Exploring Token Pruning in Vision State Space Models
作者: Zheng Zhan, Zhenglun Kong, Yifan Gong, Yushu Wu, Zichong Meng, Hangyu Zheng, Xuan Shen, Stratis Ioannidis, Wei Niu, Pu Zhao, Yanzhi Wang
分类: cs.CV, cs.AI, cs.LG
发布日期: 2024-09-27
备注: NeurIPS'24
💡 一句话要点
针对视觉状态空间模型,提出一种新型token剪枝方法以提升效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉状态空间模型 Token剪枝 模型压缩 计算效率 深度学习
📋 核心要点
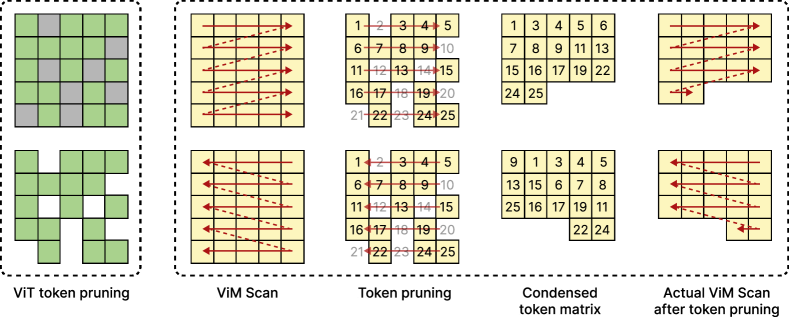
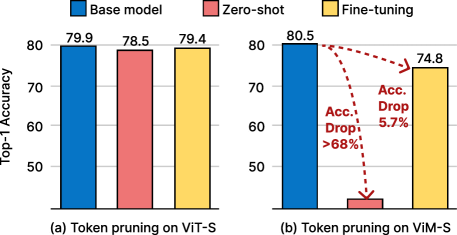
- 现有ViT的token剪枝方法直接应用于视觉SSM模型时性能不佳,因为忽略了SSM模型中token顺序位置的重要性。
- 提出一种新型token剪枝方法,包含剪枝感知的隐藏状态对齐和适用于SSM的token重要性评估,以保持token的邻域关系。
- 实验表明,该方法在显著减少计算量的同时,对性能影响很小,例如在ImageNet上,PlainMamba-L3的FLOPs减少41.6%的同时,精度达到81.7%。
📝 摘要(中文)
状态空间模型(SSMs)相比于Transformer中的注意力模块,具有保持线性计算复杂度的优势,并已作为一种新型强大的视觉基础模型应用于视觉任务。受视觉Transformer(ViT)中最终预测仅基于最具信息量token子集的观察启发,我们采取了一种新颖的步骤,通过基于token的剪枝来提高基于SSM的视觉模型的效率。然而,直接应用为ViT设计的现有token剪枝技术未能提供良好的性能,即使经过广泛的微调也是如此。为了解决这个问题,我们重新审视了SSM的独特计算特性,并发现直接应用会扰乱顺序token的位置。这一洞察力促使我们设计了一种专门为基于SSM的视觉模型设计的新型通用token剪枝方法。我们首先引入了一种具有剪枝意识的隐藏状态对齐方法,以稳定剩余token的邻域,从而提高性能。此外,基于我们的详细分析,我们提出了一种适用于SSM模型的token重要性评估方法,以指导token剪枝。通过高效的实现和实际的加速方法,我们的方法带来了实际的加速。大量的实验表明,我们的方法可以在不同任务中实现显著的计算减少,同时对性能的影响最小。值得注意的是,对于剪枝后的PlainMamba-L3,我们在ImageNet上实现了81.7%的准确率,同时FLOPs减少了41.6%。此外,我们的工作为理解基于SSM的视觉模型的行为提供了更深入的见解,以供未来研究。
🔬 方法详解
问题定义:论文旨在解决视觉状态空间模型(SSM)计算效率不高的问题。现有的token剪枝方法主要针对Transformer设计,直接应用于SSM时,会破坏SSM模型中token的顺序关系,导致性能下降。因此,需要一种专门为SSM设计的token剪枝方法,能够在减少计算量的同时,保持模型的性能。
核心思路:论文的核心思路是设计一种剪枝方法,在剪枝过程中保持剩余token的邻域关系,避免破坏SSM模型中token的顺序位置信息。为此,论文提出了剪枝感知的隐藏状态对齐方法和适用于SSM的token重要性评估方法。通过这两种方法,可以更准确地评估token的重要性,并在剪枝后保持剩余token的局部结构。
技术框架:该方法主要包含两个阶段:token重要性评估和token剪枝。首先,使用提出的token重要性评估方法,为每个token计算一个重要性得分。然后,根据重要性得分,选择一部分token进行剪枝。为了保持剩余token的邻域关系,论文提出了剪枝感知的隐藏状态对齐方法,在剪枝后对剩余token的隐藏状态进行调整,以补偿被剪枝token的影响。
关键创新:论文最重要的技术创新点在于提出了剪枝感知的隐藏状态对齐方法和适用于SSM的token重要性评估方法。剪枝感知的隐藏状态对齐方法能够稳定剩余token的邻域,从而提高剪枝后的模型性能。适用于SSM的token重要性评估方法能够更准确地评估token的重要性,从而指导token剪枝。
关键设计:在token重要性评估方面,论文设计了一种基于SSM模型特性的评估方法,考虑了token在序列中的位置信息和与其他token的交互关系。在剪枝感知的隐藏状态对齐方面,论文设计了一种损失函数,用于衡量剪枝前后隐藏状态的差异,并通过优化该损失函数来调整剩余token的隐藏状态。
