Class-Agnostic Visio-Temporal Scene Sketch Semantic Segmentation
作者: Aleyna Kütük, Tevfik Metin Sezgin
分类: cs.CV, cs.LG
发布日期: 2024-09-30
💡 一句话要点
提出类无关时序视觉网络CAVT,用于场景草图的语义分割,并构建了大规模数据集FrISS。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 场景草图分割 语义分割 类无关学习 时序信息 实例分割
📋 核心要点
- 现有草图分割方法忽略了笔画的时序信息,且泛化能力不足,难以分割未见过的类别。
- CAVT网络利用类无关对象检测器检测实例,并结合后处理模块实现笔画分组,进行实例和笔画级别的分割。
- 构建了大规模手绘场景草图数据集FrISS,实验证明CAVT在多个数据集上优于现有方法。
📝 摘要(中文)
场景草图语义分割对于草图到图像的检索和场景理解等应用至关重要。现有的草图分割方法将草图视为位图图像,导致笔画之间的时间顺序丢失。此外,这些方法难以分割训练数据中不存在的类别对象。本文提出了一种类无关时序视觉网络(CAVT)用于场景草图语义分割。CAVT采用类无关对象检测器来检测场景中的单个对象,并通过后处理模块对实例的笔画进行分组。这是第一个在场景草图中执行实例和笔画级别分割的方法。此外,缺乏具有实例和笔画级别类别标注的手绘场景草图数据集。为了填补这一空白,我们收集了最大的手绘实例和笔画级别场景草图数据集(FrISS),其中包含1K个场景草图,涵盖403个对象类别,并具有密集的标注。在FrISS和其他数据集上的大量实验表明,我们的方法优于最先进的场景草图分割模型。
🔬 方法详解
问题定义:现有场景草图语义分割方法主要存在两个痛点:一是将矢量草图转换为位图图像,丢失了笔画的时序信息;二是模型泛化能力不足,难以分割训练集中未出现的类别。
核心思路:论文的核心思路是设计一个类无关的分割框架,避免对特定类别的依赖,从而提高模型的泛化能力。同时,利用笔画的时序信息,辅助实例分割,提高分割精度。
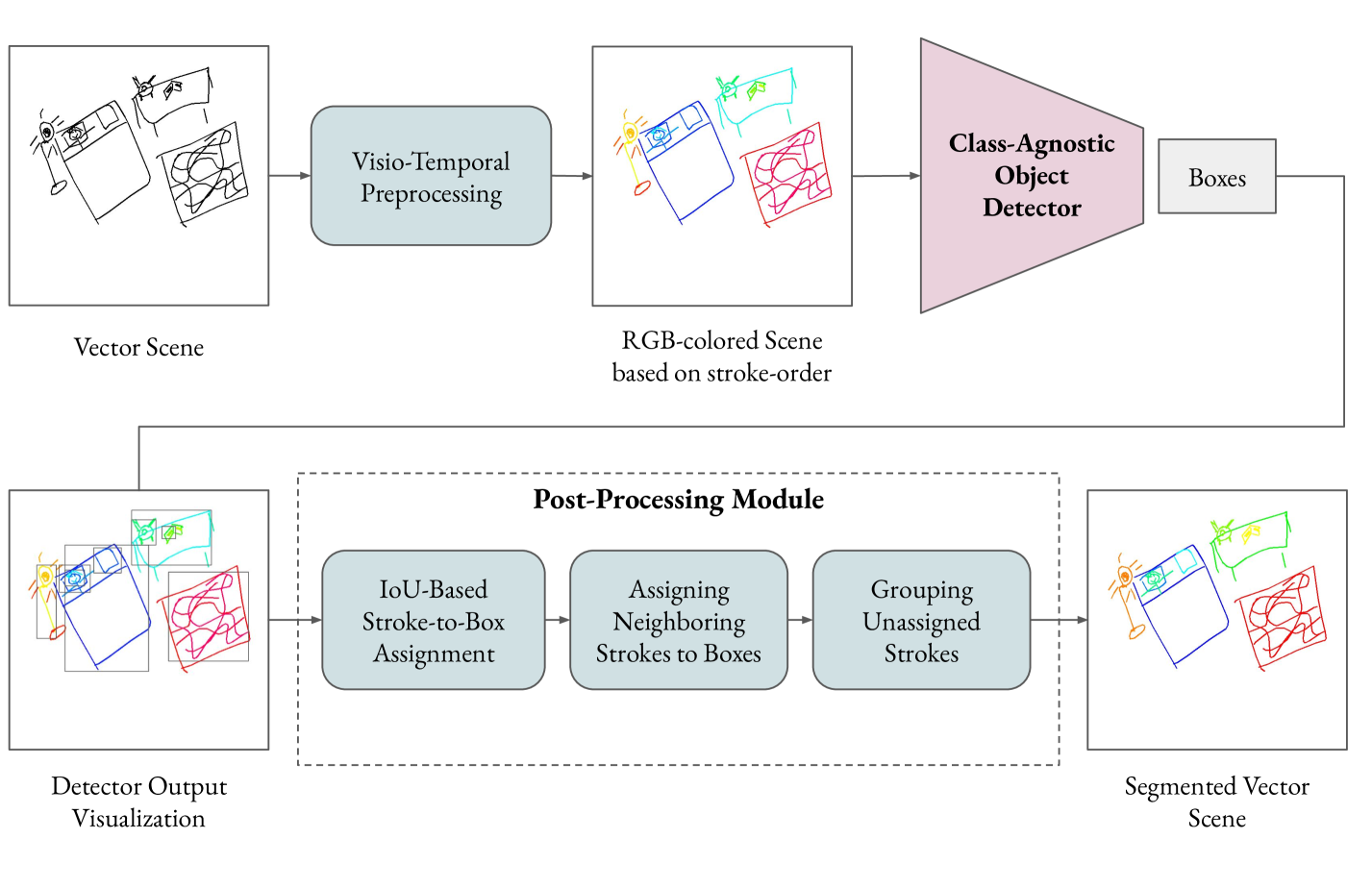
技术框架:CAVT网络主要包含以下几个模块:1) 类无关对象检测器:用于检测场景中的各个对象实例,不依赖于预定义的类别信息。2) 笔画分组模块:利用笔画的时序信息,将属于同一实例的笔画进行分组。3) 后处理模块:对检测结果进行优化,例如去除冗余检测框,调整分割边界等。
关键创新:该方法最大的创新点在于提出了一个类无关的场景草图分割框架,能够有效分割未见过的类别。同时,该方法是首个在场景草图中同时进行实例级别和笔画级别分割的方法。
关键设计:CAVT网络的关键设计包括:1) 使用类无关对象检测器,例如基于Mask R-CNN的变体,但去除了类别预测分支。2) 设计了基于时序信息的笔画分组算法,例如使用循环神经网络(RNN)对笔画序列进行建模,预测笔画之间的关联性。3) FrISS数据集的构建,提供了大规模的实例和笔画级别的标注数据,为模型训练提供了支持。
🖼️ 关键图片

📊 实验亮点
论文在自建数据集FrISS以及其他公开数据集上进行了实验,结果表明CAVT网络在场景草图语义分割任务上取得了显著的性能提升,优于现有的state-of-the-art方法。具体的性能数据(例如mAP、IoU等)在摘要中未给出,需要在论文正文中查找。
