FisheyeDepth: A Real Scale Self-Supervised Depth Estimation Model for Fisheye Camera
作者: Guoyang Zhao, Yuxuan Liu, Weiqing Qi, Fulong Ma, Ming Liu, Jun Ma
分类: cs.CV, cs.RO
发布日期: 2024-09-23 (更新: 2025-03-08)
期刊: ICRA 2025 IEEE International Conference on Robotics and Automation
🔗 代码/项目: GITHUB
💡 一句话要点
FisheyeDepth:为鱼眼相机设计的真实尺度自监督深度估计模型
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 鱼眼相机 深度估计 自监督学习 图像畸变 真实尺度 机器人 自动驾驶
📋 核心要点
- 鱼眼相机虽具有广阔视野,但其图像畸变和缺乏真实深度数据限制了其在深度估计中的应用。
- FisheyeDepth通过将鱼眼相机模型融入训练,并利用真实尺度位姿信息,有效处理了图像畸变并提升了深度估计精度。
- 实验结果表明,该模型在鱼眼图像深度估计任务中表现出优越的性能和鲁棒性。
📝 摘要(中文)
本文提出FisheyeDepth,一个专为鱼眼相机设计的自监督深度估计模型。该模型将鱼眼相机模型融入到训练过程中的投影和反投影阶段,以处理图像畸变,从而提高深度估计的准确性和训练的稳定性。此外,该模型将真实尺度的位姿信息融入到连续帧之间的几何投影中,取代了传统位姿网络估计的位姿,为机器人任务提供了必要的物理深度,并简化了训练和推理过程。同时,设计了一种多通道输出策略,通过自适应地融合不同尺度的特征来提高鲁棒性,减少来自真实位姿数据的噪声。在公共数据集和真实场景中的评估表明,该模型在鱼眼图像深度估计方面具有优越的性能和鲁棒性。
🔬 方法详解
问题定义:现有的深度估计方法在处理鱼眼相机图像时,由于鱼眼镜头固有的畸变,会导致深度估计精度下降。同时,缺乏鱼眼相机的真实深度数据,使得有监督的深度估计方法难以应用。传统自监督方法依赖位姿网络估计相机位姿,精度有限,难以提供真实尺度的深度信息。
核心思路:FisheyeDepth的核心思路是利用自监督学习框架,同时考虑鱼眼相机的成像特性和真实尺度的位姿信息。通过将鱼眼相机模型集成到训练过程中,可以有效地处理图像畸变。利用真实尺度的位姿信息,可以直接获得物理意义上的深度,避免了传统方法中尺度模糊的问题。
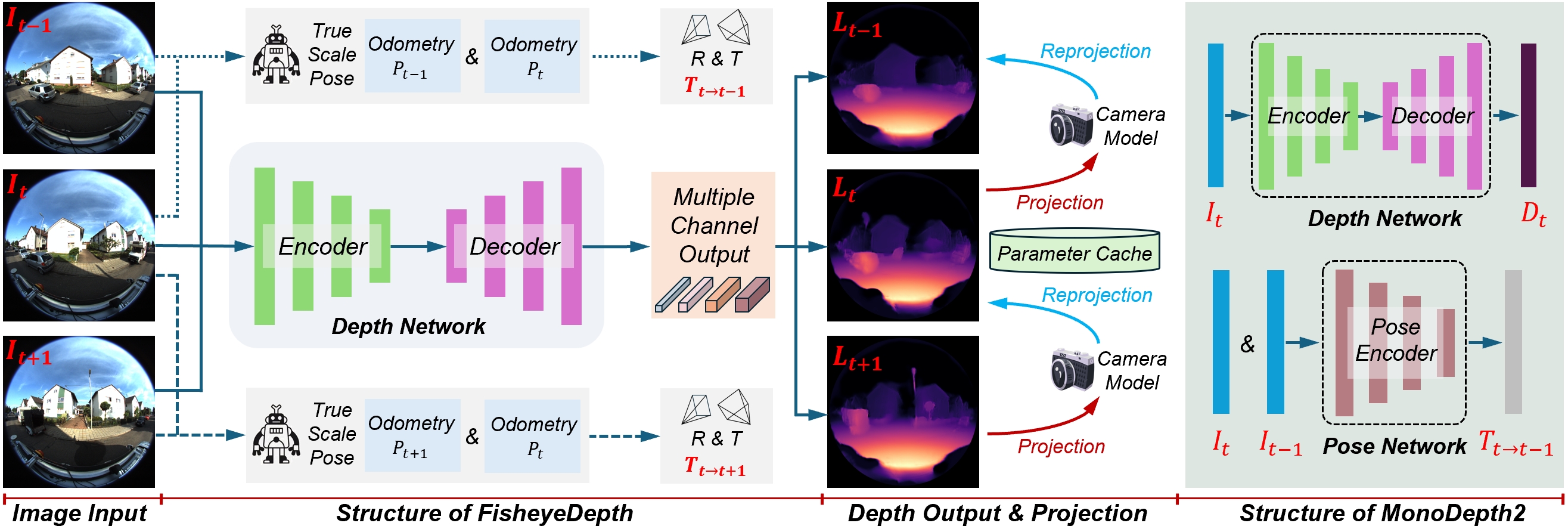
技术框架:FisheyeDepth的整体框架是一个自监督深度估计网络,包括深度估计网络、位姿估计模块(可选,但被真实位姿替代)和图像重建模块。深度估计网络负责从鱼眼图像中预测深度图。图像重建模块利用预测的深度图和相机位姿,将源图像投影到目标图像,并计算重建误差。通过最小化重建误差来训练深度估计网络。此外,还引入了多通道输出策略,融合不同尺度的特征。
关键创新:该论文的关键创新在于:1) 将鱼眼相机模型融入到自监督深度估计框架中,解决了鱼眼图像的畸变问题。2) 利用真实尺度的位姿信息,取代了传统位姿网络估计的位姿,从而获得了真实尺度的深度信息。3) 提出了多通道输出策略,提高了模型的鲁棒性。
关键设计:在训练过程中,使用了鱼眼相机的内参矩阵来对图像进行畸变校正和投影。损失函数主要包括光度一致性损失和深度平滑损失。光度一致性损失用于衡量重建图像和目标图像之间的差异。深度平滑损失用于约束深度图的平滑性。多通道输出策略通过在不同尺度的特征图上预测深度,然后进行融合,从而提高模型的鲁棒性。具体融合方式未知,原文未详细说明。
