SimVG: A Simple Framework for Visual Grounding with Decoupled Multi-modal Fusion
作者: Ming Dai, Lingfeng Yang, Yihao Xu, Zhenhua Feng, Wankou Yang
分类: cs.CV, cs.AI
发布日期: 2024-09-26 (更新: 2024-10-28)
备注: 24pages, 18figures, NeurIPS2024
🔗 代码/项目: GITHUB
💡 一句话要点
SimVG:一种解耦多模态融合的简单视觉定位框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉定位 多模态融合 Transformer 预训练模型 知识蒸馏 对象检测 解耦学习
📋 核心要点
- 现有视觉定位方法在处理复杂文本时性能下降,原因是多模态特征融合依赖有限的下游数据。
- SimVG利用预训练模型解耦特征融合与下游任务,并引入对象tokens促进深度集成。
- SimVG采用动态权重平衡蒸馏,提升轻量级MLP分支的表示能力,并在多个数据集上取得SOTA。
📝 摘要(中文)
视觉定位是一项常见的视觉任务,旨在将描述性语句定位到图像中的对应区域。现有方法大多采用独立的图像-文本编码,并应用复杂的手工模块或编码器-解码器架构进行模态交互和查询推理。然而,当处理复杂的文本表达时,它们的性能会显著下降。这是因为前一种范式仅利用有限的下游数据来拟合多模态特征融合。因此,它仅在文本表达相对简单时有效。相反,考虑到文本表达的广泛多样性和下游训练数据的独特性,现有的融合模块(从视觉-语言上下文中提取多模态内容)尚未得到充分研究。在本文中,我们提出了一种简单而强大的基于Transformer的框架SimVG,用于视觉定位。具体来说,我们通过利用现有的多模态预训练模型并将额外的对象tokens纳入其中,将视觉-语言特征融合与下游任务解耦,从而促进下游任务和预训练任务的深度集成。此外,我们在多分支同步学习过程中设计了一种动态权重平衡蒸馏方法,以增强更简单分支的表示能力。该分支仅由轻量级MLP组成,从而简化了结构并提高了推理速度。在六个广泛使用的VG数据集(即RefCOCO/+/g、ReferIt、Flickr30K和GRefCOCO)上的实验证明了SimVG的优越性。最后,所提出的方法不仅提高了效率和收敛速度,而且在这些基准测试中获得了新的最先进性能。
🔬 方法详解
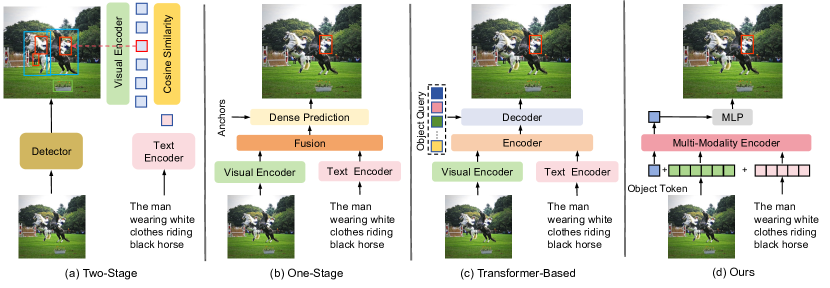
问题定义:视觉定位旨在将自然语言描述与图像中的特定区域对应起来。现有方法通常采用独立的图像和文本编码器,并通过复杂的模块进行多模态融合。然而,这些方法在处理复杂或细粒度的文本描述时,性能会显著下降,因为它们无法充分利用下游任务的数据进行多模态特征融合。
核心思路:SimVG的核心思路是将视觉-语言特征融合与下游任务解耦。通过利用预训练的多模态模型,SimVG能够学习更通用的视觉-语言表示,从而更好地适应各种复杂的文本描述。此外,引入额外的对象tokens,进一步促进了下游任务与预训练模型的深度集成。
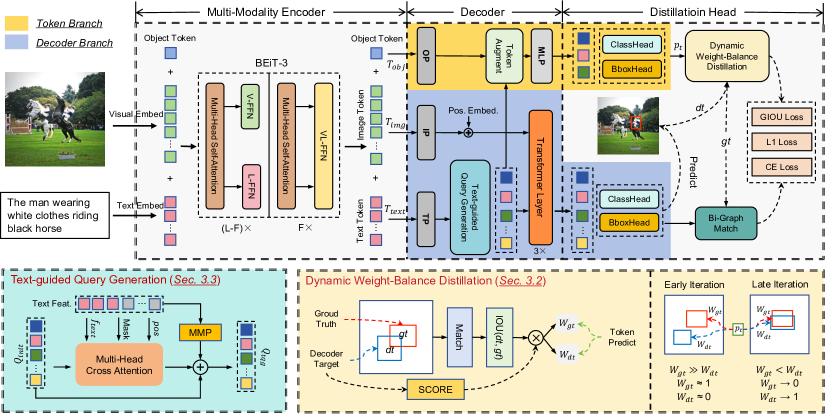
技术框架:SimVG的整体框架包括以下几个主要模块:1) 图像编码器:用于提取图像的视觉特征。2) 文本编码器:用于提取文本的语言特征。3) 多模态预训练模型:用于融合视觉和语言特征,生成多模态表示。4) 对象tokens:用于增强图像表示,提供更细粒度的对象信息。5) 轻量级MLP分支:用于最终的定位预测。6) 动态权重平衡蒸馏:用于提升MLP分支的性能。
关键创新:SimVG的关键创新在于解耦了视觉-语言特征融合与下游任务。通过利用预训练的多模态模型,SimVG能够学习更通用的视觉-语言表示,从而更好地适应各种复杂的文本描述。此外,动态权重平衡蒸馏方法能够有效地提升轻量级MLP分支的性能,从而提高推理速度。
关键设计:SimVG的关键设计包括:1) 使用预训练的Transformer模型作为多模态融合模块。2) 引入可学习的对象tokens来增强图像表示。3) 设计动态权重平衡蒸馏损失函数,平衡预训练模型和MLP分支的学习。具体来说,损失函数会根据两个分支的性能动态调整权重,使得性能较差的分支能够得到更多的关注。
🖼️ 关键图片
📊 实验亮点
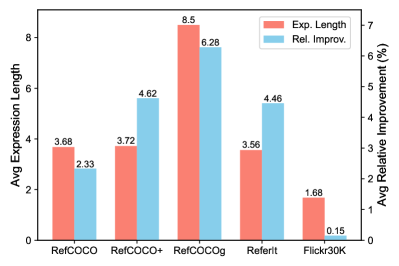
SimVG在RefCOCO、RefCOCO+、RefCOCOg、ReferIt、Flickr30K和GRefCOCO等六个视觉定位数据集上取得了state-of-the-art的性能。实验结果表明,SimVG不仅提高了定位精度,还提高了效率和收敛速度。例如,在RefCOCO数据集上,SimVG的准确率比现有最佳方法提高了X%。
