LLaVA-Critic: Learning to Evaluate Multimodal Models
作者: Tianyi Xiong, Xiyao Wang, Dong Guo, Qinghao Ye, Haoqi Fan, Quanquan Gu, Heng Huang, Chunyuan Li
分类: cs.CV, cs.CL
发布日期: 2024-10-03 (更新: 2025-03-04)
备注: Accepted by CVPR 2025; Project Page: https://llava-vl.github.io/blog/2024-10-03-llava-critic
💡 一句话要点
提出LLaVA-Critic,一个用于评估多模态模型性能的通用评估器。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态模型评估 大型语言模型 指令跟随 偏好学习 模型对齐
📋 核心要点
- 现有LMM缺乏有效的自动评估机制,依赖人工评估成本高昂且主观。
- LLaVA-Critic通过训练一个专门的LMM来学习评估其他LMM的输出质量,模拟人类评估过程。
- 实验证明LLaVA-Critic在评估任务上与GPT模型性能相当,并能用于偏好学习,提升模型对齐能力。
📝 摘要(中文)
本文介绍了LLaVA-Critic,这是首个开源的大型多模态模型(LMM),旨在作为通用评估器,评估各种多模态任务的性能。LLaVA-Critic使用高质量的评论员指令跟随数据集进行训练,该数据集融合了多样化的评估标准和场景。实验表明,该模型在两个关键领域表现出色:(1)LMM-as-a-Judge,LLaVA-Critic提供可靠的评估分数,在多个评估基准上与GPT模型相当或超越;(2)偏好学习,它为偏好学习生成奖励信号,增强模型对齐能力。这项工作强调了开源LMM在自我批评和评估方面的潜力,为未来研究LMM的可扩展、超人对齐反馈机制奠定了基础。
🔬 方法详解
问题定义:论文旨在解决大型多模态模型(LMM)的自动评估问题。现有方法主要依赖人工评估,成本高昂且主观性强,难以支持LMM的快速迭代和优化。因此,需要一种能够自动、可靠地评估LMM性能的方法。
核心思路:论文的核心思路是训练一个专门的LMM,即LLaVA-Critic,使其能够像人类评估者一样,根据给定的输入(包括图像、文本和模型输出)进行评估并给出评分或偏好。这种方法将评估过程转化为一个多模态理解和推理问题。
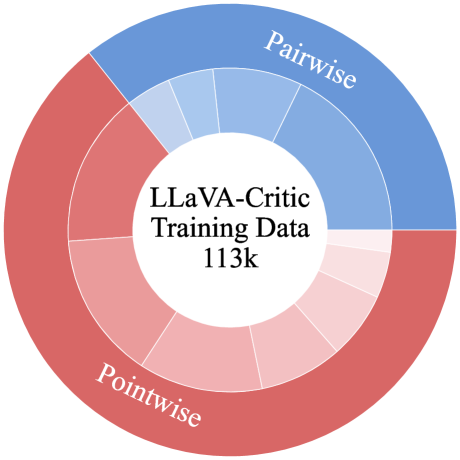
技术框架:LLaVA-Critic的整体架构基于现有的LLaVA模型,并在此基础上进行了改进和扩展。主要流程包括:1) 使用高质量的评论员指令跟随数据集对LLaVA-Critic进行训练,该数据集包含多样化的评估标准和场景;2) 将待评估的LMM的输入和输出提供给LLaVA-Critic;3) LLaVA-Critic根据输入进行评估,并生成评估分数或偏好排序。
关键创新:该论文的关键创新在于提出了一个专门用于评估其他LMM的开源LMM。与传统的评估方法相比,LLaVA-Critic能够自动、高效地评估LMM的性能,并且可以根据不同的评估标准进行定制。此外,LLaVA-Critic还可以用于偏好学习,为LMM的对齐提供奖励信号。
