MOSE: Monocular Semantic Reconstruction Using NeRF-Lifted Noisy Priors
作者: Zhenhua Du, Binbin Xu, Haoyu Zhang, Kai Huo, Shuaifeng Zhi
分类: cs.CV, cs.AI, cs.RO
发布日期: 2024-09-21
备注: 8 pages, 10 figures
💡 一句话要点
MOSE:利用NeRF提升的单目语义重建,解决单目图像三维场景理解难题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 单目视觉 三维重建 语义分割 神经辐射场 场景理解
📋 核心要点
- 单目图像的三维语义重建面临几何信息不足和二维先验信息不完善的挑战。
- MOSE利用类别无关的分割掩码引导语义一致性,并结合语义信息对无纹理区域进行平滑正则化。
- 实验表明,MOSE在ScanNet数据集上,三维语义分割、二维语义分割和三维表面重建任务中均优于现有方法。
📝 摘要(中文)
本文提出了一种名为MOSE的神经场语义重建方法,旨在将单目图像中推断出的带噪声的先验信息提升到三维空间,从而在三维和二维空间中生成精确的语义和几何结构。该方法的核心思想是利用通用的、类别无关的分割掩码作为指导,以促进训练过程中渲染语义的局部一致性。借助语义信息,我们进一步对无纹理区域应用平滑正则化,以获得更好的几何质量,从而实现几何和语义的相互促进。在ScanNet数据集上的实验表明,在三维语义分割、二维语义分割和三维表面重建任务中,MOSE优于相关的基线方法,并在所有指标上都取得了提升。
🔬 方法详解
