ARB-LLM: Alternating Refined Binarizations for Large Language Models
作者: Zhiteng Li, Xianglong Yan, Tianao Zhang, Haotong Qin, Dong Xie, Jiang Tian, zhongchao shi, Linghe Kong, Yulun Zhang, Xiaokang Yang
分类: cs.CV, cs.AI, cs.CL, cs.LG
发布日期: 2024-10-04 (更新: 2024-10-10)
备注: The code and models will be available at https://github.com/ZHITENGLI/ARB-LLM
🔗 代码/项目: GITHUB
💡 一句话要点
提出ARB-LLM,通过交替优化二值化参数实现大语言模型的高效1比特量化
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 二值化 后训练量化 模型压缩 低精度计算
📋 核心要点
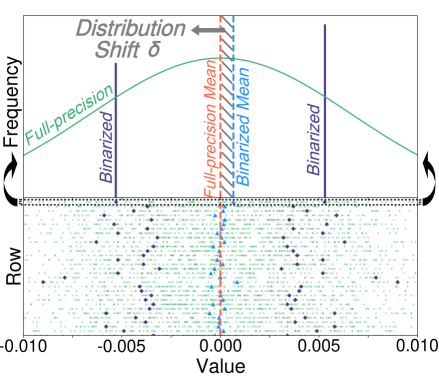
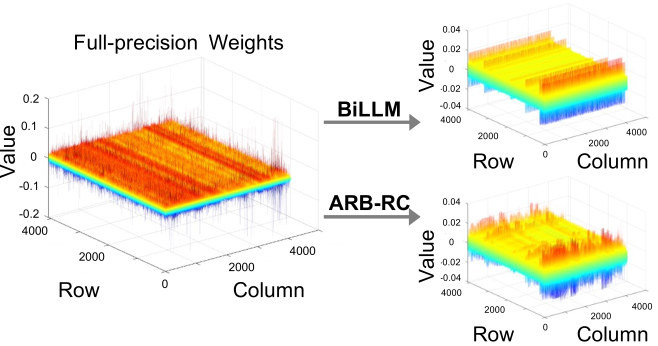
- 现有LLM二值化方法难以有效缩小二值化权重与全精度权重之间的分布差距,并且忽略了LLM权重分布中的列偏差。
- 提出ARB-LLM,通过交替优化二值化参数,并考虑校准数据和列偏差,来减小量化误差,提升二值化LLM的性能。
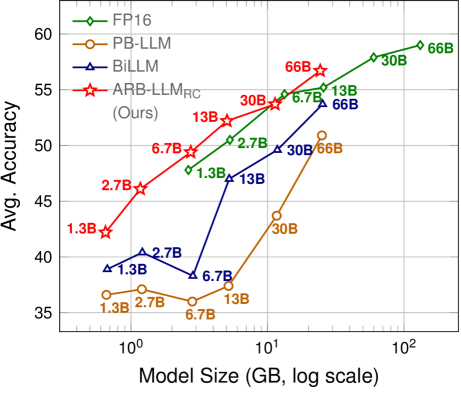
- 实验表明,ARB-LLM显著优于SOTA的LLM二值化方法,并且ARB-LLM$_ ext{RC}$首次在二值PTQ中超越了同等规模的FP16模型。
📝 摘要(中文)
大语言模型(LLMs)在自然语言处理领域取得了显著进展,但其高内存和计算需求阻碍了实际部署。二值化作为一种有效的压缩技术,可以将模型权重压缩到仅1比特,从而显著降低对计算和内存的需求。然而,当前的二值化方法难以缩小二值化权重与全精度权重之间的分布差距,同时也忽略了LLM权重分布中的列偏差。为了解决这些问题,我们提出了一种新颖的1比特后训练量化(PTQ)技术ARB-LLM,专为LLMs设计。为了缩小二值化权重与全精度权重之间的分布差异,我们首先设计了一种交替优化二值化(ARB)算法来逐步更新二值化参数,从而显著降低量化误差。此外,考虑到校准数据和LLM权重中的列偏差的关键作用,我们进一步将ARB扩展到ARB-X和ARB-RC。此外,我们使用列组位图(CGB)改进了权重划分策略,从而进一步提高了性能。通过为ARB-X和ARB-RC配备CGB,我们分别获得了ARB-LLM$ ext{X}$和ARB-LLM$ ext{RC}$,它们显著优于最先进的(SOTA)LLM二值化方法。作为一种二值PTQ方法,我们的ARB-LLM$_ ext{RC}$是第一个超过相同大小的FP16模型的。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLM)部署时面临的巨大内存和计算资源需求问题。现有的二值化方法虽然能有效压缩模型,但存在两个主要痛点:一是二值化后的权重与原始全精度权重之间存在较大的分布差异,导致精度损失;二是忽略了LLM权重分布中存在的列偏差,进一步影响了量化效果。
核心思路:论文的核心思路是通过一种交替优化的二值化方法(ARB)来逐步缩小二值化权重与全精度权重之间的分布差异,从而降低量化误差。同时,考虑到校准数据的重要性以及LLM权重分布的列偏差,对ARB进行扩展,使其更适应LLM的特性。
技术框架:ARB-LLM的整体框架包括以下几个主要部分:1)交替优化二值化(ARB):通过迭代更新二值化参数,逐步逼近全精度权重分布。2)ARB扩展(ARB-X和ARB-RC):分别考虑校准数据和列偏差,对ARB进行改进。3)列组位图(CGB):优化权重划分策略,进一步提升性能。最终得到ARB-LLM$ ext{X}$和ARB-LLM$ ext{RC}$两种变体。
关键创新:论文的主要创新在于提出了交替优化二值化(ARB)算法,该算法通过迭代的方式逐步优化二值化参数,从而更有效地减小量化误差。与传统的二值化方法相比,ARB能够更好地保留原始权重的信息,从而提高二值化模型的精度。此外,针对LLM的特性,论文还提出了ARB-X和ARB-RC两种扩展,进一步提升了性能。