🖼️ 关键图片


📊 实验亮点
该模型在鱼眼图像深度估计任务中取得了显著的性能提升。通过在公共数据集和真实场景中的评估,证明了该模型在处理鱼眼图像畸变和提供真实尺度深度信息方面的有效性。具体性能数据和对比基线在摘要中未提及,需查阅原文。
🎯 应用场景
FisheyeDepth在机器人导航、自动驾驶、虚拟现实等领域具有广泛的应用前景。它可以为机器人提供准确的深度信息,帮助机器人进行环境感知和路径规划。在自动驾驶领域,可以提高车辆对周围环境的感知能力,从而提高驾驶安全性。在虚拟现实领域,可以生成更逼真的三维场景。
📄 摘要(原文)
Accurate depth estimation is crucial for 3D scene comprehension in robotics and autonomous vehicles. Fisheye cameras, known for their wide field of view, have inherent geometric benefits. However, their use in depth estimation is restricted by a scarcity of ground truth data and image distortions. We present FisheyeDepth, a self-supervised depth estimation model tailored for fisheye cameras. We incorporate a fisheye camera model into the projection and reprojection stages during training to handle image distortions, thereby improving depth estimation accuracy and training stability. Furthermore, we incorporate real-scale pose information into the geometric projection between consecutive frames, replacing the poses estimated by the conventional pose network. Essentially, this method offers the necessary physical depth for robotic tasks, and also streamlines the training and inference procedures. Additionally, we devise a multi-channel output strategy to improve robustness by adaptively fusing features at various scales, which reduces the noise from real pose data. We demonstrate the superior performance and robustness of our model in fisheye image depth estimation through evaluations on public datasets and real-world scenarios. The project website is available at: https://github.com/guoyangzhao/FisheyeDepth.