CleanerCLIP: Fine-grained Counterfactual Semantic Augmentation for Backdoor Defense in Contrastive Learning
作者: Yuan Xun, Siyuan Liang, Xiaojun Jia, Xinwei Liu, Xiaochun Cao
分类: cs.CV, cs.AI
发布日期: 2024-09-26 (更新: 2024-11-15)
💡 一句话要点
提出TA-Cleaner,通过细粒度对抗语义增强提升对比学习中CLIP的后门防御能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 后门防御 对比学习 多模态学习 数据投毒攻击 文本对齐 自监督学习
📋 核心要点
- CLIP等对比学习模型易受后门攻击,现有微调防御方法(如CleanCLIP)在复杂攻击下存在防御性能瓶颈,文本增强不足。
- 提出TA-Cleaner,通过细粒度文本对齐,生成正负子文本并与图像对齐,增强文本自监督,切断后门触发器的特征连接。
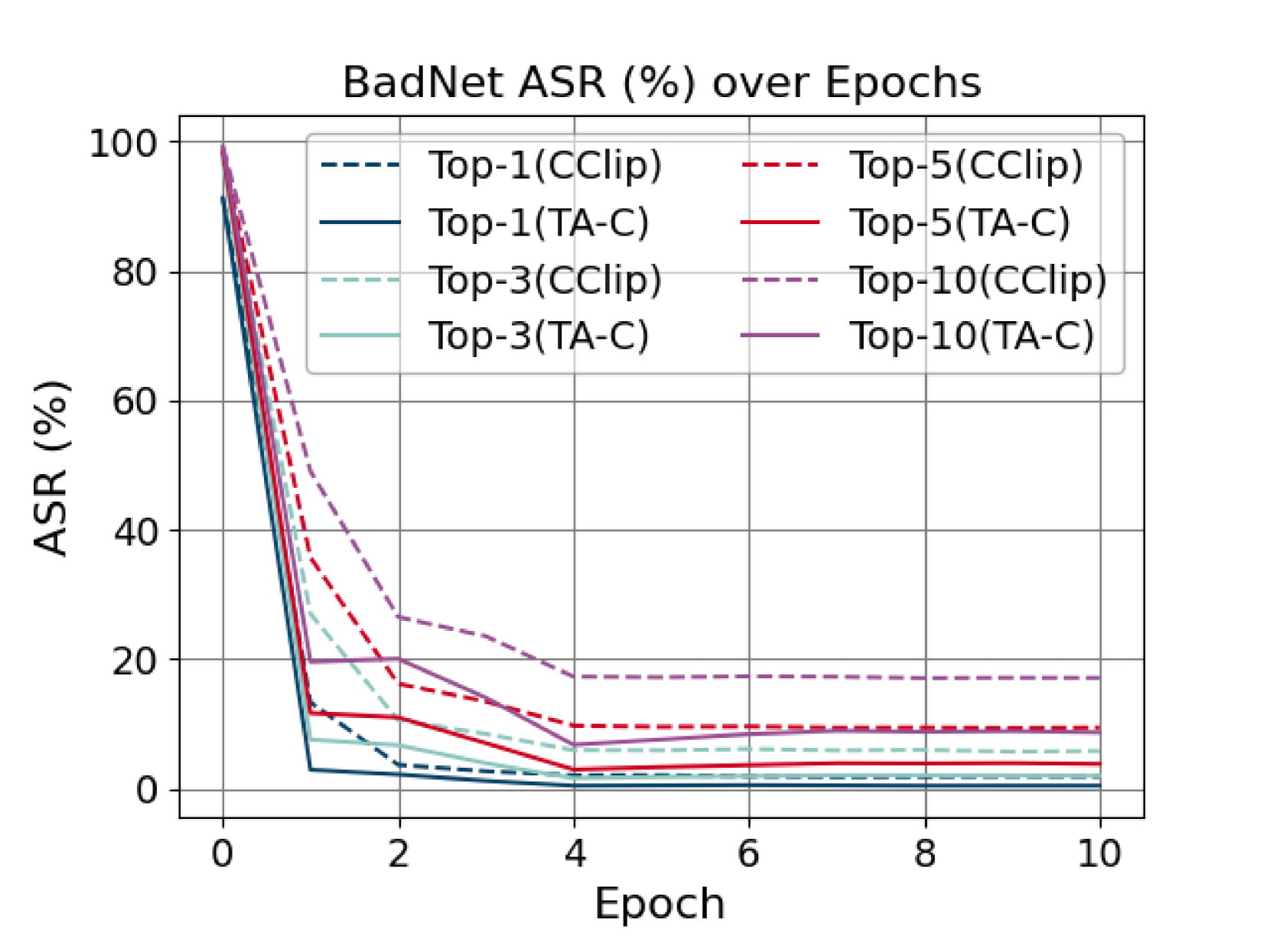
- 实验表明,TA-Cleaner在多种攻击下均优于CleanCLIP,尤其在应对BadCLIP攻击时,攻击成功率显著降低。
📝 摘要(中文)
多模态对比学习的预训练大模型,如CLIP,在工业界被广泛认可,但也极易受到数据投毒的后门攻击。这给下游模型训练带来了重大风险。为了应对这些潜在威胁,相比于使用增强数据重新训练大型模型,微调提供了一种更简单高效的防御选择。在监督学习领域,微调防御策略可以实现出色的防御性能。然而,在无监督和半监督领域,我们发现当CLIP面临一些复杂的攻击技术时,现有的微调防御策略CleanCLIP在防御性能上存在一些局限性,其文本增强的同义词替换不足以增强文本特征空间。为了弥补这一弱点,我们通过提出一种细粒度的文本对齐清理器(TA-Cleaner)来切断后门触发器的特征连接,从而改进了CleanCLIP。我们在CleanCLIP的每个epoch中随机选择一些样本用于正负子文本生成,并将子文本与图像对齐以加强文本自监督。我们评估了我们的TA-Cleaner对六种攻击算法的有效性,并在ImageNet1K上进行了全面的零样本分类测试。实验结果表明,TA-Cleaner在基于微调的防御技术中实现了最先进的防御能力。即使面对新的攻击技术BadCLIP,我们的TA-Cleaner也优于CleanCLIP,Top-1和Top-10的攻击成功率(ASR)分别降低了52.02%和63.88%。
🔬 方法详解
问题定义:论文旨在解决多模态对比学习模型(如CLIP)在数据投毒攻击下的后门防御问题。现有基于微调的防御方法,如CleanCLIP,在面对复杂的后门攻击时,由于其文本增强策略(同义词替换)的局限性,无法充分增强文本特征空间,导致防御效果不佳。
核心思路:论文的核心思路是通过细粒度的文本对齐来增强文本特征空间,从而切断后门触发器的特征连接。具体来说,通过生成与图像相关的正负子文本,并利用这些子文本进行自监督学习,使得模型能够更好地学习到图像和文本之间的真实对应关系,从而降低后门触发器的影响。
技术框架:TA-Cleaner是在CleanCLIP的基础上进行改进的。整体流程如下:1) 在CleanCLIP的每个epoch中,随机选择少量样本。2) 对于每个选定的样本,生成正负子文本。3) 将生成的子文本与对应的图像进行对齐,通过自监督学习的方式,加强文本特征空间。4) 使用增强后的文本特征空间进行后门防御。
关键创新:TA-Cleaner的关键创新在于其细粒度的文本对齐策略。与CleanCLIP的同义词替换不同,TA-Cleaner通过生成与图像相关的正负子文本,能够更有效地增强文本特征空间,从而更好地切断后门触发器的特征连接。这种方法能够更有效地应对复杂的后门攻击。
关键设计:TA-Cleaner的关键设计包括:1) 子文本生成策略:如何生成与图像相关的正负子文本是关键。论文中可能采用了某种特定的生成模型或规则。2) 对齐方式:如何将子文本与图像进行对齐,例如,可以使用对比损失函数来鼓励正样本对齐,负样本分离。3) 损失函数:除了对比损失函数外,可能还使用了其他的损失函数来进一步提升模型的性能。具体的参数设置和网络结构细节需要在论文中查找。
🖼️ 关键图片


📊 实验亮点
