EAGLE: Towards Efficient Arbitrary Referring Visual Prompts Comprehension for Multimodal Large Language Models
作者: Jiacheng Zhang, Yang Jiao, Shaoxiang Chen, Jingjing Chen, Yu-Gang Jiang
分类: cs.CV
发布日期: 2024-09-25 (更新: 2024-09-26)
💡 一句话要点
EAGLE:高效理解任意指示性视觉提示的多模态大语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 指示性视觉提示 视觉提示理解 几何无关学习 指令调优
📋 核心要点
- 现有MLLM处理指示性视觉提示时,架构冗余,且在面对多样化的提示时泛化能力不足。
- EAGLE将视觉提示视为彩色补丁,嵌入空间概念,利用MLLM自身进行语义理解,减少训练量。
- 提出几何无关学习范式(GAL),解耦区域理解与提示格式,提升模型对不同提示的适应性。
📝 摘要(中文)
近年来,多模态大语言模型(MLLMs)因其卓越的内容推理和指令遵循能力而引起了广泛的研究兴趣。为了有效地指导MLLM,除了传统的语言表达之外,通过在图像上用笔刷绘制来指示对象的方法(称为“指示性视觉提示”)已经成为一种流行的工具,因为它能够有效地将用户的意图与特定的图像区域对齐。为了适应最常见的指示性视觉提示,即点、框和掩码,现有的方法最初利用专门的特征编码模块来捕获这些提示所指示的突出显示区域的语义。随后,通过在精心策划的多模态指令数据集上进行微调,将这些编码的区域特征适配到MLLM。然而,这种设计存在架构冗余的问题。此外,当在现实场景中遇到各种各样的任意指示性视觉提示时,它们在有效泛化方面面临挑战。为了解决上述问题,我们提出了一种新的MLLM——EAGLE,它能够理解任意指示性视觉提示,并且比现有方法需要更少的训练工作。具体来说,我们的EAGLE保持了指示性视觉提示的固有格式,即作为在给定图像上渲染的彩色补丁,用于进行指令调优。我们的方法将指示性视觉提示嵌入为空间概念,传达MLLM可以理解的特定空间区域,这些区域的语义理解源于MLLM本身。此外,我们还提出了一种几何无关学习范式(GAL),以进一步解耦MLLM的区域级理解与指示性视觉提示的特定格式。大量的实验证明了我们提出的方法的有效性。
🔬 方法详解
问题定义:现有MLLM在处理指示性视觉提示时,通常采用专门的特征编码模块来处理点、框、掩码等不同类型的提示,导致架构冗余。此外,这些方法在面对现实场景中各种各样的任意指示性视觉提示时,泛化能力较差,难以有效理解用户意图。
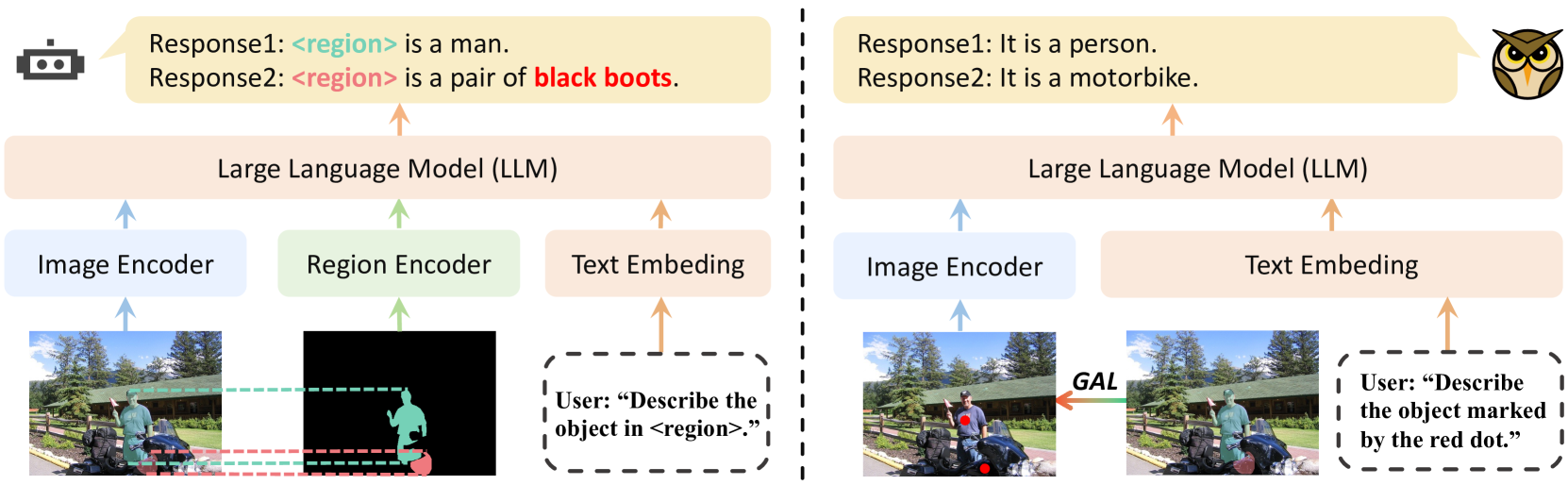
核心思路:EAGLE的核心思路是将指示性视觉提示视为一种空间概念,直接以彩色补丁的形式嵌入到图像中,利用MLLM自身对图像的理解能力来识别和理解这些区域的语义。通过这种方式,避免了对不同类型提示进行单独编码,简化了模型结构,并提高了泛化能力。
