TFS-NeRF: Template-Free NeRF for Semantic 3D Reconstruction of Dynamic Scene
作者: Sandika Biswas, Qianyi Wu, Biplab Banerjee, Hamid Rezatofighi
分类: cs.CV
发布日期: 2024-09-26 (更新: 2024-12-04)
备注: Accepted in NeurIPS 2024 https://github.com/sbsws88/TFS-NeRF
💡 一句话要点
提出TFS-NeRF,用于动态场景语义3D重建,无需模板且更高效。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 神经辐射场 动态场景重建 语义分割 可逆神经网络 线性混合蒙皮
📋 核心要点
- 现有动态场景重建方法通常需要深度或光流等额外输入,或依赖预训练图像特征,且难以处理任意刚性、非刚性或可变形实体间的交互。
- TFS-NeRF利用可逆神经网络预测线性混合蒙皮权重,解耦交互实体的运动,并优化每个实体的蒙皮权重,从而高效生成精确的语义可分离几何体。
- 实验结果表明,TFS-NeRF在重建复杂交互场景中的可变形和非可变形对象时,能够生成高质量的重建结果,并提升了训练效率。
📝 摘要(中文)
本文提出TFS-NeRF,一种无需模板的3D语义NeRF,用于从稀疏或单视角RGB视频中重建动态场景,尤其适用于两个实体间交互的场景,并且比其他基于线性混合蒙皮(LBS)的方法更高效。该框架使用可逆神经网络(INN)进行LBS预测,简化了训练过程。通过解耦交互实体的运动并优化每个实体的蒙皮权重,该方法能够高效地生成精确且语义可分离的几何体。大量实验表明,该方法能够高质量地重建复杂交互中的可变形和非可变形对象,并且相比现有方法提高了训练效率。
🔬 方法详解
问题定义:论文旨在解决动态场景下,特别是存在多个实体交互时,如何高效且准确地进行3D语义重建的问题。现有方法要么依赖额外的输入信息(如深度图或光流),要么需要预训练的图像特征,或者训练时间过长,难以满足实际应用的需求。此外,一些基于模板的方法虽然效果较好,但依赖于特定物体的先验知识,泛化能力有限。
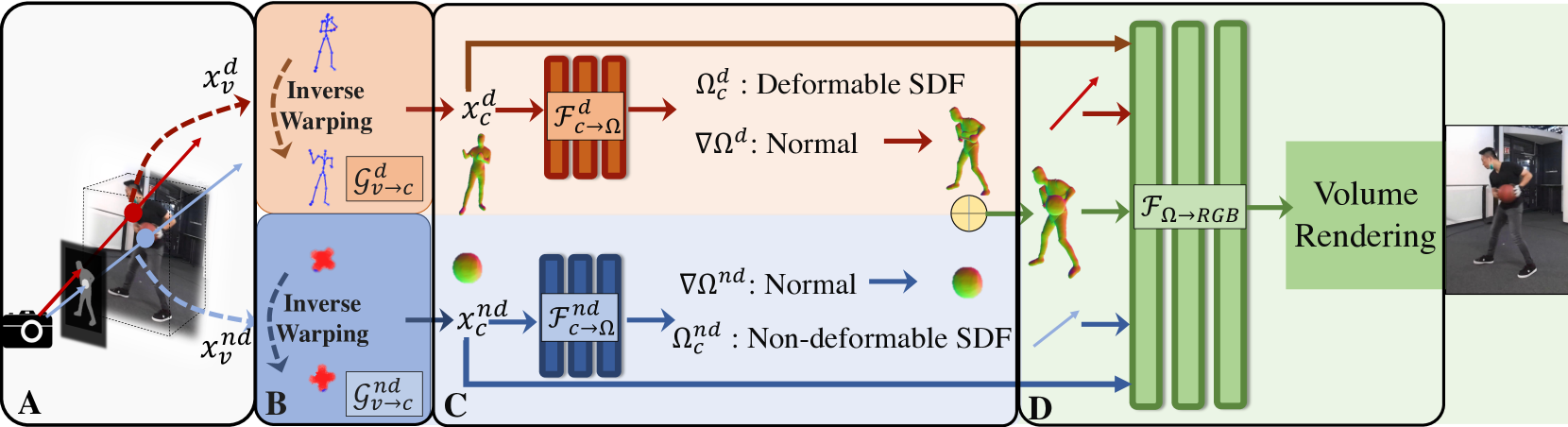
核心思路:TFS-NeRF的核心思路是利用可逆神经网络(INN)来预测线性混合蒙皮(LBS)权重,从而避免了复杂的优化过程,并实现更高效的训练。通过解耦不同实体的运动,并为每个实体优化蒙皮权重,该方法能够更好地捕捉场景中的复杂交互,并生成语义可分离的几何体。
技术框架:TFS-NeRF的整体框架包括以下几个主要模块:1) 输入RGB视频帧;2) 使用可逆神经网络(INN)预测每个实体的LBS权重;3) 解耦不同实体的运动;4) 基于NeRF进行3D场景重建,并优化每个实体的蒙皮权重;5) 输出语义分割的3D重建结果。该框架采用端到端的训练方式,可以从稀疏或单视角的RGB视频中学习到场景的几何和语义信息。
关键创新:TFS-NeRF的关键创新在于使用可逆神经网络(INN)来预测LBS权重,这极大地简化了训练过程,并提高了训练效率。与传统的LBS方法相比,INN能够更有效地学习到场景中的复杂形变,并避免了复杂的优化过程。此外,通过解耦不同实体的运动,该方法能够更好地处理多个实体交互的场景。
关键设计:TFS-NeRF的关键设计包括:1) 使用可逆神经网络(INN)作为LBS权重预测器,INN的具体结构和参数设置未知;2) 设计了针对每个实体的蒙皮权重优化策略,具体损失函数未知;3) 采用了NeRF作为3D场景重建的骨干网络,NeRF的具体参数设置未知;4) 针对语义分割任务,可能使用了额外的损失函数或网络结构,具体细节未知。
🖼️ 关键图片


📊 实验亮点
论文通过大量实验验证了TFS-NeRF的有效性。实验结果表明,TFS-NeRF在重建复杂交互场景中的可变形和非可变形对象时,能够生成高质量的重建结果,并且相比现有基于LBS的方法,显著提高了训练效率。具体的性能数据和提升幅度在摘要中未明确给出,需要查阅论文全文。
🎯 应用场景