实验结果表明,TA-Cleaner在六种攻击算法下均表现出优异的防御性能,并在ImageNet1K上取得了最先进的零样本分类结果。尤其是在面对新型攻击技术BadCLIP时,TA-Cleaner相比CleanCLIP,Top-1和Top-10的攻击成功率分别降低了52.02%和63.88%,证明了其强大的防御能力。
🎯 应用场景
该研究成果可应用于各种多模态对比学习模型的后门防御,例如图像检索、视频理解、跨模态生成等领域。通过提高模型的鲁棒性和安全性,可以降低恶意攻击对模型性能的影响,保障下游任务的可靠性,具有重要的实际应用价值和潜在的社会影响。
📄 摘要(原文)
Pre-trained large models for multimodal contrastive learning, such as CLIP, have been widely recognized in the industry as highly susceptible to data-poisoned backdoor attacks. This poses significant risks to downstream model training. In response to such potential threats, finetuning offers a simpler and more efficient defense choice compared to retraining large models with augmented data. In the supervised learning domain, fine-tuning defense strategies can achieve excellent defense performance. However, in the unsupervised and semi-supervised domain, we find that when CLIP faces some complex attack techniques, the existing fine-tuning defense strategy, CleanCLIP, has some limitations on defense performance. The synonym substitution of its text-augmentation is insufficient to enhance the text feature space. To compensate for this weakness, we improve it by proposing a fine-grained \textbf{T}ext \textbf{A}lignment \textbf{C}leaner (TA-Cleaner) to cut off feature connections of backdoor triggers. We randomly select a few samples for positive and negative subtext generation at each epoch of CleanCLIP, and align the subtexts to the images to strengthen the text self-supervision. We evaluate the effectiveness of our TA-Cleaner against six attack algorithms and conduct comprehensive zero-shot classification tests on ImageNet1K. Our experimental results demonstrate that TA-Cleaner achieves state-of-the-art defensiveness among finetuning-based defense techniques. Even when faced with the novel attack technique BadCLIP, our TA-Cleaner outperforms CleanCLIP by reducing the ASR of Top-1 and Top-10 by 52.02\% and 63.88\%, respectively.