Multimodal Markup Document Models for Graphic Design Completion
作者: Kotaro Kikuchi, Ukyo Honda, Naoto Inoue, Mayu Otani, Edgar Simo-Serra, Kota Yamaguchi
分类: cs.CV, cs.AI, cs.MM
发布日期: 2024-09-27 (更新: 2025-12-04)
备注: Accepted by ACM Multimedia 2025, Project page: https://cyberagentailab.github.io/MarkupDM/
期刊: Proceedings of the 33rd ACM International Conference on Multimedia. 2025. p.11022-11031
💡 一句话要点
提出MarkupDM多模态文档模型,用于图形设计补全任务,实现设计自动化。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 图形设计 文档模型 设计自动化 图像生成
📋 核心要点
- 现有图形设计方法依赖元素属性网格,无法处理可变长度元素和类型相关属性,限制了其灵活性。
- MarkupDM将设计表示为多模态文档,利用中间填充训练补全缺失部分,统一处理多种设计任务。
- 实验表明,MarkupDM在属性值、图像和文本补全任务上表现出色,尤其在指令引导设计补全中优于现有图像编辑模型。
📝 摘要(中文)
本文提出了一种多模态标记文档模型MarkupDM,它将图形设计表示为由标记语言和图像交错组成的多模态文档。与依赖于元素-属性网格表示的现有整体方法不同,我们的表示能够适应可变长度的元素、类型相关的属性和文本内容。受到代码生成中中间填充训练的启发,我们训练模型从周围的上下文中补全设计文档中缺失的部分,从而以统一的方式处理各种设计任务。我们的模型还支持图像生成,通过专门的tokenizer预测离散图像token,该tokenizer支持图像透明度。我们在属性值、图像和文本补全三个任务上评估了MarkupDM,并证明它可以生成与给定上下文一致的合理设计。