Pix2Next: Leveraging Vision Foundation Models for RGB to NIR Image Translation
作者: Youngwan Jin, Incheol Park, Hanbin Song, Hyeongjin Ju, Yagiz Nalcakan, Shiho Kim
分类: cs.CV, cs.AI
发布日期: 2024-09-25 (更新: 2025-04-23)
备注: 19 pages,12 figures
DOI: 10.3390/technologies13040154
💡 一句话要点
Pix2Next:利用视觉基础模型实现RGB到近红外图像的转换
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像转换 近红外图像 视觉基础模型 交叉注意力机制 GAN 目标检测 图像生成
📋 核心要点
- 现有RGB到NIR图像转换方法难以捕捉全局上下文和保持光谱特征,导致生成图像质量不高。
- Pix2Next利用视觉基础模型和交叉注意力机制,在编码器-解码器架构中实现RGB到NIR的转换,兼顾全局信息和局部细节。
- 实验表明,Pix2Next在RANUS数据集上显著提升了图像质量(FID提升34.81%),并改善了下游目标检测任务的性能。
📝 摘要(中文)
本文提出了一种新颖的图像到图像转换框架Pix2Next,旨在解决从RGB图像生成高质量近红外(NIR)图像的挑战。我们的方法在一个编码器-解码器架构中利用了最先进的视觉基础模型(VFM),并结合了交叉注意力机制以增强特征集成。这种设计捕获了详细的全局表示,并保留了必要的频谱特征,将RGB到NIR的转换视为不仅仅是一个简单的域迁移问题。一个多尺度的PatchGAN判别器确保了在不同细节层次上生成逼真的图像,同时精心设计的损失函数将全局上下文理解与局部特征保持相结合。我们在RANUS数据集上进行了实验,证明了Pix2Next在定量指标和视觉质量方面的优势,与现有方法相比,FID得分提高了34.81%。此外,我们通过展示在下游目标检测任务中使用生成的NIR数据来扩充有限的真实NIR数据集,从而提高了性能,证明了Pix2Next的实际效用。所提出的方法能够在不需要额外数据采集或注释工作的情况下扩展NIR数据集,从而可能加速基于NIR的计算机视觉应用的进步。
🔬 方法详解
问题定义:论文旨在解决RGB图像到高质量近红外(NIR)图像转换的问题。现有方法通常将此问题视为简单的域迁移,忽略了NIR图像特有的光谱信息和全局上下文,导致生成的NIR图像质量不高,细节模糊,无法有效应用于下游任务。
