态估计、图像分类和语义分割任务上表现出与主流模型相当甚至更优的性能。
📝 摘要(中文)
对于人体姿态估计等密集预测任务,捕获长程依赖关系并保持高分辨率视觉表示至关重要。Vision Transformers (ViTs) 通过自注意力机制实现了全局建模,但其计算复杂度随token数量呈二次方增长,限制了其在高分辨率输入上的效率和可扩展性,尤其是在移动和资源受限的设备上。状态空间模型 (SSMs),如Mamba,通过结合全局感受野和线性计算复杂度提供了一种高效的替代方案,从而实现可扩展且资源友好的序列建模。然而,当应用于密集预测任务时,现有的视觉SSM面临着关键限制:空间归纳偏置弱、隐藏状态衰减导致的长程遗忘以及阻碍精细定位的低分辨率输出。为了解决这些问题,我们提出了动态视觉状态空间 (DVSS) 块,该块通过多尺度卷积操作增强视觉状态空间模型,以增强局部空间表示并加强空间归纳偏置。通过架构探索和理论分析,我们将可变形操作融入DVSS块中,并将其确定为一种高效且有效的机制,通过输入相关的自适应空间采样来增强语义聚合并减轻长程遗忘。我们将DVSS嵌入到多分支高分辨率架构中,构建了HRVMamba,这是一种用于高效高分辨率表示学习的新型模型。在人体姿态估计、图像分类和语义分割上的大量实验表明,HRVMamba 在性能上与领先的基于 CNN、ViT 和 SSM 的基线模型相比具有竞争力。
🔬 方法详解
问题定义:论文旨在解决人体姿态估计等密集预测任务中,现有模型难以兼顾高分辨率表示和长程依赖关系建模的问题。Vision Transformer虽然能有效建模全局信息,但计算复杂度高,难以应用于高分辨率图像。而直接应用视觉SSM则存在空间归纳偏置弱、长程遗忘以及输出分辨率低等问题。
核心思路:论文的核心思路是设计一种高效的视觉状态空间模型,既能保持线性计算复杂度,又能有效捕获长程依赖关系和局部空间信息。通过引入动态视觉状态空间(DVSS)块,增强模型的空间归纳偏置,并利用可变形操作缓解长程遗忘问题。
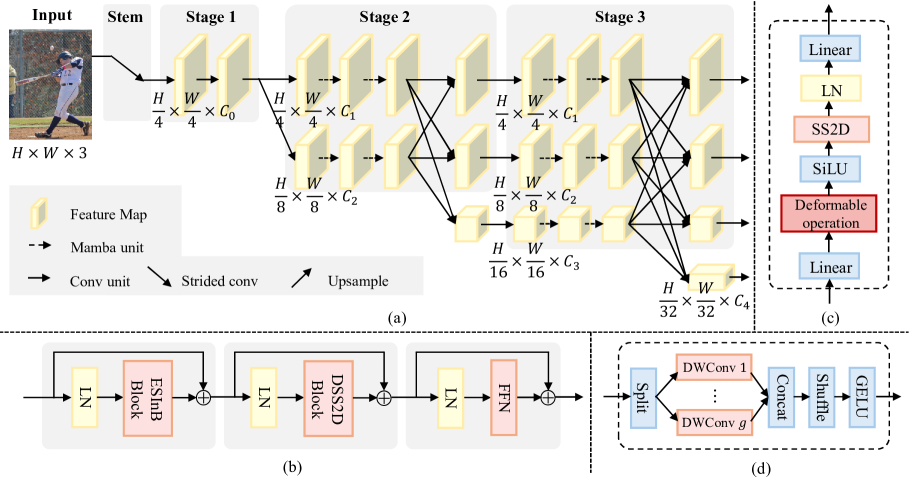
技术框架:HRVMamba的整体架构是一个多分支高分辨率网络,类似于HRNet。每个分支包含多个DVSS块,用于提取不同尺度的特征表示。DVSS块是核心组件,它在视觉状态空间模型的基础上,引入了多尺度卷积和可变形操作。整个网络通过融合不同分支的特征,最终实现高分辨率的姿态估计。
关键创新:论文的关键创新在于DVSS块的设计,它将视觉状态空间模型与卷积操作和可变形操作相结合。多尺度卷积增强了局部空间表示,而可变形操作则通过自适应空间采样,增强了语义聚合能力,并缓解了长程遗忘问题。这种结合使得模型既能高效地建模全局信息,又能保持高分辨率的局部细节。
关键设计:DVSS块的关键设计包括:1) 多尺度卷积核的选择,用于捕获不同尺度的局部特征;2) 可变形卷积的偏移量学习方式,使其能够自适应地采样重要的空间位置;3) 状态空间模型的参数初始化策略,以避免训练初期出现梯度消失或爆炸问题。此外,损失函数也采用了常用的Smooth L1 loss,以提高姿态估计的精度。
🖼️ 关键图片

📊 实验亮点
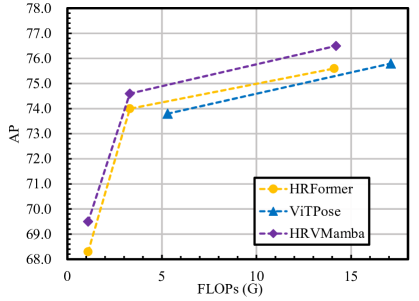
实验结果表明,HRVMamba在人体姿态估计任务上取得了具有竞争力的性能,在COCO数据集上达到了接近SOTA的精度,同时保持了较低的计算复杂度。与ViT和传统SSM模型相比,HRVMamba在参数量和计算量方面具有显著优势,尤其是在高分辨率输入下。
🎯 应用场景
该研究成果可广泛应用于人体姿态估计、动作识别、视频分析等领域。尤其是在资源受限的移动设备或嵌入式平台上,HRVMamba的高效性和高分辨率表示能力使其具有重要的应用价值。未来,该方法有望扩展到其他密集预测任务,如语义分割、目标检测等。
📄 摘要(原文)
Capturing long-range dependencies while preserving high-resolution visual representations is crucial for dense prediction tasks such as human pose estimation. Vision Transformers (ViTs) have advanced global modeling through self-attention but suffer from quadratic computational complexity with respect to token count, limiting their efficiency and scalability to high-resolution inputs, especially on mobile and resource-constrained devices. State Space Models (SSMs), exemplified by Mamba, offer an efficient alternative by combining global receptive fields with linear computational complexity, enabling scalable and resource-friendly sequence modeling. However, when applied to dense prediction tasks, existing visual SSMs face key limitations: weak spatial inductive bias, long-range forgetting from hidden state decay, and low-resolution outputs that hinder fine-grained localization. To address these issues, we propose the Dynamic Visual State Space (DVSS) block, which augments visual state space models with multi-scale convolutional operations to enhance local spatial representations and strengthen spatial inductive biases. Through architectural exploration and theoretical analysis, we incorporate deformable operation into the DVSS block, identifying it as an efficient and effective mechanism to enhance semantic aggregation and mitigate long-range forgetting via input-dependent, adaptive spatial sampling. We embed DVSS into a multi-branch high-resolution architecture to build HRVMamba, a novel model for efficient high-resolution representation learning. Extensive experiments on human pose estimation, image classification, and semantic segmentation show that HRVMamba performs competitively against leading CNN-, ViT-, and SSM-based baselines. Code is available at https://github.com/zhanghao5201/PoseVMamba.