P4Q: Learning to Prompt for Quantization in Visual-language Models
作者: Huixin Sun, Runqi Wang, Yanjing Li, Xianbin Cao, Xiaolong Jiang, Yao Hu, Baochang Zhang
分类: cs.CV, cs.AI
发布日期: 2024-09-26
💡 一句话要点
提出P4Q:一种面向视觉-语言模型量化的Prompt学习方法,提升低比特量化性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 量化 Prompt学习 后训练量化 模型压缩 知识蒸馏 低比特量化
📋 核心要点
- 现有视觉-语言模型部署面临计算资源和训练样本的挑战,低比特后训练量化(PTQ)虽然高效,但性能显著下降。
- 论文提出Prompt for Quantization (P4Q) 方法,通过可学习prompt重组文本表示,并用低比特适配器对齐图像和文本特征。
- 实验表明,P4Q方法在量化CLIP-ViT/B-32模型时,性能优于现有技术,甚至可与全精度模型媲美,同时显著降低计算成本。
📝 摘要(中文)
大规模预训练视觉-语言模型(VLMs)在各种视觉和多模态任务中获得了显著地位,但由于其对训练样本和计算资源的巨大需求,VLMs在下游应用平台上的部署仍然具有挑战性。微调和量化VLMs可以显著降低样本和计算成本,这是当前迫切需要的。量化领域存在两种主流范式:量化感知训练(QAT)可以有效地量化大规模VLMs,但会产生巨大的训练成本;而低比特后训练量化(PTQ)则会遭受显著的性能下降。我们提出了一种平衡微调和量化的方法,名为“Prompt for Quantization”(P4Q),其中我们设计了一个轻量级架构,利用对比损失监督来增强PTQ模型的识别性能。我们的方法可以有效地减少由低比特量化引起的图像特征和文本特征之间的差距,基于可学习的prompt来重组文本表示,并使用低比特适配器来重新对齐图像和文本特征的分布。我们还引入了一种基于余弦相似度预测的蒸馏损失,以使用全精度教师模型来蒸馏量化模型。大量的实验结果表明,我们的P4Q方法优于现有技术,甚至可以达到与其全精度模型相当的结果。例如,我们的8比特P4Q在理论上可以将CLIP-ViT/B-32压缩4倍,同时实现66.94%的Top-1准确率,在ImageNet数据集上,以可忽略的额外参数优于可学习prompt微调的全精度模型2.24%。
🔬 方法详解
问题定义:论文旨在解决视觉-语言模型(VLMs)在低比特量化后性能显著下降的问题。现有方法,如量化感知训练(QAT),虽然能有效量化VLMs,但训练成本巨大;而后训练量化(PTQ)虽然高效,但精度损失明显。因此,如何在保证量化效率的同时,尽可能减小性能损失,是本研究要解决的核心问题。
核心思路:论文的核心思路是利用Prompt学习来弥补低比特量化带来的特征信息损失。通过引入可学习的Prompt,模型能够更好地理解和利用文本信息,从而提升图像识别的准确性。同时,使用低比特适配器来对齐图像和文本特征的分布,进一步减小量化带来的特征偏差。
