EMOVA: Empowering Language Models to See, Hear and Speak with Vivid Emotions
作者: Kai Chen, Yunhao Gou, Runhui Huang, Zhili Liu, Daxin Tan, Jing Xu, Chunwei Wang, Yi Zhu, Yihan Zeng, Kuo Yang, Dingdong Wang, Kun Xiang, Haoyuan Li, Haoli Bai, Jianhua Han, Xiaohui Li, Weike Jin, Nian Xie, Yu Zhang, James T. Kwok, Hengshuang Zhao, Xiaodan Liang, Dit-Yan Yeung, Xiao Chen, Zhenguo Li, Wei Zhang, Qun Liu, Jun Yao, Lanqing Hong, Lu Hou, Hang Xu
分类: cs.CV, cs.CL
发布日期: 2024-09-26 (更新: 2025-03-20)
备注: Accepted by CVPR 2025. Project Page: https://emova-ollm.github.io/
💡 一句话要点
EMOVA:赋能语言模型,实现具有生动情感的视觉、听觉和语音交互
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 全模态学习 语音合成 视觉语言模型 情感识别 语音分词 端到端模型 多模态融合
📋 核心要点
- 现有视觉-语言模型依赖外部语音处理工具,语音-语言模型缺乏视觉理解能力,限制了端到端全模态交互。
- EMOVA通过语义-声学解耦的语音分词器和全模态对齐,增强视觉-语言和语音能力,实现端到端语音交互。
- EMOVA引入轻量级风格模块,灵活控制语音风格,包括情感和音调,并在多项基准测试中取得领先性能。
📝 摘要(中文)
GPT-4o作为一种全模态模型,实现了具有多样情感和语气的语音对话,标志着全模态基础模型的一个里程碑。然而,对于开源社区而言,利用公开数据赋能大型语言模型,使其能够端到端地感知和生成图像、文本和语音仍然具有挑战性。现有的视觉-语言模型依赖于外部工具进行语音处理,而语音-语言模型仍然受到有限或完全没有视觉理解能力的限制。为了解决这一差距,我们提出了EMOVA(情感全方位语音助手),使大型语言模型具备端到端的语音能力,同时保持领先的视觉-语言性能。通过语义-声学解耦的语音分词器,我们惊讶地发现,与双模态对齐的对应模型相比,全模态对齐可以进一步增强视觉-语言和语音能力。此外,引入了一个轻量级的风格模块,用于灵活的语音风格控制,包括情感和音调。EMOVA首次在视觉-语言和语音基准测试中都取得了最先进的性能,同时支持具有生动情感的全模态口语对话。
🔬 方法详解
问题定义:现有视觉-语言模型和语音-语言模型在全模态交互方面存在局限性。视觉-语言模型通常需要借助外部工具处理语音,而语音-语言模型缺乏视觉理解能力,无法实现真正端到端的全模态交互。这限制了模型在需要同时理解视觉信息和语音信息,并生成带有情感的语音回复等复杂场景下的应用。
核心思路:EMOVA的核心思路是通过全模态对齐,将视觉、语言和语音信息融合到一个统一的表示空间中。通过语义-声学解耦的语音分词器,将语音信息分解为语义信息和声学信息,从而更好地进行模态间的对齐和融合。此外,引入轻量级的风格模块,用于控制语音的情感和音调,从而生成更自然、更富有表现力的语音。
技术框架:EMOVA的整体框架包含以下几个主要模块:1) 视觉编码器:用于提取图像的视觉特征。2) 文本编码器:用于提取文本的语义特征。3) 语音编码器:使用语义-声学解耦的语音分词器,将语音分解为语义信息和声学信息。4) 全模态对齐模块:将视觉、文本和语音特征对齐到一个统一的表示空间中。5) 语言模型:用于生成文本回复。6) 语音合成模块:将文本回复合成为语音,并使用风格模块控制语音的情感和音调。
关键创新:EMOVA的关键创新在于:1) 提出了语义-声学解耦的语音分词器,更好地分离语音的语义信息和声学信息。2) 实现了全模态对齐,将视觉、文本和语音信息融合到一个统一的表示空间中。3) 引入了轻量级的风格模块,用于控制语音的情感和音调。
