MoGenTS: Motion Generation based on Spatial-Temporal Joint Modeling
作者: Weihao Yuan, Weichao Shen, Yisheng He, Yuan Dong, Xiaodong Gu, Zilong Dong, Liefeng Bo, Qixing Huang
分类: cs.CV
发布日期: 2024-09-26 (更新: 2024-12-18)
备注: Accepted to NeurIPS 2024
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
MoGenTS:基于时空联合建模的运动生成方法,有效提升运动生成质量。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting)
关键词: 运动生成 时空建模 离散量化 VQVAE 2D注意力
📋 核心要点
- 现有运动生成方法将整个姿态量化为单个代码,忽略了关节间的空间关系,且编码复杂。
- MoGenTS将每个关节单独量化,保留时空结构,并利用2D token map进行时空建模。
- 实验表明,MoGenTS在HumanML3D和KIT-ML数据集上显著优于现有方法,FID分别降低26.6%和29.9%。
📝 摘要(中文)
本文提出了一种基于离散量化的运动生成方法MoGenTS,旨在克服连续回归方法中的近似误差。与以往将整个身体姿态量化为单个代码的方法不同,本文将每个关节单独量化为一个向量。这种方法简化了量化过程,因为单个关节的复杂性远低于整个姿态;同时,保持了时空结构,保留了关节之间的空间关系和时间运动模式;此外,生成了一个2D token map,从而可以应用广泛用于2D图像的各种2D操作。基于2D运动量化,构建了一个时空建模框架,其中提出了2D关节VQVAE、时空2D掩码技术和时空2D注意力,以利用2D token中的时空信号。大量实验表明,该方法在不同数据集上显著优于以往的方法,在HumanML3D上FID降低了26.6%,在KIT-ML上降低了29.9%。
🔬 方法详解
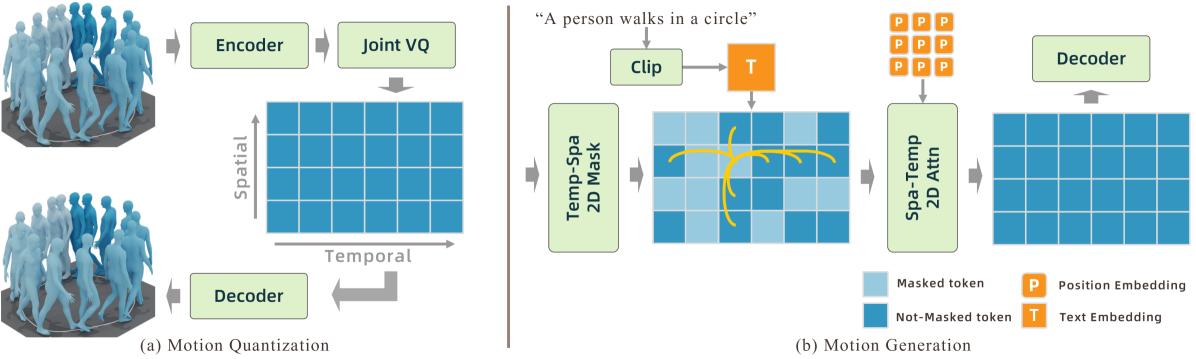
问题定义:现有基于离散量化的运动生成方法通常将整个身体姿态量化成一个向量,这导致两个主要问题:一是编码所有关节的复杂性很高;二是忽略了不同关节之间的空间关系。这种全局量化方式限制了模型捕捉细粒度运动细节的能力,并引入了较大的近似误差。
核心思路:MoGenTS的核心思路是将每个关节单独量化为一个向量,而不是将整个姿态作为一个整体。这种分解方式显著降低了量化过程的复杂性,因为单个关节的运动模式比整个姿态简单得多。此外,通过保持每个关节的独立性,模型能够更好地捕捉关节之间的空间关系和时间运动模式。将运动数据转化为2D token map,从而可以利用图像处理领域成熟的2D操作。
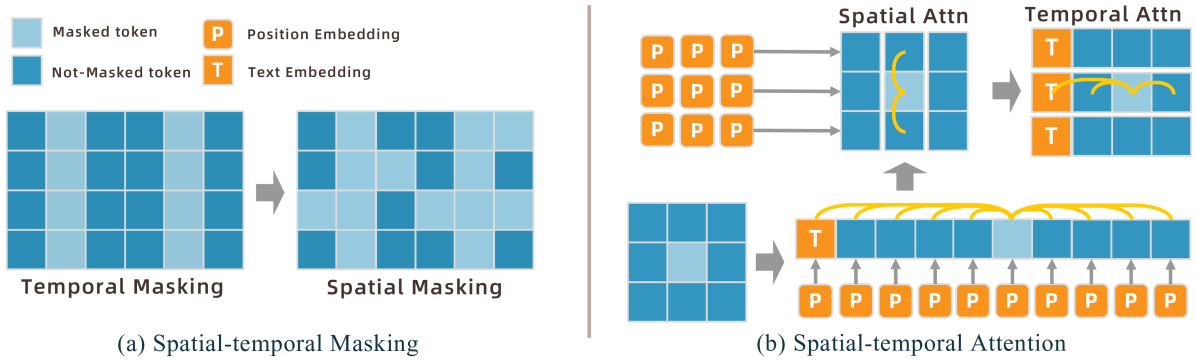
技术框架:MoGenTS框架包含以下几个主要模块:1) 2D关节VQVAE:用于将每个关节的运动数据量化为离散的token,生成2D token map。2) 时空2D掩码技术:用于在训练过程中随机掩盖部分token,迫使模型学习token之间的依赖关系,从而提高模型的泛化能力。3) 时空2D注意力:用于捕捉2D token map中的时空依赖关系,从而更好地理解运动模式。整个框架通过联合优化这些模块,实现高质量的运动生成。
关键创新:MoGenTS的关键创新在于其将运动生成问题转化为一个2D图像处理问题。通过将每个关节单独量化并生成2D token map,MoGenTS能够利用图像处理领域丰富的工具和技术,例如2D卷积、2D注意力等。这种方法与以往的全局量化方法相比,能够更好地捕捉运动数据的时空依赖关系,并生成更逼真的运动。