问题定义:从单目图像重建稠密且带有语义标注的三维网格仍然是一个具有挑战性的任务。现有的方法往往缺乏足够的几何指导,并且受限于不完善的、视角相关的二维先验信息,导致重建的三维场景在几何精度和语义准确性上都存在不足。
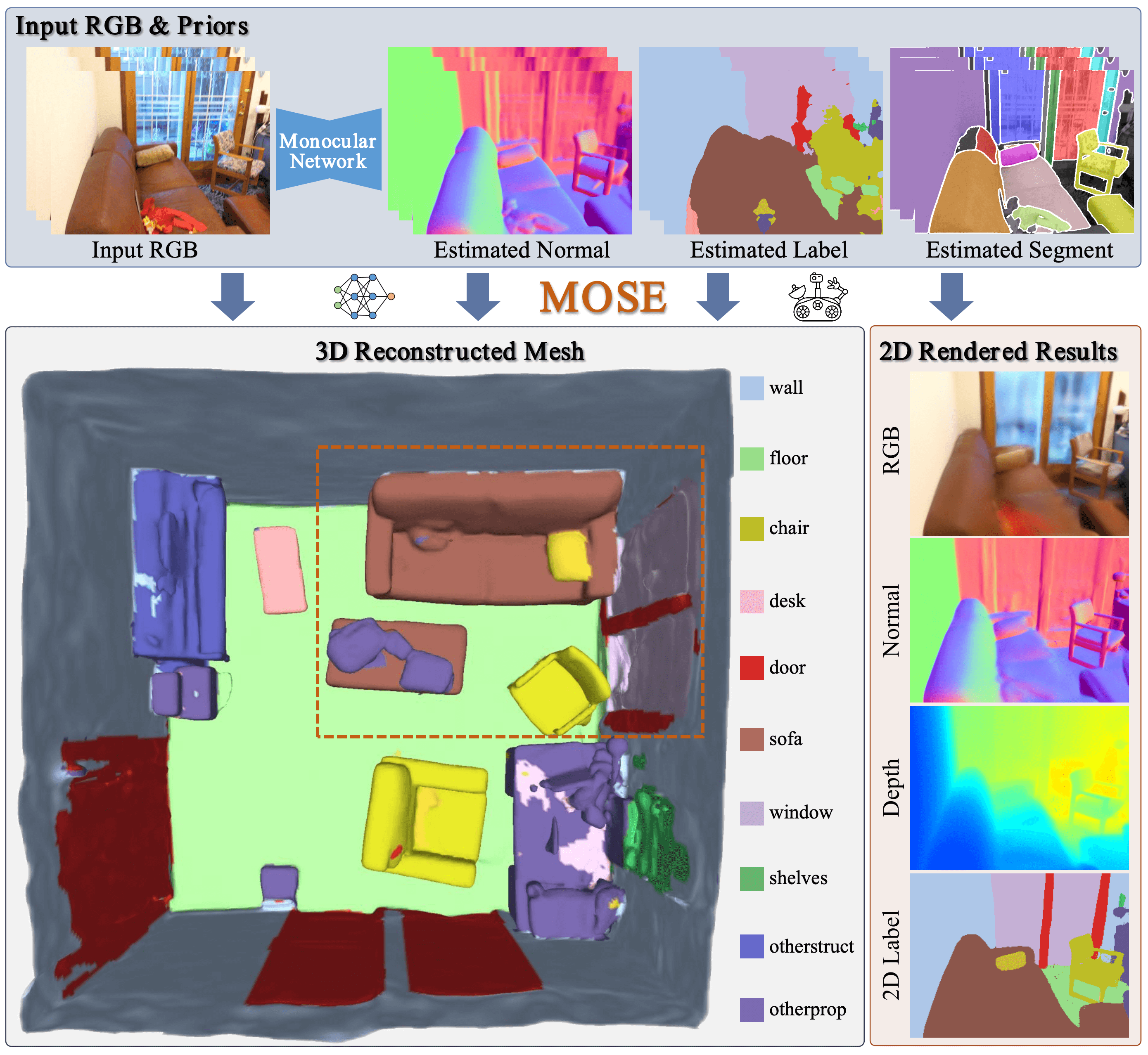
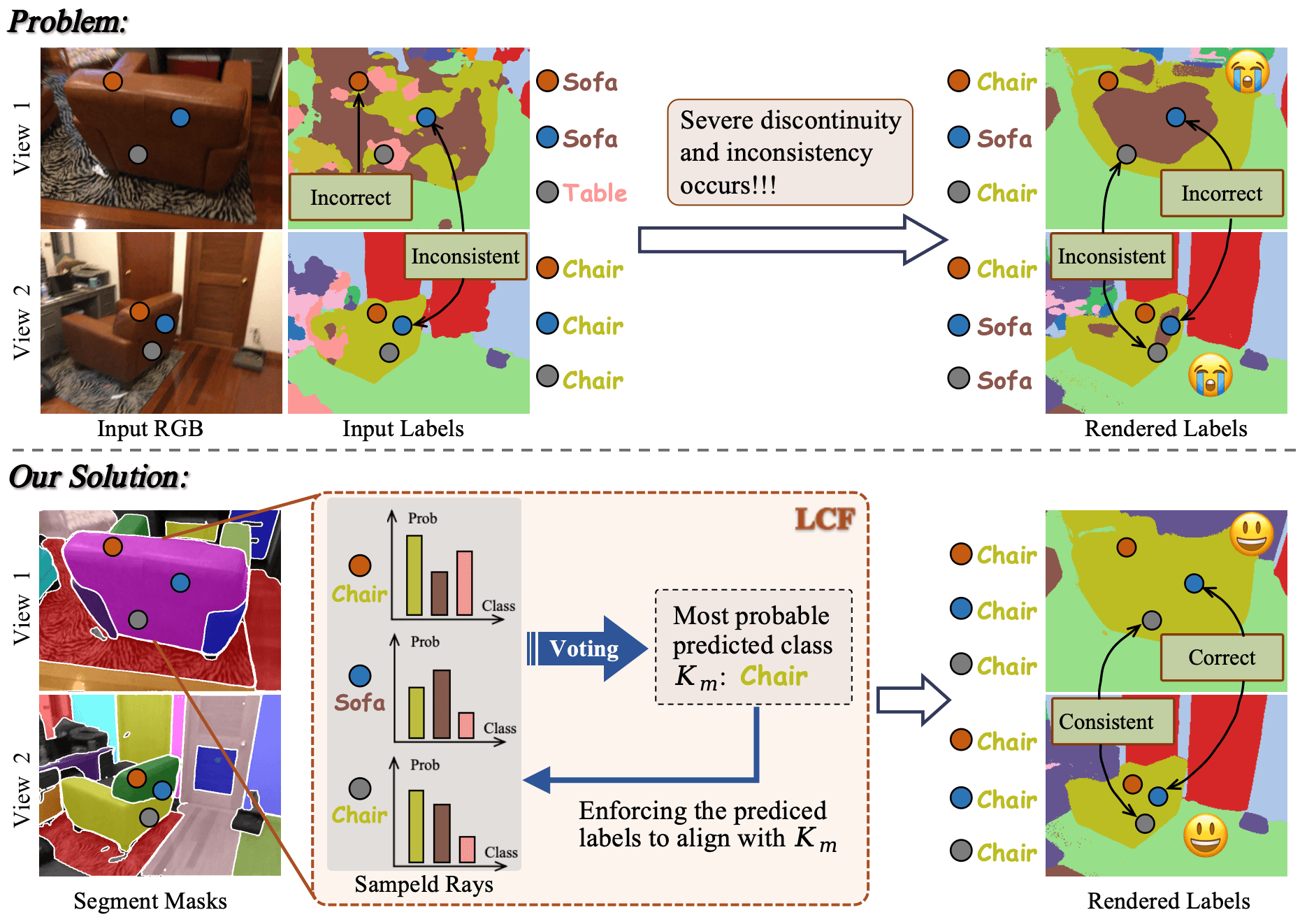
核心思路:MOSE的核心思路是将从单目图像中推断出的、可能带有噪声的二维语义先验信息提升到三维空间,并利用神经辐射场(NeRF)的强大渲染能力,通过优化神经场来生成高质量的三维语义和几何结构。关键在于利用类别无关的分割掩码来约束渲染语义的局部一致性,从而减少噪声先验的影响。
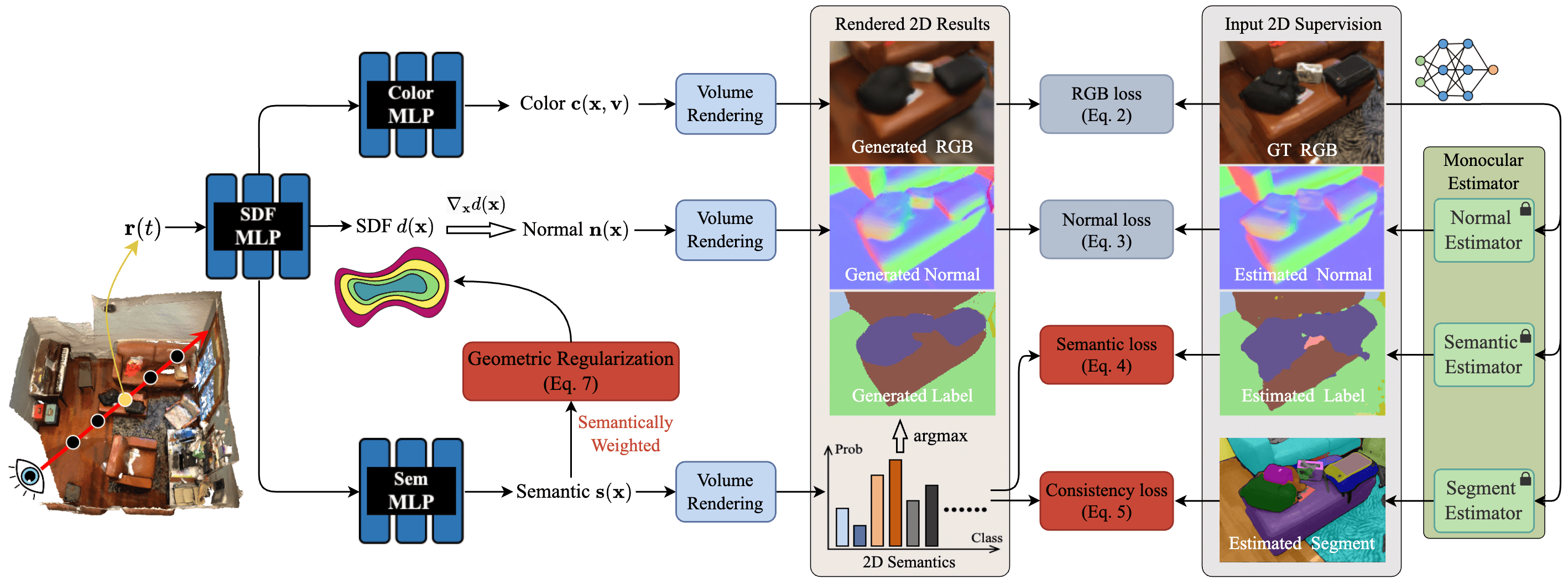
技术框架:MOSE的整体框架包含以下几个主要模块:1) 图像特征提取模块,用于提取单目图像的二维特征;2) 语义先验推断模块,用于预测图像的语义分割掩码;3) NeRF-Lifted 模块,将二维特征和语义先验提升到三维空间,构建神经辐射场;4) 渲染模块,从神经辐射场中渲染出二维图像和语义分割图;5) 损失函数计算模块,计算渲染结果与真实值之间的差异,并进行优化。
关键创新:MOSE的关键创新在于:1) 利用类别无关的分割掩码作为几何约束,促进渲染语义的局部一致性,从而有效地利用了带噪声的语义先验;2) 提出了一种基于语义信息的平滑正则化方法,用于优化无纹理区域的几何结构,实现了几何和语义的相互促进。
关键设计:MOSE的关键设计包括:1) 使用MLP来表示神经辐射场,将三维坐标和视角方向映射到颜色和密度;2) 使用交叉熵损失函数来优化语义分割结果;3) 使用L1损失函数来优化几何重建结果;4) 使用平滑正则化项来约束无纹理区域的几何结构,该正则化项基于语义分割结果,对属于同一语义类别的相邻点施加平滑约束。
