UlcerGPT: A Multimodal Approach Leveraging Large Language and Vision Models for Diabetic Foot Ulcer Image Transcription
作者: Reza Basiri, Ali Abedi, Chau Nguyen, Milos R. Popovic, Shehroz S. Khan
分类: cs.CV, cs.AI
发布日期: 2024-10-02
备注: 13 pages, 3 figures, ICPR 2024 Conference (PRHA workshop)
💡 一句话要点
UlcerGPT:利用大型语言和视觉模型进行糖尿病足溃疡图像转录的多模态方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 糖尿病足溃疡 图像转录 大型语言模型 视觉模型 多模态学习 远程医疗 医学图像分析
📋 核心要点
- 现有DFU图像分析方法缺乏对图像转录的探索,限制了远程医疗中对溃疡的全面理解和描述。
- UlcerGPT利用大型语言和视觉模型,通过联合检测、分类和定位感兴趣区域来转录DFU图像,实现更细致的分析。
- 实验结果表明,UlcerGPT在DFU转录的准确性和效率方面表现出潜力,有望辅助临床医生进行远程诊断。
📝 摘要(中文)
糖尿病足溃疡(DFU)是住院和下肢截肢的主要原因,给患者和医疗系统带来沉重负担。早期检测和准确分类DFU对于预防严重并发症至关重要,但由于获得专业服务的机会有限,许多患者在接受治疗方面存在延误。远程医疗已成为一种有前景的解决方案,改善了就医机会并减少了面对面就诊的需求。人工智能和模式识别融入远程医疗,通过自动检测、分类和图像监控,进一步加强了DFU管理。尽管人工智能驱动的DFU图像分析方法取得了进展,但尚未探索将大型语言模型应用于DFU图像转录。为了弥补这一差距,我们推出UlcerGPT,这是一种新颖的多模态方法,利用大型语言和视觉模型进行DFU图像转录。该框架结合了先进的视觉和语言模型,例如Large Language and Vision Assistant和Chat Generative Pre-trained Transformer,通过联合检测、分类和定位感兴趣区域来转录DFU图像。通过在公共数据集上进行的详细实验,并由专家临床医生评估,UlcerGPT在DFU转录的准确性和效率方面表现出令人鼓舞的结果,为临床医生通过远程医疗提供及时护理提供潜在支持。
🔬 方法详解
问题定义:论文旨在解决糖尿病足溃疡(DFU)图像转录问题。现有方法主要集中在DFU的检测和分类,缺乏对溃疡区域的详细描述和转录,这限制了远程医疗场景下医生对病情的全面了解。现有方法无法有效利用大型语言模型来生成关于溃疡特征的自然语言描述。
核心思路:论文的核心思路是利用大型语言和视觉模型(LLVMs)的强大能力,将DFU图像转化为结构化的文本描述。通过联合检测、分类和定位溃疡区域,并利用语言模型生成相应的文本,从而实现对DFU图像的全面转录。这种方法旨在弥合图像分析和自然语言理解之间的差距,为临床医生提供更丰富的信息。
技术框架:UlcerGPT框架主要包含以下几个模块:1) 图像输入模块:接收DFU图像作为输入。2) 视觉特征提取模块:使用预训练的视觉模型(如Vision Transformer)提取图像的视觉特征。3) 区域检测与分类模块:检测并分类图像中的溃疡区域。4) 语言模型生成模块:使用大型语言模型(如Chat Generative Pre-trained Transformer)根据视觉特征和区域信息生成文本描述。5) 输出模块:输出DFU图像的转录文本。
关键创新:该论文的关键创新在于将大型语言模型应用于DFU图像转录。与传统的图像分析方法不同,UlcerGPT不仅能够检测和分类溃疡,还能生成关于溃疡特征的自然语言描述,从而提供更全面的信息。此外,该方法结合了视觉和语言模型,实现了多模态信息的融合。
关键设计:UlcerGPT使用了Large Language and Vision Assistant (LLaVA) 和 Chat Generative Pre-trained Transformer (ChatGPT) 等模型。具体的技术细节包括:视觉特征提取器的选择、区域检测与分类器的训练、语言模型的微调策略,以及如何将视觉特征和区域信息有效地输入到语言模型中。损失函数的设计可能包括检测损失、分类损失和语言生成损失,以优化模型的性能。具体的网络结构和参数设置在论文中可能没有详细公开,属于技术实现细节。
🖼️ 关键图片

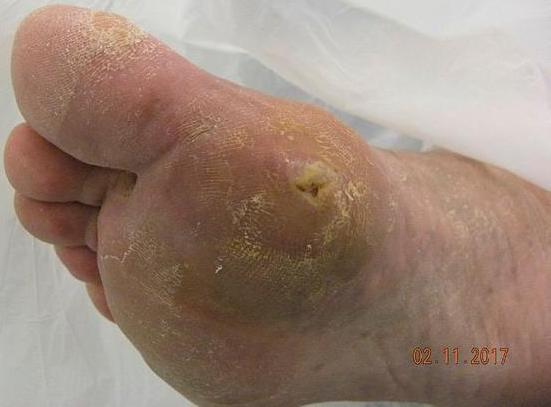

📊 实验亮点
UlcerGPT在公共数据集上进行了实验,并由专家临床医生评估。实验结果表明,UlcerGPT在DFU转录的准确性和效率方面表现出令人鼓舞的结果。具体的性能数据(如准确率、召回率等)和对比基线(如传统图像分析方法)的性能对比需要在论文中查找。该研究验证了大型语言和视觉模型在医学图像转录方面的潜力。
🎯 应用场景
UlcerGPT可应用于远程医疗、智能诊断辅助系统等领域,帮助医生更准确、高效地评估DFU病情,尤其是在医疗资源匮乏的地区。该研究有助于提高DFU的早期诊断率,减少截肢风险,改善患者生活质量。未来,该技术有望扩展到其他医学图像分析任务,推动人工智能在医疗领域的应用。
📄 摘要(原文)
Diabetic foot ulcers (DFUs) are a leading cause of hospitalizations and lower limb amputations, placing a substantial burden on patients and healthcare systems. Early detection and accurate classification of DFUs are critical for preventing serious complications, yet many patients experience delays in receiving care due to limited access to specialized services. Telehealth has emerged as a promising solution, improving access to care and reducing the need for in-person visits. The integration of artificial intelligence and pattern recognition into telemedicine has further enhanced DFU management by enabling automatic detection, classification, and monitoring from images. Despite advancements in artificial intelligence-driven approaches for DFU image analysis, the application of large language models for DFU image transcription has not yet been explored. To address this gap, we introduce UlcerGPT, a novel multimodal approach leveraging large language and vision models for DFU image transcription. This framework combines advanced vision and language models, such as Large Language and Vision Assistant and Chat Generative Pre-trained Transformer, to transcribe DFU images by jointly detecting, classifying, and localizing regions of interest. Through detailed experiments on a public dataset, evaluated by expert clinicians, UlcerGPT demonstrates promising results in the accuracy and efficiency of DFU transcription, offering potential support for clinicians in delivering timely care via telemedicine.