为了进一步说明我们方法的灵活性,我们在一个新的指令引导的设计补全任务上评估了我们的方法,其中经过指令调整的MarkupDM与最先进的图像编辑模型相比具有优势,尤其是在文本补全方面。这些发现表明,具有我们的文档表示的多模态语言模型可以作为广泛设计自动化的通用基础。
🔬 方法详解
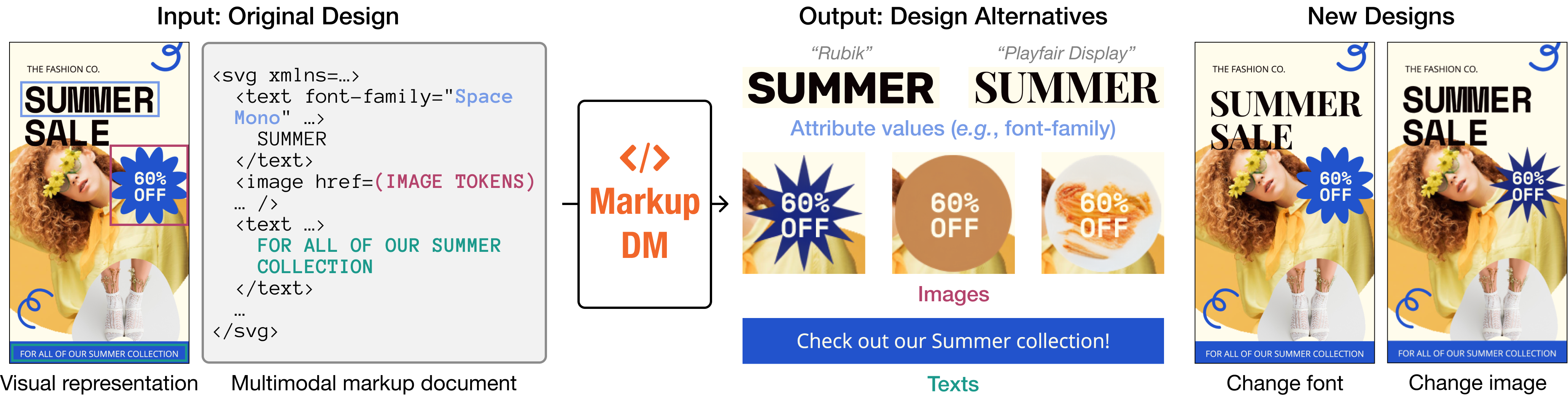
问题定义:论文旨在解决图形设计补全问题,即根据给定的上下文(例如部分标记语言、图像或文本描述)自动完成缺失的设计元素。现有方法通常采用基于元素-属性网格的整体表示,这种表示方式难以处理可变长度的元素、类型相关的属性以及文本内容,限制了模型的表达能力和泛化能力。
核心思路:论文的核心思路是将图形设计视为一个多模态文档,其中包含标记语言(例如HTML、CSS)、图像和文本等多种信息。通过构建一个能够理解和生成这种多模态文档的模型,可以实现对设计元素的灵活控制和补全。受到代码生成领域中“fill-in-the-middle”训练方法的启发,论文采用类似的方式训练模型,使其能够根据周围的上下文预测缺失的设计元素。
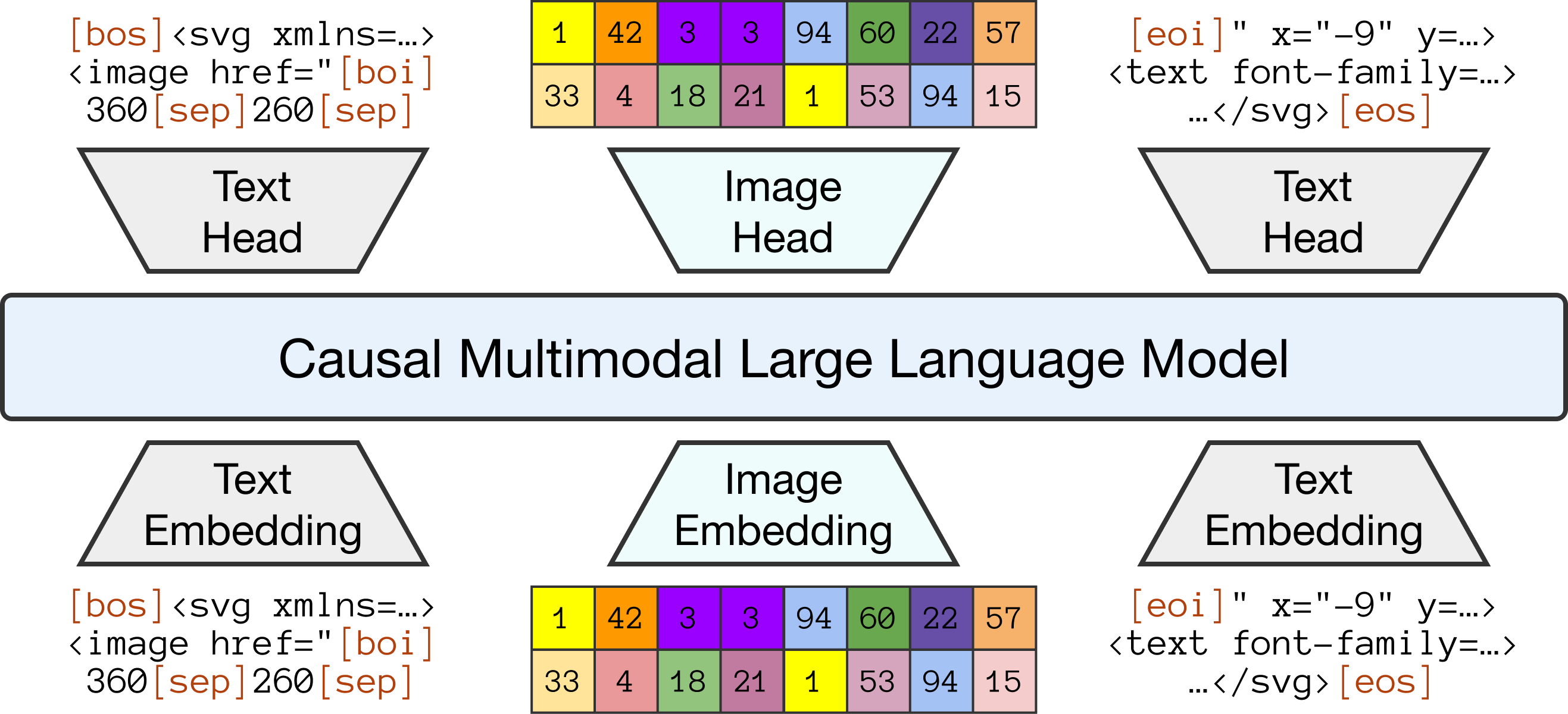
技术框架:MarkupDM的整体框架基于Transformer架构,并针对多模态文档的特点进行了改进。该框架包含以下主要模块:1) 多模态嵌入模块,用于将标记语言、图像和文本转换为统一的向量表示;2) Transformer编码器-解码器,用于学习文档的上下文信息并生成缺失的设计元素;3) 离散图像tokenizer,用于将图像转换为离散的token序列,从而实现图像生成。训练过程采用“fill-in-the-middle”策略,随机mask文档中的一部分元素,并训练模型预测这些被mask的元素。
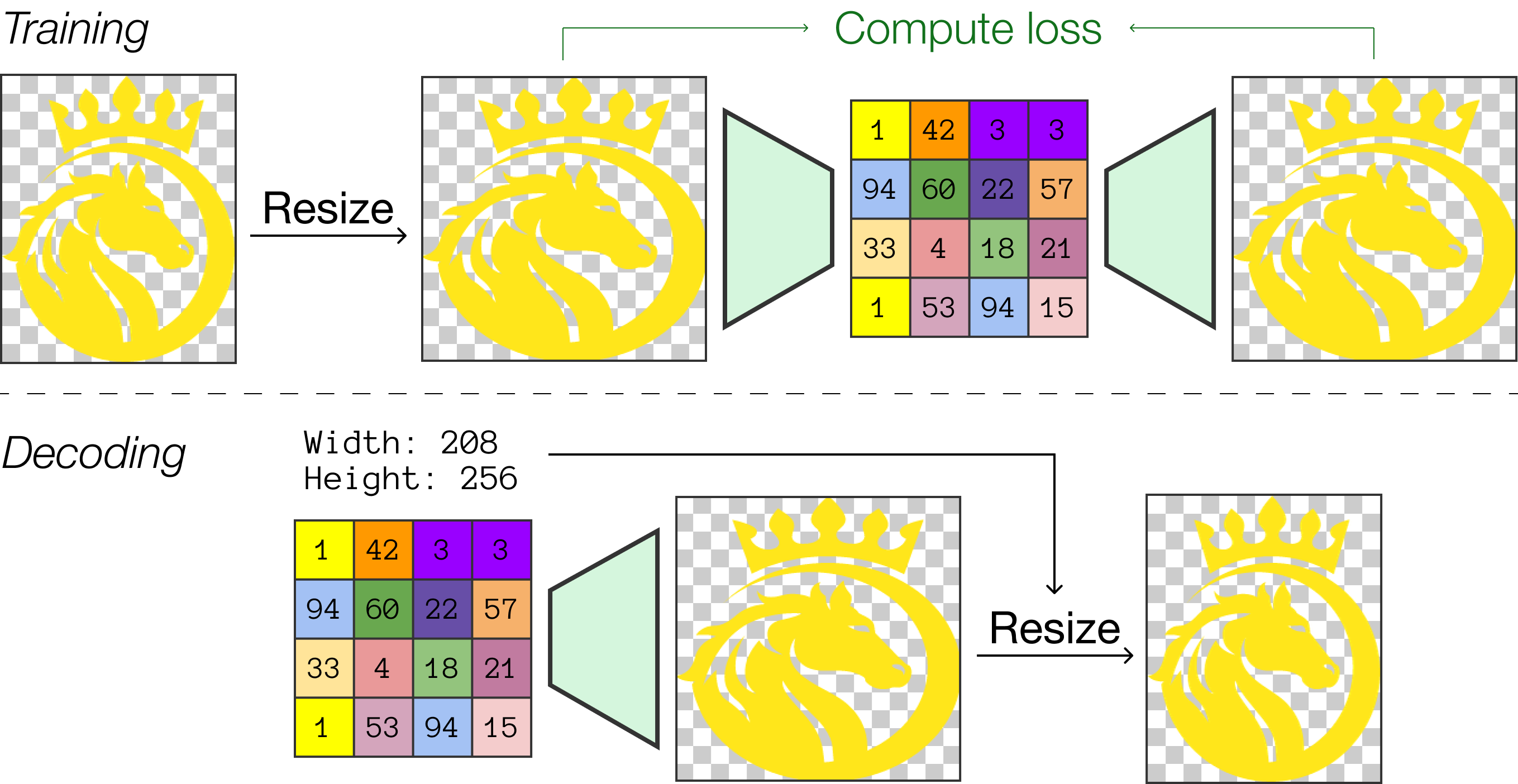
关键创新:论文的关键创新在于提出了MarkupDM多模态文档模型,该模型能够以统一的方式表示和处理图形设计中的多种信息。与现有方法相比,MarkupDM具有以下优势:1) 能够处理可变长度的元素、类型相关的属性和文本内容;2) 采用“fill-in-the-middle”训练策略,提高了模型的泛化能力;3) 支持图像生成,通过离散图像tokenizer实现对图像的灵活控制。
