RESSCAL3D++: Joint Acquisition and Semantic Segmentation of 3D Point Clouds
作者: Remco Royen, Kostas Pataridis, Ward van der Tempel, Adrian Munteanu
分类: cs.CV
发布日期: 2024-10-03
备注: 2024 IEEE International Conference on Image Processing (ICIP). IEEE, 2024
DOI: 10.1109/ICIP51287.2024.10647742
🔗 代码/项目: GITHUB
💡 一句话要点
提出RESSCAL3D++,用于联合获取和语义分割可扩展分辨率的3D点云,显著提升效率。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D点云 语义分割 分辨率可扩展 联合采集处理 实时场景理解
📋 核心要点
- 现有3D场景理解方法通常将数据采集和处理分离,导致资源浪费和实时性不足,限制了设备与物理世界的交互。
- RESSCAL3D++通过联合优化数据采集和语义分割,利用分辨率可扩展的3D传感器,在数据获取的同时启动处理,实现更高效的3D场景理解。
- 实验表明,RESSCAL3D++在VX-S3DIS数据集上显著降低了可扩展性成本,加速了处理速度,并实现了早期预测,提升了实时性。
📝 摘要(中文)
本文提出了一种用于3D场景理解的方法,旨在促进数字设备与物理世界之间的无缝交互。实时捕获和处理3D场景对于实现这种无缝集成至关重要。现有方法通常为每个帧分离采集和处理,而分辨率可扩展的3D传感器的出现提供了一个机会,可以克服这种模式,并充分利用原本浪费的采集时间来启动处理。本文介绍了VX-S3DIS,这是一个新的点云数据集,精确地模拟了分辨率可扩展3D传感器的行为。此外,本文还提出了RESSCAL3D++,这是对先前工作RESSCAL3D的重要改进,通过结合更新模块和处理策略。通过将该方法应用于新数据集,实际证明了联合采集和语义分割3D点云的潜力。与非可扩展基线相比,该方法显著降低了可扩展性成本,从2%降至0.2%的mIoU,同时实现了15.6%至63.9%的加速。此外,该方法能够进行早期预测,第一次预测仅在基线总推理时间的7%后发生。新的VX-S3DIS数据集已在GitHub上提供。
🔬 方法详解
问题定义:现有3D场景理解方法通常将3D数据的采集和处理分离,导致采集过程中产生的空闲时间无法被有效利用。尤其是在需要不同分辨率数据进行处理的场景下,传统方法效率低下,难以满足实时性要求。因此,如何充分利用采集时间,实现高效的3D场景理解是本文要解决的核心问题。
核心思路:本文的核心思路是联合优化3D数据的采集和语义分割过程。通过使用分辨率可扩展的3D传感器,在数据采集的同时启动语义分割处理,从而充分利用采集时间,提高整体效率。这种方法允许在数据完全采集之前进行早期预测,进一步提升了实时性。
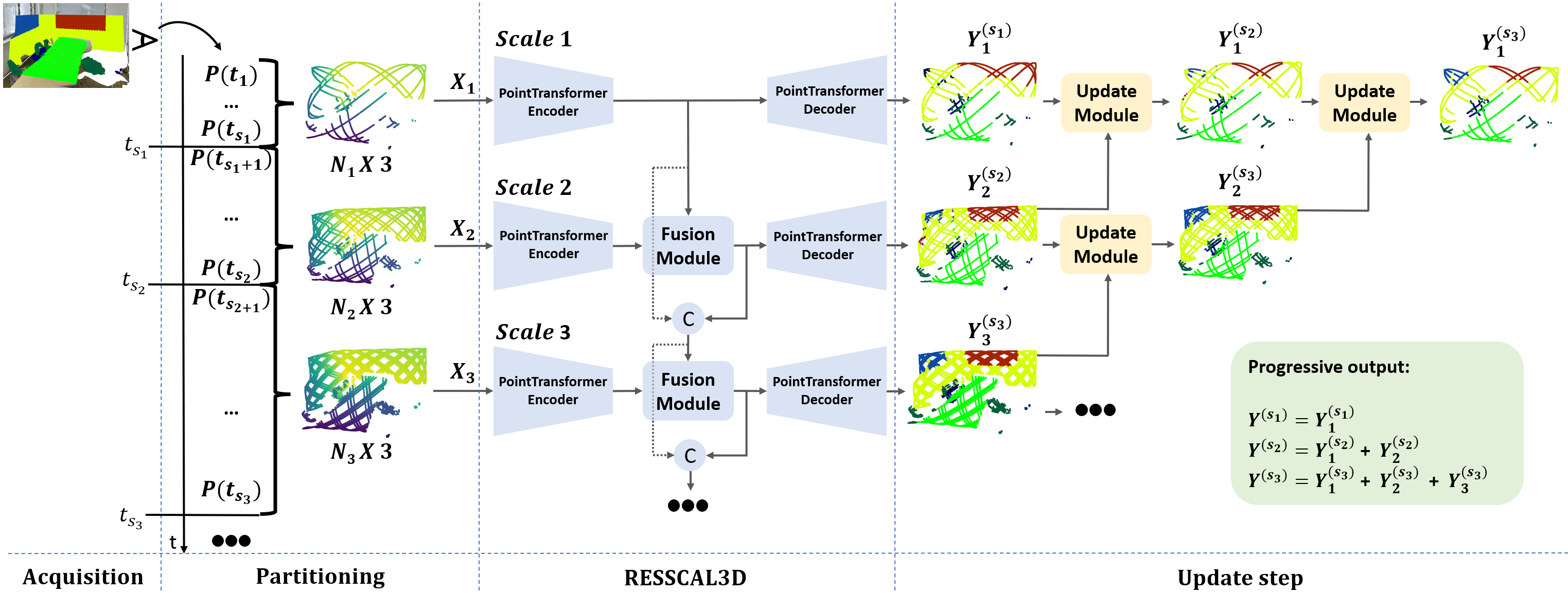
技术框架:RESSCAL3D++的整体框架包含以下几个主要模块:1) 分辨率可扩展的3D传感器模拟器,用于生成VX-S3DIS数据集;2) 渐进式点云处理模块,用于在数据采集的不同阶段进行语义分割;3) 更新模块,用于融合不同分辨率下的分割结果,提高分割精度。整个流程从低分辨率数据开始,逐步提高分辨率,并不断更新分割结果,最终得到高精度的语义分割结果。
关键创新:RESSCAL3D++的关键创新在于其联合采集和处理的策略,以及更新模块的设计。传统的pipeline将采集和处理分离,而RESSCAL3D++通过分辨率可扩展的传感器模拟和渐进式处理,实现了二者的紧密结合。更新模块则能够有效地融合不同分辨率下的信息,提升分割精度,这是与现有方法的本质区别。
关键设计:RESSCAL3D++的关键设计包括:1) VX-S3DIS数据集的构建,该数据集模拟了分辨率可扩展传感器的输出;2) 渐进式处理模块的网络结构,该结构能够适应不同分辨率的输入;3) 更新模块的融合策略,该策略决定了如何将不同分辨率下的分割结果进行有效融合。具体的网络结构和融合策略在论文中进行了详细描述,但此处无法提供具体参数。
