Depth Pro: Sharp Monocular Metric Depth in Less Than a Second
作者: Aleksei Bochkovskii, Amaël Delaunoy, Hugo Germain, Marcel Santos, Yichao Zhou, Stephan R. Richter, Vladlen Koltun
分类: cs.CV, cs.LG
发布日期: 2024-10-02 (更新: 2025-04-21)
备注: Published at ICLR 2025. Code and weights available at https://github.com/apple/ml-depth-pro
🔗 代码/项目: GITHUB
💡 一句话要点
Depth Pro:亚秒级生成高精度单目度量深度图
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 单目深度估计 度量深度 视觉Transformer 多尺度学习 深度学习 零样本学习 边界精度
📋 核心要点
- 现有单目深度估计方法在生成高分辨率、高精度深度图方面存在挑战,尤其是在保持边界清晰度方面。
- Depth Pro通过结合高效的多尺度视觉Transformer和混合数据集训练策略,实现了快速且精确的深度估计。
- 实验结果表明,Depth Pro在深度图的清晰度、精度和速度方面均优于现有方法,并提供了绝对尺度的度量深度。
📝 摘要(中文)
本文提出了一种用于零样本度量单目深度估计的基础模型,名为Depth Pro。该模型能够合成具有无与伦比的清晰度和高频细节的高分辨率深度图。预测结果是度量的,具有绝对尺度,无需依赖相机内参等元数据。该模型速度很快,在标准GPU上只需0.3秒即可生成225万像素的深度图。这些特性得益于多项技术贡献,包括用于密集预测的高效多尺度视觉Transformer、结合真实和合成数据集以实现高精度和精细边界追踪的训练协议、用于评估深度图边界精度的专用评估指标,以及最先进的单图像焦距估计。大量的实验分析了具体的设计选择,并证明Depth Pro在多个维度上优于以往的工作。代码和权重已开源。
🔬 方法详解
问题定义:单目深度估计旨在从单个图像中预测场景的深度信息。现有方法通常依赖于大量标注数据或特定的相机参数,且难以在速度和精度之间取得平衡,尤其是在生成高分辨率深度图时,边界模糊问题尤为突出。
核心思路:Depth Pro的核心在于利用一个高效的多尺度视觉Transformer,结合真实和合成数据进行训练,从而在保证速度的同时,提高深度图的精度和边界清晰度。通过学习真实世界的几何先验知识,模型能够预测具有绝对尺度的度量深度,而无需相机内参。
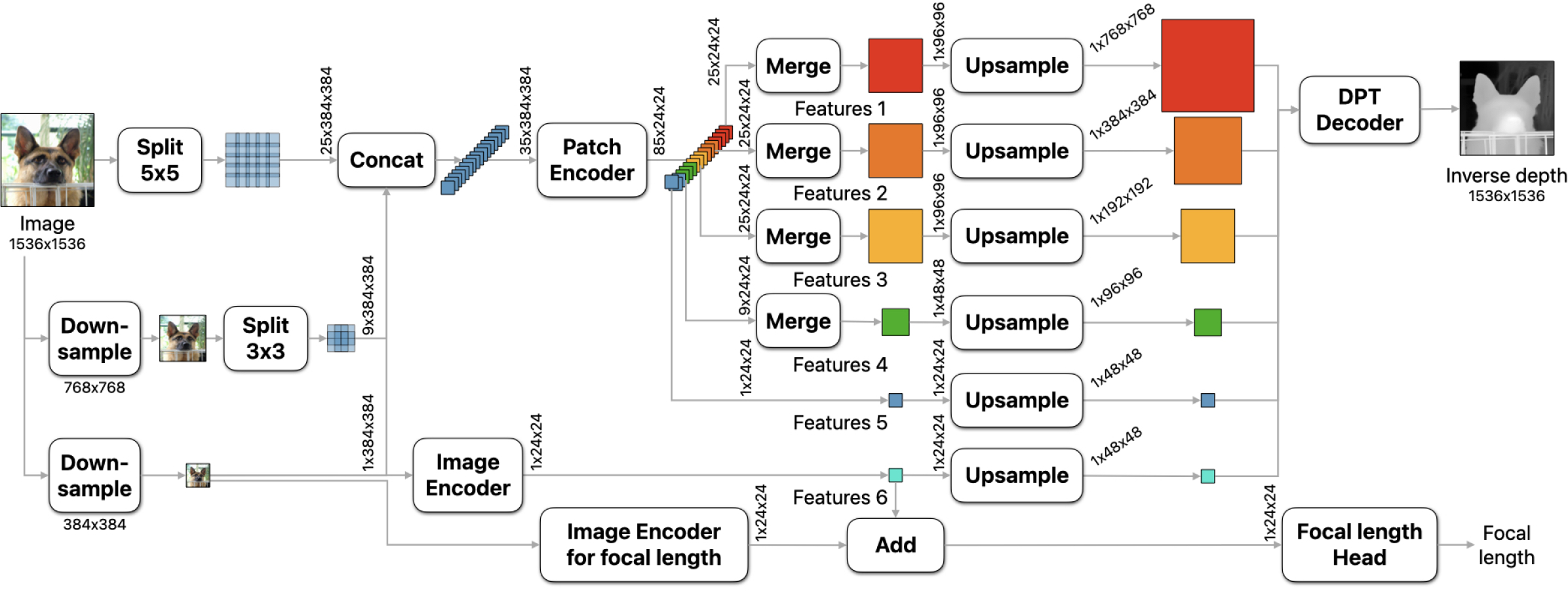
技术框架:Depth Pro的整体框架包含一个多尺度视觉Transformer作为主干网络,用于提取图像特征。该网络采用多尺度设计,能够捕捉不同尺度的上下文信息,从而提高深度估计的准确性。此外,模型还包含一个焦距估计模块,用于从单张图像中估计相机的焦距。训练过程结合了真实和合成数据集,以提高模型的泛化能力和边界精度。
关键创新:Depth Pro的关键创新在于其高效的多尺度视觉Transformer架构和混合数据集训练策略。传统Transformer在处理高分辨率图像时计算量巨大,而Depth Pro通过多尺度设计降低了计算复杂度,使其能够快速生成高分辨率深度图。混合数据集训练策略则结合了真实数据的真实感和合成数据的精确标注,从而提高了模型的精度和边界清晰度。