关键设计:在2D关节VQVAE中,使用了残差连接和多层感知机来提高编码器的表达能力。时空2D掩码技术采用了随机掩盖策略,掩盖比例是一个重要的超参数,需要根据数据集进行调整。时空2D注意力模块采用了多头注意力机制,头的数量和维度需要根据计算资源进行调整。损失函数包括重构损失、量化损失和对抗损失,用于平衡生成质量和多样性。
🖼️ 关键图片

📊 实验亮点
MoGenTS在HumanML3D和KIT-ML数据集上取得了显著的性能提升。在HumanML3D数据集上,MoGenTS的FID降低了26.6%,R精度提高了15.2%。在KIT-ML数据集上,MoGenTS的FID降低了29.9%,R精度提高了18.5%。这些结果表明,MoGenTS能够生成更逼真、更多样化的运动。
🎯 应用场景
MoGenTS具有广泛的应用前景,例如:1) 虚拟现实和增强现实:可以生成逼真的虚拟人物运动,提高用户体验。2) 游戏开发:可以生成各种角色的运动动画,降低开发成本。3) 机器人控制:可以生成机器人的运动轨迹,实现更灵活的运动控制。4) 动画制作:可以辅助动画师生成复杂的运动序列,提高工作效率。
📄 摘要(原文)
Motion generation from discrete quantization offers many advantages over continuous regression, but at the cost of inevitable approximation errors. Previous methods usually quantize the entire body pose into one code, which not only faces the difficulty in encoding all joints within one vector but also loses the spatial relationship between different joints. Differently, in this work we quantize each individual joint into one vector, which i) simplifies the quantization process as the complexity associated with a single joint is markedly lower than that of the entire pose; ii) maintains a spatial-temporal structure that preserves both the spatial relationships among joints and the temporal movement patterns; iii) yields a 2D token map, which enables the application of various 2D operations widely used in 2D images. Grounded in the 2D motion quantization, we build a spatial-temporal modeling framework, where 2D joint VQVAE, temporal-spatial 2D masking technique, and spatial-temporal 2D attention are proposed to take advantage of spatial-temporal signals among the 2D tokens. Extensive experiments demonstrate that our method significantly outperforms previous methods across different datasets, with a 26.6% decrease of FID on HumanML3D and a 29.9% decrease on KIT-ML. Project page: https://aigc3d.github.io/mogents.