🖼️ 关键图片


📊 实验亮点
RESSCAL3D++在VX-S3DIS数据集上取得了显著的性能提升。与非可扩展基线相比,可扩展性成本从2%降低到0.2%的mIoU,同时实现了15.6%到63.9%的加速。此外,该方法能够在仅占基线总推理时间7%的情况下进行早期预测,显著提升了实时性。这些结果表明,RESSCAL3D++在联合采集和语义分割3D点云方面具有显著优势。
🎯 应用场景
RESSCAL3D++在机器人导航、自动驾驶、增强现实等领域具有广泛的应用前景。通过实时获取和理解3D场景,机器人可以更好地感知周围环境,实现自主导航和避障。在自动驾驶领域,该技术可以提高车辆对周围环境的感知能力,提升驾驶安全性。在增强现实领域,该技术可以实现更逼真的虚拟物体与真实场景的融合。
📄 摘要(原文)
3D scene understanding is crucial for facilitating seamless interaction between digital devices and the physical world. Real-time capturing and processing of the 3D scene are essential for achieving this seamless integration. While existing approaches typically separate acquisition and processing for each frame, the advent of resolution-scalable 3D sensors offers an opportunity to overcome this paradigm and fully leverage the otherwise wasted acquisition time to initiate processing. In this study, we introduce VX-S3DIS, a novel point cloud dataset accurately simulating the behavior of a resolution-scalable 3D sensor. Additionally, we present RESSCAL3D++, an important improvement over our prior work, RESSCAL3D, by incorporating an update module and processing strategy. By applying our method to the new dataset, we practically demonstrate the potential of joint acquisition and semantic segmentation of 3D point clouds. Our resolution-scalable approach significantly reduces scalability costs from 2% to just 0.2% in mIoU while achieving impressive speed-ups of 15.6 to 63.9% compared to the non-scalable baseline. Furthermore, our scalable approach enables early predictions, with the first one occurring after only 7% of the total inference time of the baseline. The new VX-S3DIS dataset is available at https://github.com/remcoroyen/vx-s3dis.