关键设计:Depth Pro采用了专门设计的损失函数,包括深度损失、梯度损失和边界损失,以提高深度估计的精度和边界清晰度。此外,模型还采用了数据增强技术,如随机裁剪、旋转和颜色抖动,以提高模型的鲁棒性。网络结构方面,多尺度Transformer采用了跳跃连接,以融合不同尺度的特征信息。焦距估计模块的设计也至关重要,它直接影响了深度估计的绝对尺度。
🖼️ 关键图片


📊 实验亮点
Depth Pro在多个数据集上进行了评估,实验结果表明,该模型在深度估计的精度和速度方面均优于现有方法。例如,在标准GPU上,Depth Pro只需0.3秒即可生成225万像素的深度图。此外,Depth Pro在边界精度方面也取得了显著提升,能够生成具有清晰边界的深度图。与现有方法相比,Depth Pro在多个指标上均取得了state-of-the-art的结果。
🎯 应用场景
Depth Pro在机器人导航、自动驾驶、增强现实、虚拟现实等领域具有广泛的应用前景。它可以为机器人提供准确的环境深度信息,帮助它们进行路径规划和避障。在自动驾驶领域,Depth Pro可以用于感知周围环境,提高驾驶安全性。在AR/VR领域,它可以用于创建逼真的3D场景,提升用户体验。此外,该模型还可以应用于三维重建、图像编辑等领域。
📄 摘要(原文)
We present a foundation model for zero-shot metric monocular depth estimation. Our model, Depth Pro, synthesizes high-resolution depth maps with unparalleled sharpness and high-frequency details. The predictions are metric, with absolute scale, without relying on the availability of metadata such as camera intrinsics. And the model is fast, producing a 2.25-megapixel depth map in 0.3 seconds on a standard GPU. These characteristics are enabled by a number of technical contributions, including an efficient multi-scale vision transformer for dense prediction, a training protocol that combines real and synthetic datasets to achieve high metric accuracy alongside fine boundary tracing, dedicated evaluation metrics for boundary accuracy in estimated depth maps, and state-of-the-art focal length estimation from a single image. Extensive experiments analyze specific design choices and demonstrate that Depth Pro outperforms prior work along multiple dimensions. We release code and weights at https://github.com/apple/ml-depth-pro