🖼️ 关键图片
📊 实验亮点
MOSE在ScanNet数据集上进行了实验,结果表明,在三维语义分割任务中,MOSE的mIoU指标优于现有方法,提升幅度达到显著水平。在二维语义分割任务中,MOSE的像素精度和mIoU指标也优于其他基线方法。此外,MOSE在三维表面重建任务中也取得了更好的几何精度,证明了其在单目三维场景理解方面的优越性。
🎯 应用场景
MOSE具有广泛的应用前景,例如:机器人导航与场景理解,可以帮助机器人在未知环境中进行自主导航和交互;增强现实与虚拟现实,可以为用户提供更逼真的三维场景体验;三维地图重建,可以用于构建高精度的三维地图,为自动驾驶和城市规划提供支持。该研究的未来影响在于推动单目视觉三维重建技术的发展,降低三维场景理解的成本和门槛。
📄 摘要(原文)
Accurately reconstructing dense and semantically annotated 3D meshes from monocular images remains a challenging task due to the lack of geometry guidance and imperfect view-dependent 2D priors. Though we have witnessed recent advancements in implicit neural scene representations enabling precise 2D rendering simply from multi-view images, there have been few works addressing 3D scene understanding with monocular priors alone. In this paper, we propose MOSE, a neural field semantic reconstruction approach to lift inferred image-level noisy priors to 3D, producing accurate semantics and geometry in both 3D and 2D space. The key motivation for our method is to leverage generic class-agnostic segment masks as guidance to promote local consistency of rendered semantics during training. With the help of semantics, we further apply a smoothness regularization to texture-less regions for better geometric quality, thus achieving mutual benefits of geometry and semantics. Experiments on the ScanNet dataset show that our MOSE outperforms relevant baselines across all metrics on tasks of 3D semantic segmentation, 2D semantic segmentation and 3D surface reconstruction.