核心思路:论文的核心思路是利用视觉基础模型(VFM)强大的特征提取能力,结合交叉注意力机制,在RGB到NIR的转换过程中更好地捕捉全局上下文信息,并保留NIR图像的关键光谱特征。通过这种方式,将RGB到NIR的转换提升到更高层次的图像理解和生成。
技术框架:Pix2Next采用编码器-解码器架构。编码器部分利用VFM提取RGB图像的深层特征。在编码器和解码器之间,使用交叉注意力机制融合RGB特征和NIR特征,从而实现特征的有效集成。解码器部分负责将融合后的特征重建为NIR图像。此外,还使用多尺度PatchGAN判别器来提高生成图像的真实感。
关键创新:最重要的技术创新点在于将视觉基础模型(VFM)引入RGB到NIR的图像转换任务中,并结合交叉注意力机制,实现了全局上下文信息的有效利用和光谱特征的保留。这与以往仅关注域迁移的方法有本质区别,显著提升了生成NIR图像的质量。
关键设计:关键设计包括:1) 使用预训练的视觉基础模型作为编码器,利用其强大的特征提取能力;2) 引入交叉注意力机制,在编码器和解码器之间融合RGB和NIR特征;3) 使用多尺度PatchGAN判别器,从不同尺度上评估生成图像的真实感;4) 设计了包括L1损失、感知损失和对抗损失在内的损失函数,以保证生成图像的质量和真实性。
🖼️ 关键图片

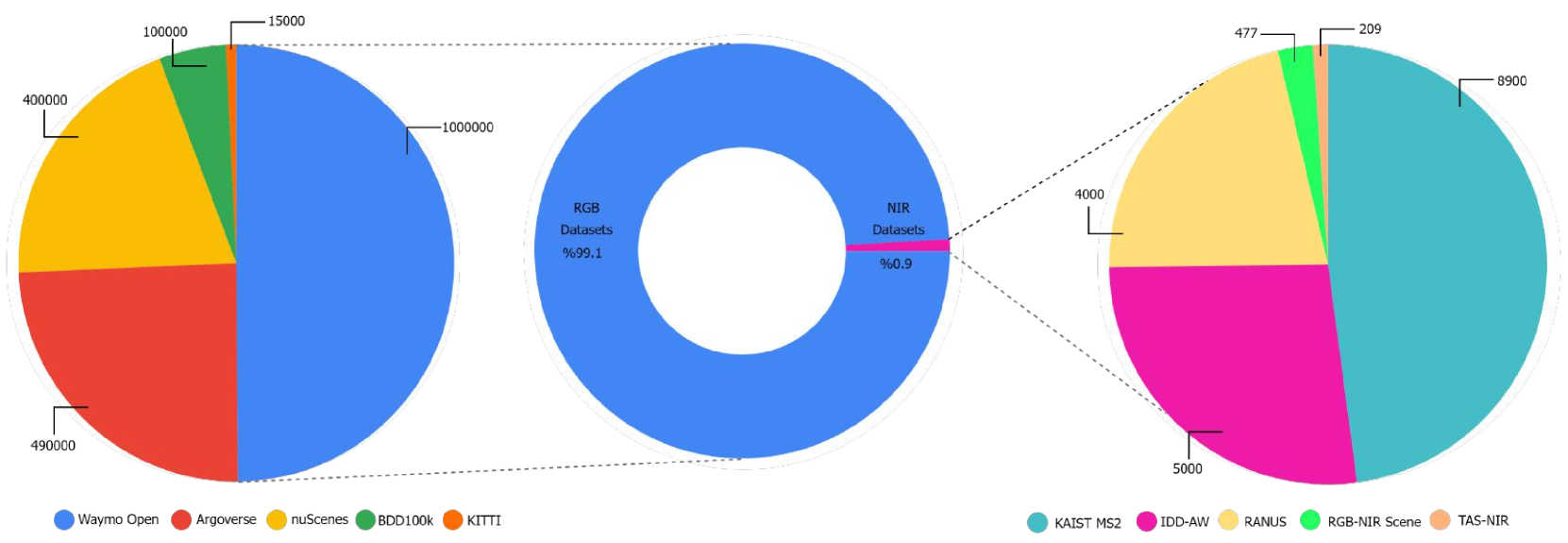
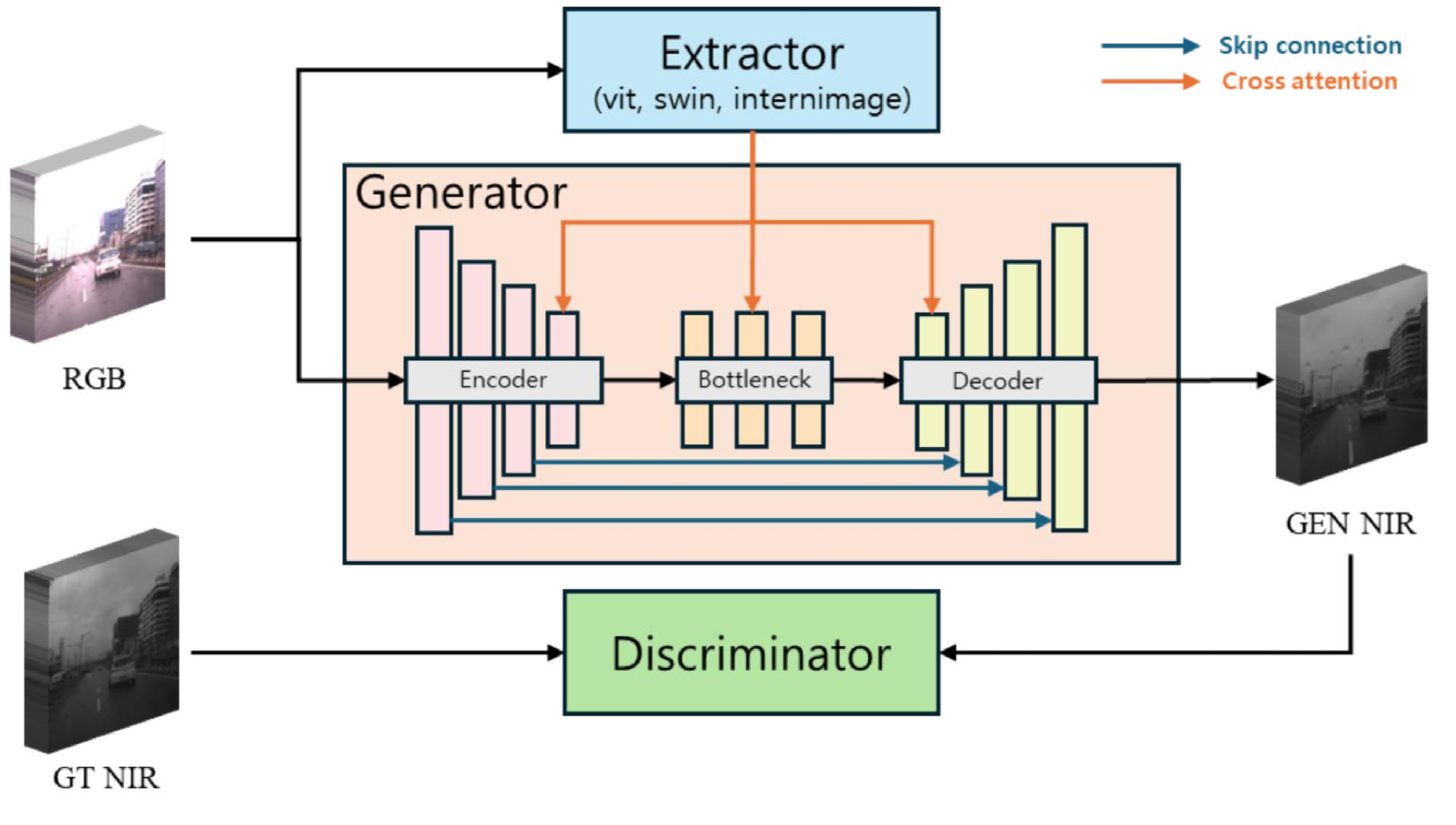
📊 实验亮点
实验结果表明,Pix2Next在RANUS数据集上取得了显著的性能提升,FID得分比现有方法提高了34.81%。此外,将生成的NIR图像用于下游目标检测任务时,性能也得到了显著改善,证明了Pix2Next生成的NIR图像具有很高的实用价值。这些结果表明,Pix2Next能够有效地生成高质量的NIR图像,并为NIR相关的计算机视觉应用提供有力支持。
🎯 应用场景
该研究成果可广泛应用于遥感图像处理、自动驾驶、安防监控等领域。通过将低成本的RGB图像转换为高质量的NIR图像,可以有效扩展NIR数据的可用性,降低数据采集成本,并提升相关计算机视觉任务的性能,例如目标检测、图像分割等。该方法还有助于在缺乏NIR数据的场景下进行算法开发和验证。
📄 摘要(原文)
This paper proposes Pix2Next, a novel image-to-image translation framework designed to address the challenge of generating high-quality Near-Infrared (NIR) images from RGB inputs. Our approach leverages a state-of-the-art Vision Foundation Model (VFM) within an encoder-decoder architecture, incorporating cross-attention mechanisms to enhance feature integration. This design captures detailed global representations and preserves essential spectral characteristics, treating RGB-to-NIR translation as more than a simple domain transfer problem. A multi-scale PatchGAN discriminator ensures realistic image generation at various detail levels, while carefully designed loss functions couple global context understanding with local feature preservation. We performed experiments on the RANUS dataset to demonstrate Pix2Next's advantages in quantitative metrics and visual quality, improving the FID score by 34.81% compared to existing methods. Furthermore, we demonstrate the practical utility of Pix2Next by showing improved performance on a downstream object detection task using generated NIR data to augment limited real NIR datasets. The proposed approach enables the scaling up of NIR datasets without additional data acquisition or annotation efforts, potentially accelerating advancements in NIR-based computer vision applications.