EgoAvatar: Egocentric View-Driven and Photorealistic Full-body Avatars
作者: Jianchun Chen, Jian Wang, Yinda Zhang, Rohit Pandey, Thabo Beeler, Marc Habermann, Christian Theobalt
分类: cs.CV, cs.GR
发布日期: 2024-09-22 (更新: 2024-10-08)
备注: Project Page: https://vcai.mpi-inf.mpg.de/projects/EgoAvatar/
💡 一句话要点
EgoAvatar:提出首个基于第一视角视频的逼真全身数字替身建模与驱动方法
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 数字替身 人称视角 运动捕捉 单目视频 远程呈现
📋 核心要点
- 现有方法主要集中于人称视角运动捕捉、头部建模或多视角重建,缺乏统一的解决方案,难以实现轻量化、低功耗的全身数字替身。
- EgoAvatar提出一种个性化的人称视角远程呈现方法,联合建模逼真的数字替身,并仅通过单目人称视角视频驱动替身运动。
- 论文构建了新的具有挑战性的基准数据集,实验结果表明,该方法优于现有基线方法和同类方法,在人称视角和逼真远程呈现方面取得了显著进展。
📝 摘要(中文)
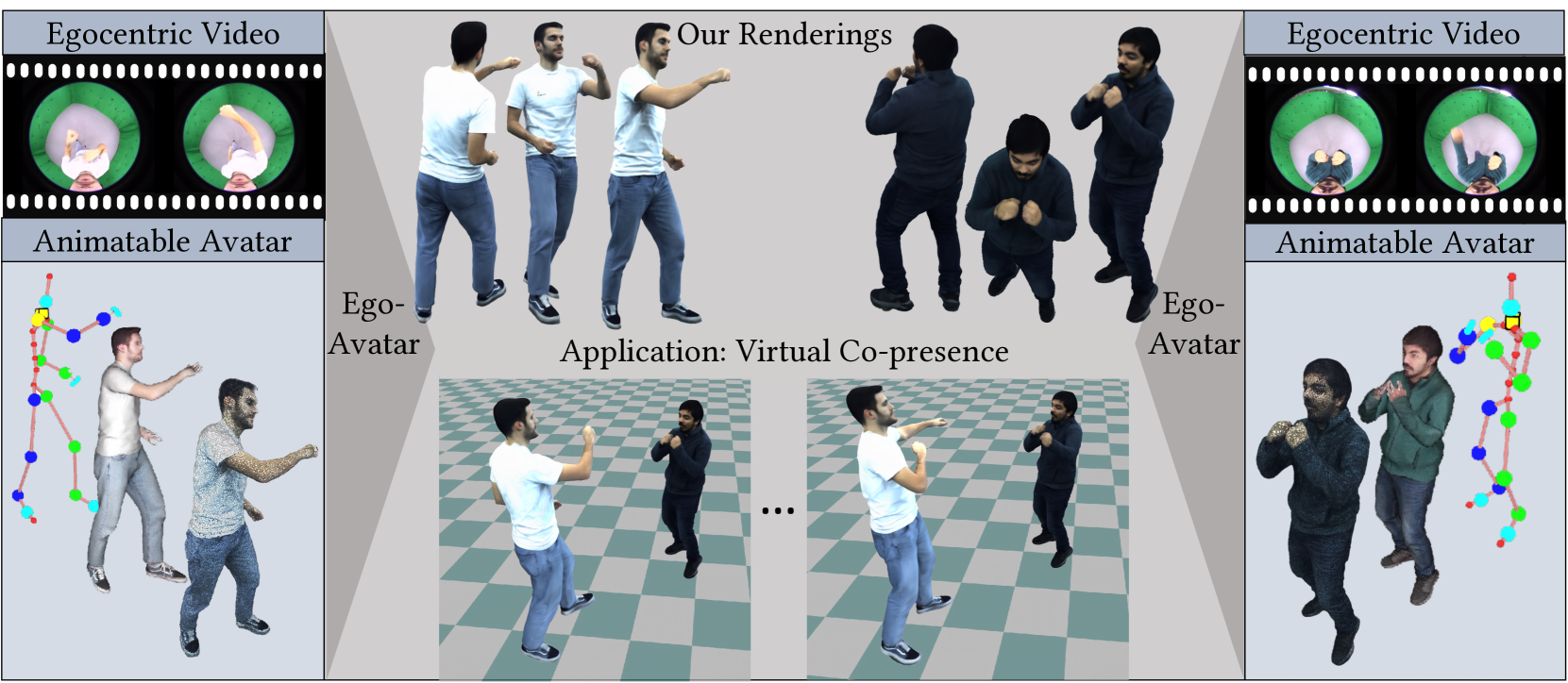
本文首次提出了一种人称视角的远程呈现方法,该方法可以联合建模逼真的数字替身,并仅通过单目人称视角视频驱动它。首先,提出了一个可动画的角色模型,该模型仅由骨骼运动驱动,同时能够建模几何形状和外观。然后,引入了个性化的人称视角运动捕捉组件,该组件可以从人称视角视频中恢复全身运动。最后,将恢复的姿势应用于角色模型,并执行测试时的网格细化,以使几何形状忠实地投影到人称视角中。为了验证设计选择,提出了一个新的具有挑战性的基准,该基准提供了真实人类执行各种运动的配对人称视角和密集多视角视频。实验表明,该方法在人称视角和逼真的远程呈现方面迈出了重要一步,优于基线方法和竞争方法。
🔬 方法详解
问题定义:现有的人称视角远程呈现方法存在局限性,要么依赖多视角数据,要么只关注头部建模,无法仅使用单目人称视角视频驱动全身数字替身,且难以保证替身的逼真度。这限制了其在VR/AR等需要轻量化、低功耗解决方案的应用场景中的实用性。
核心思路:EgoAvatar的核心思路是联合建模一个可动画的、具有逼真几何和外观的角色模型,并设计一个个性化的人称视角运动捕捉组件,从单目视频中恢复全身运动。通过将恢复的姿势应用于角色模型,并进行网格细化,实现逼真的替身驱动。
技术框架:EgoAvatar包含三个主要模块:1) 可动画的角色模型,用于建模几何和外观;2) 个性化的人称视角运动捕捉组件,用于从单目视频中恢复全身运动;3) 网格细化模块,用于在测试时优化替身几何形状,使其与人称视角视频对齐。整体流程是:输入人称视角视频,通过运动捕捉组件恢复姿势,将姿势应用于角色模型,最后通过网格细化模块优化替身。
关键创新:该方法最重要的创新点在于首次实现了仅使用单目人称视角视频进行全身数字替身的建模与驱动。与现有方法相比,无需多视角数据或额外的传感器,降低了系统复杂度和成本,更易于部署和应用。
关键设计:论文的关键设计包括:1) 设计了一个可动画的角色模型,能够通过骨骼运动控制替身的姿态和形状;2) 开发了一个个性化的运动捕捉组件,能够从人称视角视频中准确地估计全身姿势;3) 提出了一种网格细化方法,能够在测试时优化替身的几何形状,使其与输入视频对齐。具体的损失函数和网络结构等细节在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
EgoAvatar在提出的新基准数据集上进行了评估,实验结果表明,该方法在姿态估计精度和替身逼真度方面均优于现有方法。具体而言,该方法在人称视角视频驱动的全身替身重建任务上取得了显著的性能提升,为实现逼真的人称视角远程呈现奠定了基础。
🎯 应用场景