🖼️ 关键图片

📊 实验亮点
该方法在ImageNet数据集上取得了显著的成果。对于剪枝后的PlainMamba-L3模型,在保持81.7%的准确率的同时,FLOPs减少了41.6%。这表明该方法能够在显著减少计算量的同时,保持模型的性能。此外,该方法在不同的视觉任务和不同的SSM模型上都取得了良好的效果,证明了其通用性和有效性。
🎯 应用场景
该研究成果可应用于各种需要高效视觉处理的场景,例如移动设备上的图像识别、视频监控、自动驾驶等。通过减少计算量,可以降低模型部署的成本和功耗,使其更容易在资源受限的设备上运行。此外,该研究还可以促进对SSM模型内部机制的理解,为未来的模型设计提供指导。
📄 摘要(原文)
State Space Models (SSMs) have the advantage of keeping linear computational complexity compared to attention modules in transformers, and have been applied to vision tasks as a new type of powerful vision foundation model. Inspired by the observations that the final prediction in vision transformers (ViTs) is only based on a subset of most informative tokens, we take the novel step of enhancing the efficiency of SSM-based vision models through token-based pruning. However, direct applications of existing token pruning techniques designed for ViTs fail to deliver good performance, even with extensive fine-tuning. To address this issue, we revisit the unique computational characteristics of SSMs and discover that naive application disrupts the sequential token positions. This insight motivates us to design a novel and general token pruning method specifically for SSM-based vision models. We first introduce a pruning-aware hidden state alignment method to stabilize the neighborhood of remaining tokens for performance enhancement. Besides, based on our detailed analysis, we propose a token importance evaluation method adapted for SSM models, to guide the token pruning. With efficient implementation and practical acceleration methods, our method brings actual speedup. Extensive experiments demonstrate that our approach can achieve significant computation reduction with minimal impact on performance across different tasks. Notably, we achieve 81.7\% accuracy on ImageNet with a 41.6\% reduction in the FLOPs for pruned PlainMamba-L3. Furthermore, our work provides deeper insights into understanding the behavior of SSM-based vision models for future research.