关键设计:在多模态嵌入模块中,论文采用了预训练的语言模型(例如BERT)来编码文本信息,并使用卷积神经网络(CNN)来提取图像特征。离散图像tokenizer的设计至关重要,论文采用了一种基于矢量量化(VQ)的方法,将图像划分为多个离散的token,并使用码本(codebook)来表示这些token。损失函数包括语言模型损失和图像token预测损失,用于优化模型的生成能力。
🖼️ 关键图片
📊 实验亮点
实验结果表明,MarkupDM在属性值、图像和文本补全任务上均取得了良好的性能。在指令引导的设计补全任务中,MarkupDM优于现有的图像编辑模型,尤其是在文本补全方面。这些结果验证了MarkupDM的有效性和灵活性,表明其具有广泛的应用前景。
🎯 应用场景
该研究成果可应用于图形设计自动化领域,例如自动生成广告海报、社交媒体帖子、网页设计等。通过提供部分设计或指令,MarkupDM可以自动完成剩余的设计工作,提高设计效率并降低设计成本。未来,该技术有望应用于更广泛的设计领域,例如产品设计、建筑设计等。
📄 摘要(原文)
We introduce MarkupDM, a multimodal markup document model that represents graphic design as an interleaved multimodal document consisting of both markup language and images. Unlike existing holistic approaches that rely on an element-by-attribute grid representation, our representation accommodates variable-length elements, type-dependent attributes, and text content. Inspired by fill-in-the-middle training in code generation, we train the model to complete the missing part of a design document from its surrounding context, allowing it to treat various design tasks in a unified manner. Our model also supports image generation by predicting discrete image tokens through a specialized tokenizer with support for image transparency. We evaluate MarkupDM on three tasks, attribute value, image, and text completion, and demonstrate that it can produce plausible designs consistent with the given context. To further illustrate the flexibility of our approach, we evaluate our approach on a new instruction-guided design completion task where our instruction-tuned MarkupDM compares favorably to state-of-the-art image editing models, especially in textual completion. These findings suggest that multimodal language models with our document representation can serve as a versatile foundation for broad design automation.