🎯 应用场景
该研究成果可应用于草图检索、草图辅助设计、人机交互等领域。例如,可以根据用户绘制的草图快速检索相关的图像或3D模型;可以辅助设计师进行场景设计,提高设计效率;可以用于开发更自然、更智能的人机交互界面。
📄 摘要(原文)
Scene sketch semantic segmentation is a crucial task for various applications including sketch-to-image retrieval and scene understanding. Existing sketch segmentation methods treat sketches as bitmap images, leading to the loss of temporal order among strokes due to the shift from vector to image format. Moreover, these methods struggle to segment objects from categories absent in the training data. In this paper, we propose a Class-Agnostic Visio-Temporal Network (CAVT) for scene sketch semantic segmentation. CAVT employs a class-agnostic object detector to detect individual objects in a scene and groups the strokes of instances through its post-processing module. This is the first approach that performs segmentation at both the instance and stroke levels within scene sketches. Furthermore, there is a lack of free-hand scene sketch datasets with both instance and stroke-level class annotations. To fill this gap, we collected the largest Free-hand Instance- and Stroke-level Scene Sketch Dataset (FrISS) that contains 1K scene sketches and covers 403 object classes with dense annotations. Extensive experiments on FrISS and other datasets demonstrate the superior performance of our method over state-of-the-art scene sketch segmentation models. The code and dataset will be made public after acceptance.