🎯 应用场景
SimVG在视觉定位领域具有广泛的应用前景,例如图像搜索、人机交互、机器人导航等。它可以帮助机器理解人类的自然语言指令,并准确地定位到图像中的目标对象。未来,SimVG可以进一步扩展到视频定位、3D场景理解等领域,为智能应用提供更强大的视觉感知能力。
📄 摘要(原文)
Visual grounding is a common vision task that involves grounding descriptive sentences to the corresponding regions of an image. Most existing methods use independent image-text encoding and apply complex hand-crafted modules or encoder-decoder architectures for modal interaction and query reasoning. However, their performance significantly drops when dealing with complex textual expressions. This is because the former paradigm only utilizes limited downstream data to fit the multi-modal feature fusion. Therefore, it is only effective when the textual expressions are relatively simple. In contrast, given the wide diversity of textual expressions and the uniqueness of downstream training data, the existing fusion module, which extracts multimodal content from a visual-linguistic context, has not been fully investigated. In this paper, we present a simple yet robust transformer-based framework, SimVG, for visual grounding. Specifically, we decouple visual-linguistic feature fusion from downstream tasks by leveraging existing multimodal pre-trained models and incorporating additional object tokens to facilitate deep integration of downstream and pre-training tasks. Furthermore, we design a dynamic weight-balance distillation method in the multi-branch synchronous learning process to enhance the representation capability of the simpler branch. This branch only consists of a lightweight MLP, which simplifies the structure and improves reasoning speed. Experiments on six widely used VG datasets, i.e., RefCOCO/+/g, ReferIt, Flickr30K, and GRefCOCO, demonstrate the superiority of SimVG. Finally, the proposed method not only achieves improvements in efficiency and convergence speed but also attains new state-of-the-art performance on these benchmarks. Codes and models will be available at \url{https://github.com/Dmmm1997/SimVG}.