TFS-NeRF在机器人交互、虚拟现实、增强现实、自动驾驶等领域具有广泛的应用前景。例如,可以用于机器人对动态环境的感知和理解,帮助机器人更好地与人或物体进行交互。在虚拟现实和增强现实中,可以用于创建更逼真的虚拟场景和交互体验。在自动驾驶领域,可以用于对动态交通场景的建模和预测,提高自动驾驶系统的安全性。
📄 摘要(原文)
Despite advancements in Neural Implicit models for 3D surface reconstruction, handling dynamic environments with interactions between arbitrary rigid, non-rigid, or deformable entities remains challenging. The generic reconstruction methods adaptable to such dynamic scenes often require additional inputs like depth or optical flow or rely on pre-trained image features for reasonable outcomes. These methods typically use latent codes to capture frame-by-frame deformations. Another set of dynamic scene reconstruction methods, are entity-specific, mostly focusing on humans, and relies on template models. In contrast, some template-free methods bypass these requirements and adopt traditional LBS (Linear Blend Skinning) weights for a detailed representation of deformable object motions, although they involve complex optimizations leading to lengthy training times. To this end, as a remedy, this paper introduces TFS-NeRF, a template-free 3D semantic NeRF for dynamic scenes captured from sparse or single-view RGB videos, featuring interactions among two entities and more time-efficient than other LBS-based approaches. Our framework uses an Invertible Neural Network (INN) for LBS prediction, simplifying the training process. By disentangling the motions of interacting entities and optimizing per-entity skinning weights, our method efficiently generates accurate, semantically separable geometries. Extensive experiments demonstrate that our approach produces high-quality reconstructions of both deformable and non-deformable objects in complex interactions, with improved training efficiency compared to existing methods.