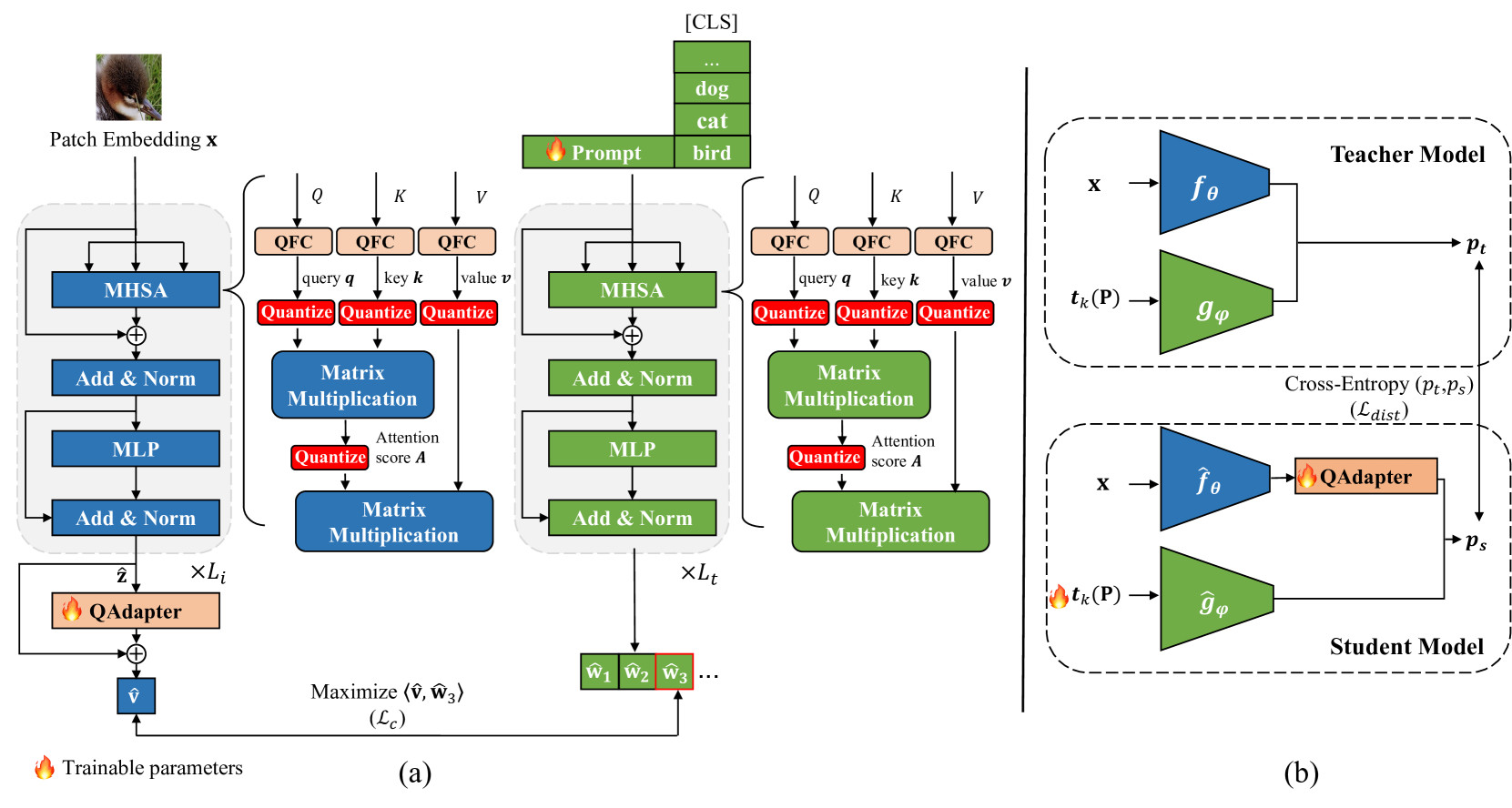
技术框架:P4Q方法主要包含三个关键模块:可学习的文本Prompt、低比特适配器和基于余弦相似度预测的蒸馏损失。首先,可学习的文本Prompt被添加到文本编码器中,用于重组文本表示。其次,低比特适配器被用于对齐图像和文本特征的分布。最后,使用全精度教师模型,通过基于余弦相似度预测的蒸馏损失来指导量化模型的训练。
关键创新:P4Q的关键创新在于将Prompt学习引入到视觉-语言模型的量化过程中。与传统的量化方法不同,P4Q不是直接对量化后的模型进行微调,而是通过学习Prompt来增强模型对文本信息的理解能力,从而提升图像识别的准确性。此外,低比特适配器的使用也有助于减小量化带来的特征偏差。
关键设计:文本Prompt被设计为可学习的向量,通过与文本编码器的输出进行拼接,来影响文本表示。低比特适配器通常是一个小的全连接网络,用于将图像和文本特征映射到相同的空间。蒸馏损失基于余弦相似度预测,鼓励量化模型的输出与全精度教师模型的输出保持一致。具体的参数设置,如Prompt的长度、适配器的层数和大小,以及蒸馏损失的权重,需要根据具体的任务和数据集进行调整。
🖼️ 关键图片
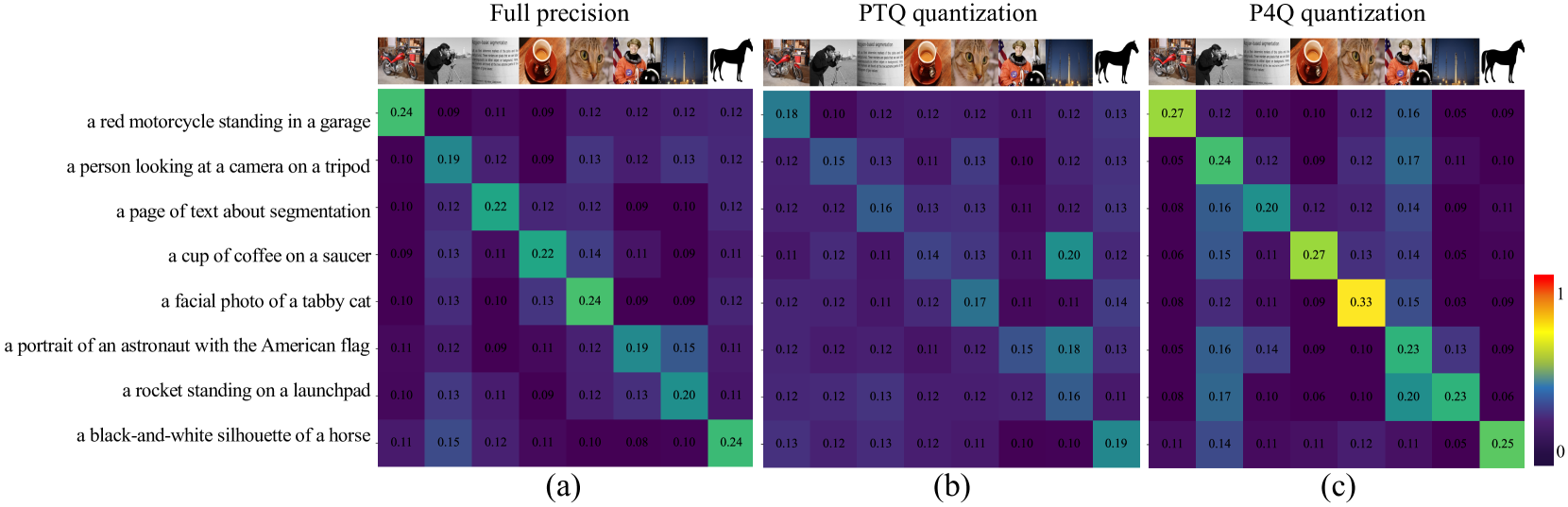

📊 实验亮点
P4Q方法在ImageNet数据集上取得了显著的性能提升。例如,使用8比特量化,P4Q可以将CLIP-ViT/B-32模型压缩4倍,同时达到66.94%的Top-1准确率,甚至超过了使用可学习prompt微调的全精度模型2.24%。这表明P4Q方法能够在保证量化效率的同时,显著提升模型的性能。
🎯 应用场景
该研究成果可应用于各种需要部署大规模视觉-语言模型的场景,例如移动设备、嵌入式系统和边缘计算设备。通过P4Q方法,可以在显著降低模型大小和计算复杂度的同时,保持较高的模型性能,从而实现VLMs在资源受限环境下的高效部署。这对于推动人工智能技术在实际应用中的普及具有重要意义。
📄 摘要(原文)
Large-scale pre-trained Vision-Language Models (VLMs) have gained prominence in various visual and multimodal tasks, yet the deployment of VLMs on downstream application platforms remains challenging due to their prohibitive requirements of training samples and computing resources. Fine-tuning and quantization of VLMs can substantially reduce the sample and computation costs, which are in urgent need. There are two prevailing paradigms in quantization, Quantization-Aware Training (QAT) can effectively quantize large-scale VLMs but incur a huge training cost, while low-bit Post-Training Quantization (PTQ) suffers from a notable performance drop. We propose a method that balances fine-tuning and quantization named ``Prompt for Quantization'' (P4Q), in which we design a lightweight architecture to leverage contrastive loss supervision to enhance the recognition performance of a PTQ model. Our method can effectively reduce the gap between image features and text features caused by low-bit quantization, based on learnable prompts to reorganize textual representations and a low-bit adapter to realign the distributions of image and text features. We also introduce a distillation loss based on cosine similarity predictions to distill the quantized model using a full-precision teacher. Extensive experimental results demonstrate that our P4Q method outperforms prior arts, even achieving comparable results to its full-precision counterparts. For instance, our 8-bit P4Q can theoretically compress the CLIP-ViT/B-32 by 4 $\times$ while achieving 66.94\% Top-1 accuracy, outperforming the learnable prompt fine-tuned full-precision model by 2.24\% with negligible additional parameters on the ImageNet dataset.