EgoAvatar在VR/AR远程协作、虚拟会议、游戏、社交娱乐等领域具有广泛的应用前景。它可以让用户在虚拟环境中以逼真的数字替身进行交互,提升沉浸感和交互体验。该技术还可以应用于远程医疗、教育等领域,实现更高效、更自然的远程沟通。
📄 摘要(原文)
Immersive VR telepresence ideally means being able to interact and communicate with digital avatars that are indistinguishable from and precisely reflect the behaviour of their real counterparts. The core technical challenge is two fold: Creating a digital double that faithfully reflects the real human and tracking the real human solely from egocentric sensing devices that are lightweight and have a low energy consumption, e.g. a single RGB camera. Up to date, no unified solution to this problem exists as recent works solely focus on egocentric motion capture, only model the head, or build avatars from multi-view captures. In this work, we, for the first time in literature, propose a person-specific egocentric telepresence approach, which jointly models the photoreal digital avatar while also driving it from a single egocentric video. We first present a character model that is animatible, i.e. can be solely driven by skeletal motion, while being capable of modeling geometry and appearance. Then, we introduce a personalized egocentric motion capture component, which recovers full-body motion from an egocentric video. Finally, we apply the recovered pose to our character model and perform a test-time mesh refinement such that the geometry faithfully projects onto the egocentric view. To validate our design choices, we propose a new and challenging benchmark, which provides paired egocentric and dense multi-view videos of real humans performing various motions. Our experiments demonstrate a clear step towards egocentric and photoreal telepresence as our method outperforms baselines as well as competing methods. For more details, code, and data, we refer to our project page.