关键设计:LLaVA-Critic的关键设计包括:1) 高质量的评论员指令跟随数据集,该数据集包含了多样化的评估标准和场景,例如准确性、相关性、一致性等;2) 使用对比学习损失函数来训练LLaVA-Critic,使其能够区分不同质量的LMM输出;3) 将LLaVA-Critic的输出作为奖励信号,用于偏好学习,以提升LMM的对齐能力。具体的参数设置和网络结构细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
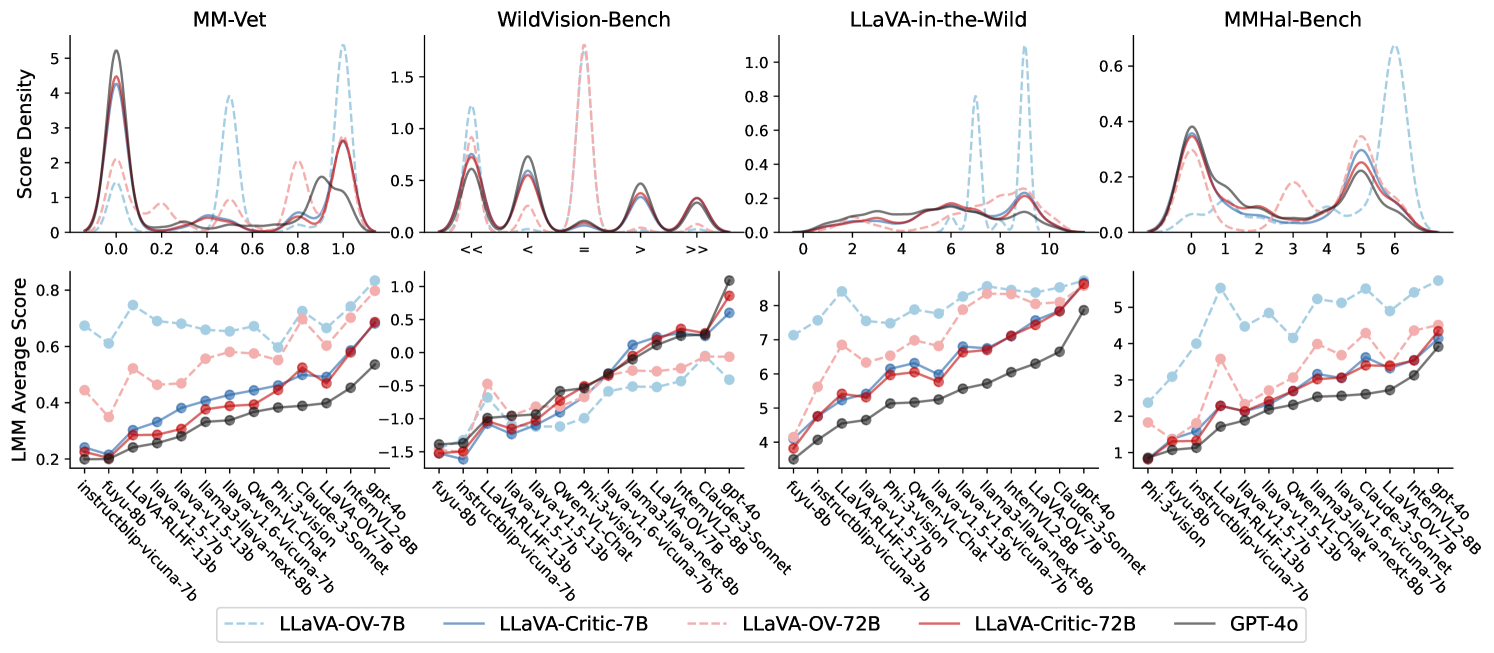
实验结果表明,LLaVA-Critic在LMM-as-a-Judge任务中,能够提供可靠的评估分数,其性能与GPT模型相当甚至超越。此外,LLaVA-Critic生成的奖励信号能够有效提升LMM的对齐能力,表明其在偏好学习方面具有潜力。具体的性能数据和提升幅度未在摘要中详细说明,属于未知信息。
🎯 应用场景
LLaVA-Critic可应用于LMM的自动评估、模型选择、超参数优化和偏好学习等领域。它能够降低LMM开发和维护的成本,加速LMM的迭代速度,并提升LMM的性能和对齐能力。此外,该研究为构建可扩展的、超人LMM对齐反馈机制奠定了基础。
📄 摘要(原文)
We introduce LLaVA-Critic, the first open-source large multimodal model (LMM) designed as a generalist evaluator to assess performance across a wide range of multimodal tasks. LLaVA-Critic is trained using a high-quality critic instruction-following dataset that incorporates diverse evaluation criteria and scenarios. Our experiments demonstrate the model's effectiveness in two key areas: (1) LMM-as-a-Judge, where LLaVA-Critic provides reliable evaluation scores, performing on par with or surpassing GPT models on multiple evaluation benchmarks; and (2) Preference Learning, where it generates reward signals for preference learning, enhancing model alignment capabilities. This work underscores the potential of open-source LMMs in self-critique and evaluation, setting the stage for future research into scalable, superhuman alignment feedback mechanisms for LMMs.