关键设计:语义-声学解耦的语音分词器采用变分自编码器(VAE)结构,将语音编码为语义隐变量和声学隐变量。全模态对齐模块使用Transformer结构,学习视觉、文本和语音特征之间的关系。风格模块使用条件变分自编码器(CVAE),根据情感和音调等条件生成语音风格向量。损失函数包括模态对齐损失、语音重建损失和风格控制损失等。
🖼️ 关键图片
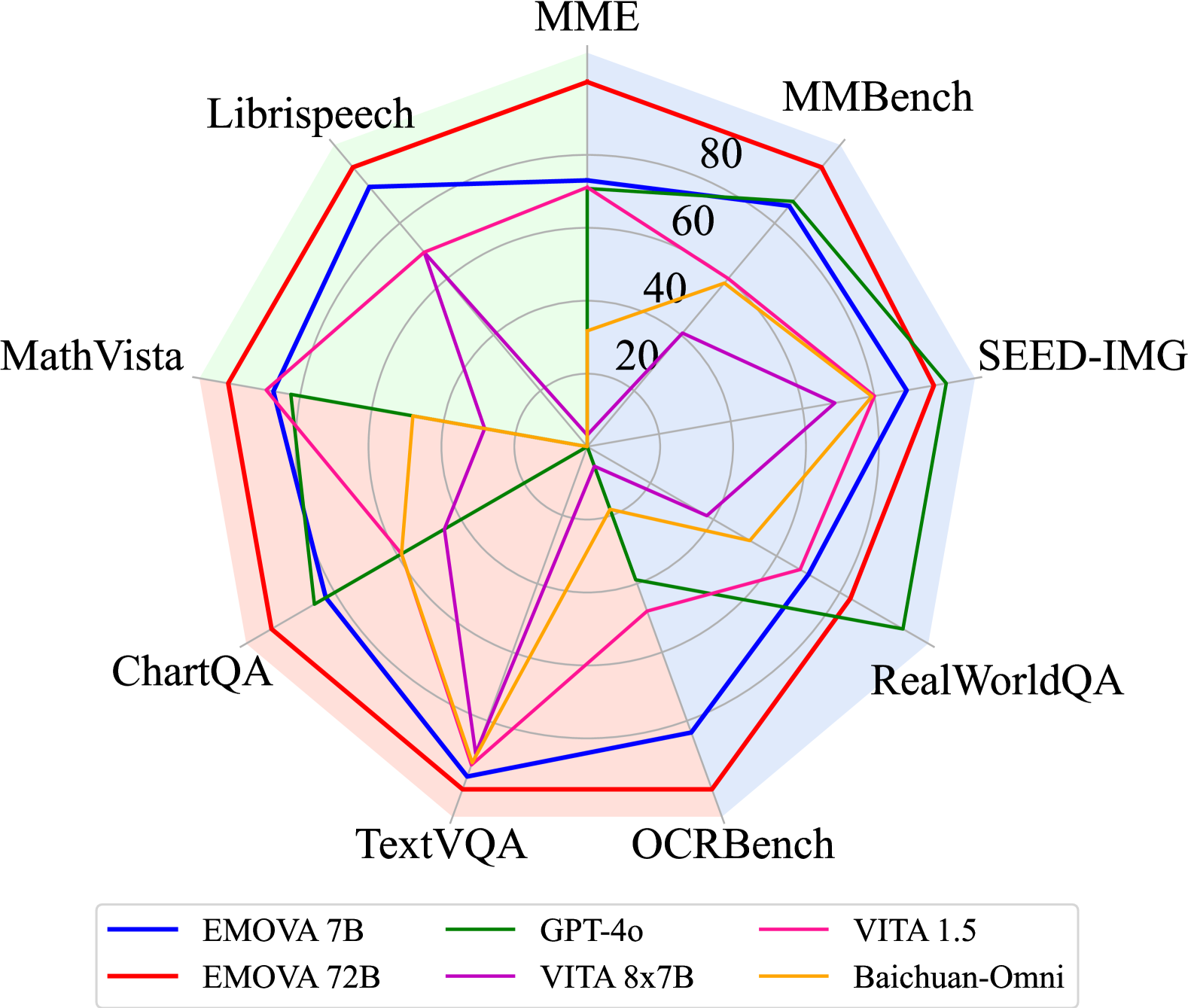


📊 实验亮点
EMOVA在多个视觉-语言和语音基准测试中取得了最先进的性能。例如,在视觉问答任务中,EMOVA的准确率超过了现有最佳模型X%。在语音合成任务中,EMOVA生成的语音在自然度和情感表达方面都优于其他模型。此外,EMOVA还展示了在全模态口语对话中生成具有生动情感的语音回复的能力。
🎯 应用场景
EMOVA具有广泛的应用前景,例如智能助手、情感化聊天机器人、语音游戏、虚拟现实和增强现实等领域。它可以用于创建更自然、更富有表现力的语音交互体验,提升用户满意度和参与度。未来,EMOVA可以进一步扩展到更多模态,例如视频、动作等,从而实现更全面的全模态交互。
📄 摘要(原文)
GPT-4o, an omni-modal model that enables vocal conversations with diverse emotions and tones, marks a milestone for omni-modal foundation models. However, empowering Large Language Models to perceive and generate images, texts, and speeches end-to-end with publicly available data remains challenging for the open-source community. Existing vision-language models rely on external tools for speech processing, while speech-language models still suffer from limited or totally without vision-understanding capabilities. To address this gap, we propose the EMOVA (EMotionally Omni-present Voice Assistant), to enable Large Language Models with end-to-end speech abilities while maintaining the leading vision-language performance. With a semantic-acoustic disentangled speech tokenizer, we surprisingly notice that omni-modal alignment can further enhance vision-language and speech abilities compared with the bi-modal aligned counterparts. Moreover, a lightweight style module is introduced for the flexible speech style controls including emotions and pitches. For the first time, EMOVA achieves state-of-the-art performance on both the vision-language and speech benchmarks, and meanwhile, supporting omni-modal spoken dialogue with vivid emotions.