MM1.5: Methods, Analysis & Insights from Multimodal LLM Fine-tuning
作者: Haotian Zhang, Mingfei Gao, Zhe Gan, Philipp Dufter, Nina Wenzel, Forrest Huang, Dhruti Shah, Xianzhi Du, Bowen Zhang, Yanghao Li, Sam Dodge, Keen You, Zhen Yang, Aleksei Timofeev, Mingze Xu, Hong-You Chen, Jean-Philippe Fauconnier, Zhengfeng Lai, Haoxuan You, Zirui Wang, Afshin Dehghan, Peter Grasch, Yinfei Yang
分类: cs.CV, cs.CL, cs.LG
发布日期: 2024-09-30
💡 一句话要点
MM1.5:通过数据驱动的多模态LLM微调提升图像理解与多图像推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大型语言模型 视觉理解 数据驱动 图像文本 OCR 视觉推理
📋 核心要点
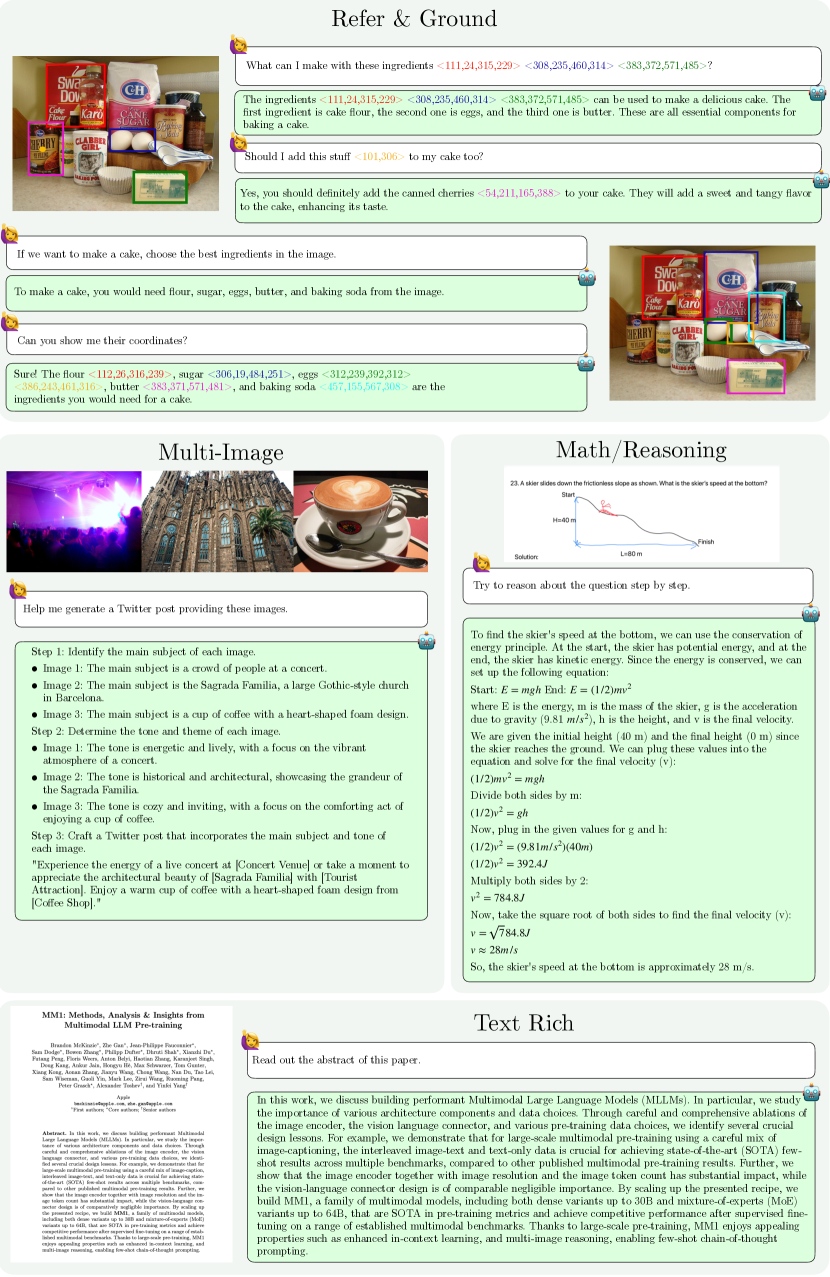
- 现有MLLM在处理文本丰富的图像、视觉指代和多图像推理方面存在不足,需要更有效的数据利用和训练策略。
- MM1.5通过数据为中心的训练方法,探索不同数据混合对模型性能的影响,包括OCR数据、合成字幕和优化的视觉指令调整数据。
- 实验结果表明,即使在参数量较小的模型(1B和3B)上,通过精心的数据管理和训练策略也能获得显著的性能提升。
📝 摘要(中文)
本文介绍了MM1.5,一个旨在增强富文本图像理解、视觉指代与定位以及多图像推理能力的多模态大型语言模型(MLLM)系列。MM1.5建立在MM1架构之上,采用以数据为中心的模型训练方法,系统地探索了不同数据混合对整个模型训练生命周期的影响。这包括用于持续预训练的高质量OCR数据和合成字幕,以及用于监督微调的优化视觉指令调整数据混合。我们的模型参数范围从1B到30B,包含密集型和混合专家(MoE)变体,并证明即使在小规模(1B和3B)下,精心的数据管理和训练策略也能产生强大的性能。此外,我们还引入了两个专门的变体:MM1.5-Video,专为视频理解而设计,以及MM1.5-UI,专为移动UI理解而定制。通过广泛的实证研究和消融实验,我们提供了对训练过程和决策的详细见解,为MLLM开发的未来研究提供了宝贵的指导。
🔬 方法详解
问题定义:现有的多模态大型语言模型在处理复杂视觉任务,特别是涉及文本丰富的图像理解、视觉指代和多图像推理时,仍然面临挑战。痛点在于如何有效地利用各种数据资源,并设计合适的训练策略,以提升模型在这些特定任务上的性能。
核心思路:MM1.5的核心思路是以数据为中心,通过系统地探索不同数据混合方式对模型训练的影响,来提升模型性能。这包括在预训练阶段使用高质量的OCR数据和合成字幕,以及在微调阶段使用优化的视觉指令调整数据。通过这种方式,模型能够更好地理解图像中的文本信息,并进行更准确的视觉推理。
技术框架:MM1.5建立在MM1架构之上,整体框架包括视觉编码器、文本编码器和多模态融合模块。视觉编码器负责提取图像特征,文本编码器负责处理文本信息,多模态融合模块将视觉和文本特征融合,用于下游任务的预测。模型训练分为预训练和微调两个阶段,预训练阶段使用大规模的图像-文本数据,微调阶段使用特定任务的数据。
关键创新:MM1.5的关键创新在于其数据驱动的训练方法。通过系统地探索不同数据混合方式,包括高质量OCR数据、合成字幕和优化的视觉指令调整数据,显著提升了模型在文本丰富的图像理解、视觉指代和多图像推理等任务上的性能。此外,该研究还表明,即使在小规模模型上,通过精心的数据管理和训练策略也能获得强大的性能。