关键设计:ARB算法的关键在于交替更新二值化参数。具体的更新方式(例如,如何计算梯度、如何更新参数)在论文中应该有详细描述。此外,ARB-X和ARB-RC的关键设计在于如何利用校准数据和列偏差信息来指导二值化过程。CGB的设计细节(例如,如何进行列分组、如何使用位图)也是重要的技术细节。
🖼️ 关键图片
📊 实验亮点
ARB-LLM在LLM二值化任务上取得了显著的性能提升。特别是,ARB-LLM$_ ext{RC}$首次在二值PTQ中超越了同等规模的FP16模型,这是一个重要的突破。实验结果表明,ARB-LLM能够有效地降低量化误差,提高二值化模型的精度,为LLM的轻量化部署提供了新的解决方案。
🎯 应用场景
ARB-LLM具有广泛的应用前景,尤其是在资源受限的场景下部署大型语言模型。例如,它可以应用于移动设备、嵌入式系统等,使得这些设备也能运行复杂的LLM应用。此外,ARB-LLM还可以用于降低云计算平台的LLM部署成本,提高资源利用率。未来,该技术有望推动LLM在更多领域的普及和应用。
📄 摘要(原文)
Large Language Models (LLMs) have greatly pushed forward advancements in natural language processing, yet their high memory and computational demands hinder practical deployment. Binarization, as an effective compression technique, can shrink model weights to just 1 bit, significantly reducing the high demands on computation and memory. However, current binarization methods struggle to narrow the distribution gap between binarized and full-precision weights, while also overlooking the column deviation in LLM weight distribution. To tackle these issues, we propose ARB-LLM, a novel 1-bit post-training quantization (PTQ) technique tailored for LLMs. To narrow the distribution shift between binarized and full-precision weights, we first design an alternating refined binarization (ARB) algorithm to progressively update the binarization parameters, which significantly reduces the quantization error. Moreover, considering the pivot role of calibration data and the column deviation in LLM weights, we further extend ARB to ARB-X and ARB-RC. In addition, we refine the weight partition strategy with column-group bitmap (CGB), which further enhance performance. Equipping ARB-X and ARB-RC with CGB, we obtain ARB-LLM$\text{X}$ and ARB-LLM$\text{RC}$ respectively, which significantly outperform state-of-the-art (SOTA) binarization methods for LLMs. As a binary PTQ method, our ARB-LLM$_\text{RC}$ is the first to surpass FP16 models of the same size. The code and models will be available at https://github.com/ZHITENGLI/ARB-LLM.