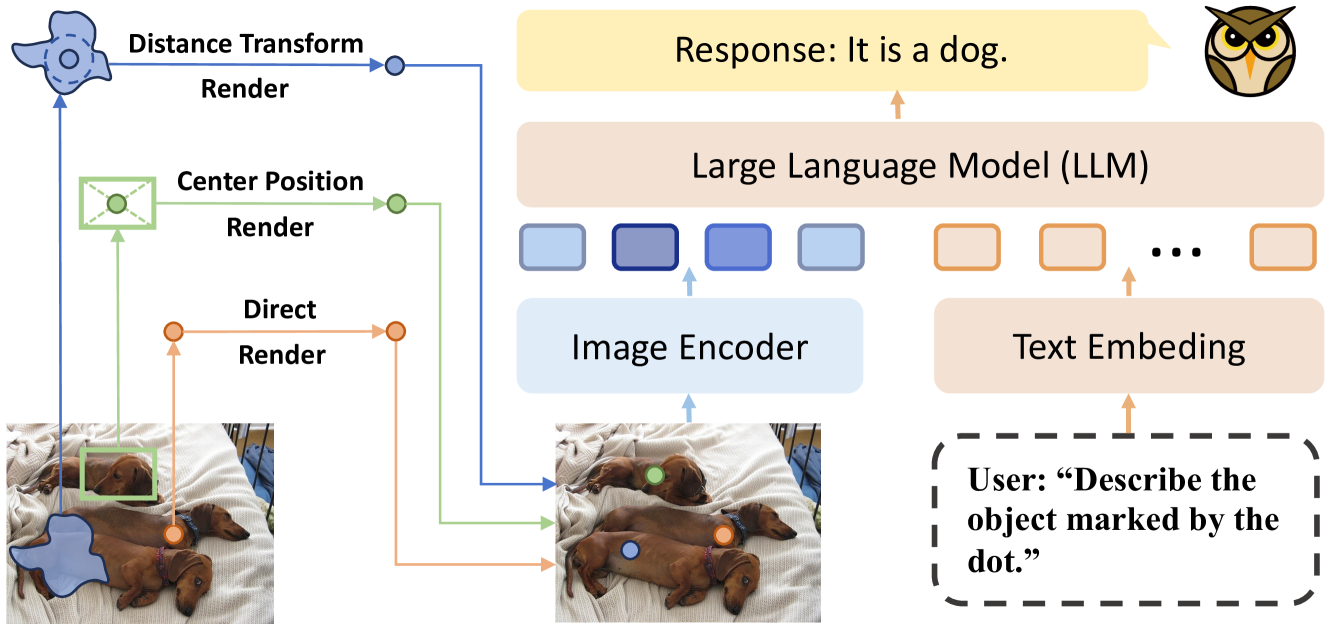
技术框架:EAGLE的整体框架包括以下几个主要步骤:1. 将指示性视觉提示以彩色补丁的形式渲染到输入图像上。2. 将渲染后的图像输入到MLLM中。3. MLLM利用其自身的视觉理解能力,识别并理解彩色补丁所代表的区域。4. MLLM根据理解到的视觉信息和给定的文本指令,生成相应的输出。
关键创新:EAGLE最重要的技术创新点在于它将指示性视觉提示视为一种空间概念,并直接嵌入到图像中,而不是像现有方法那样使用专门的特征编码模块。这种方法避免了对不同类型提示进行单独编码,简化了模型结构,并提高了泛化能力。此外,提出的几何无关学习范式(GAL)进一步解耦了区域理解与提示格式,增强了模型对不同提示的适应性。
关键设计:EAGLE的关键设计包括:1. 使用彩色补丁来表示指示性视觉提示,颜色可以根据需要进行调整。2. 采用几何无关学习范式(GAL),通过特定的损失函数来鼓励模型学习与提示格式无关的区域级理解。3. 在指令调优阶段,使用包含各种类型指示性视觉提示的数据集进行训练,以提高模型的泛化能力。
🖼️ 关键图片
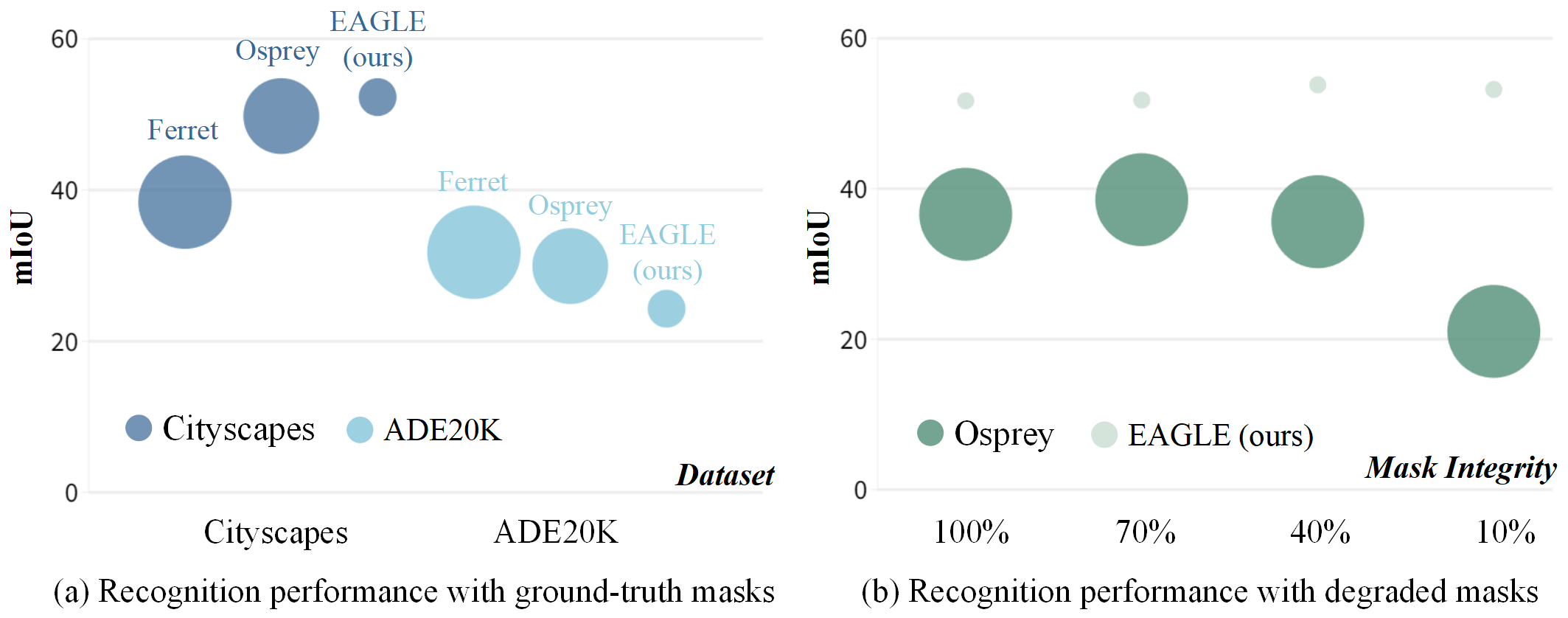
📊 实验亮点
论文通过大量实验证明了EAGLE的有效性。相比现有方法,EAGLE在理解任意指示性视觉提示方面表现出更强的泛化能力,并且需要更少的训练资源。具体性能数据和对比基线信息在论文中详细给出。
🎯 应用场景
EAGLE可应用于各种需要理解用户指定图像区域的多模态任务,例如图像编辑、视觉问答、目标定位等。该研究成果有助于提升人机交互的自然性和效率,并推动多模态大语言模型在实际场景中的应用。
📄 摘要(原文)
Recently, Multimodal Large Language Models (MLLMs) have sparked great research interests owing to their exceptional content-reasoning and instruction-following capabilities. To effectively instruct an MLLM, in addition to conventional language expressions, the practice of referring to objects by painting with brushes on images has emerged as a prevalent tool (referred to as "referring visual prompts") due to its efficacy in aligning the user's intention with specific image regions. To accommodate the most common referring visual prompts, namely points, boxes, and masks, existing approaches initially utilize specialized feature encoding modules to capture the semantics of the highlighted areas indicated by these prompts. Subsequently, these encoded region features are adapted to MLLMs through fine-tuning on a meticulously curated multimodal instruction dataset. However, such designs suffer from redundancy in architecture. Moreover, they face challenges in effectively generalizing when encountering a diverse range of arbitrary referring visual prompts in real-life scenarios. To address the above issues, we propose EAGLE, a novel MLLM that empowers comprehension of arbitrary referring visual prompts with less training efforts than existing approaches. Specifically, our EAGLE maintains the innate format of the referring visual prompts as colored patches rendered on the given image for conducting the instruction tuning. Our approach embeds referring visual prompts as spatial concepts conveying specific spatial areas comprehensible to the MLLM, with the semantic comprehension of these regions originating from the MLLM itself. Besides, we also propose a Geometry-Agnostic Learning paradigm (GAL) to further disentangle the MLLM's region-level comprehension with the specific formats of referring visual prompts. Extensive experiments are conducted to prove the effectiveness of our proposed method.