关键设计:在数据方面,MM1.5使用了高质量的OCR数据和合成字幕,以增强模型对图像中文字的理解能力。在训练策略方面,采用了优化的视觉指令调整数据混合,以提升模型在特定任务上的性能。此外,模型还采用了混合专家(MoE)结构,以提高模型的容量和效率。
🖼️ 关键图片


📊 实验亮点
MM1.5在多个视觉任务上取得了显著的性能提升。实验结果表明,即使是参数量较小的模型(1B和3B),通过精心的数据管理和训练策略也能获得强大的性能。此外,MM1.5-Video和MM1.5-UI两个专门的变体在视频理解和移动UI理解任务上也表现出色,证明了该方法的有效性和泛化能力。
🎯 应用场景
MM1.5具有广泛的应用前景,包括智能文档处理、图像搜索、视觉辅助、移动UI理解等领域。例如,它可以用于自动识别和提取文档图像中的文本信息,帮助视力障碍者理解周围环境,以及提升移动应用的用户体验。该研究的成果将推动多模态人工智能技术的发展,并为实际应用带来更多可能性。
📄 摘要(原文)
We present MM1.5, a new family of multimodal large language models (MLLMs) designed to enhance capabilities in text-rich image understanding, visual referring and grounding, and multi-image reasoning. Building upon the MM1 architecture, MM1.5 adopts a data-centric approach to model training, systematically exploring the impact of diverse data mixtures across the entire model training lifecycle. This includes high-quality OCR data and synthetic captions for continual pre-training, as well as an optimized visual instruction-tuning data mixture for supervised fine-tuning. Our models range from 1B to 30B parameters, encompassing both dense and mixture-of-experts (MoE) variants, and demonstrate that careful data curation and training strategies can yield strong performance even at small scales (1B and 3B). Additionally, we introduce two specialized variants: MM1.5-Video, designed for video understanding, and MM1.5-UI, tailored for mobile UI understanding. Through extensive empirical studies and ablations, we provide detailed insights into the training processes and decisions that inform our final designs, offering valuable guidance for future research in MLLM development.