SSE: Multimodal Semantic Data Selection and Enrichment for Industrial-scale Data Assimilation
作者: Maying Shen, Nadine Chang, Sifei Liu, Jose M. Alvarez
分类: cs.CV
发布日期: 2024-09-20
💡 一句话要点
提出SSE框架,通过语义选择和增强解决工业级数据同化中的数据过载问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数据选择 数据增强 语义信息 工业应用 数据同化
📋 核心要点
- 工业应用中,数据量激增导致模型训练成本过高,而模型性能提升有限,亟需有效的数据选择方法。
- SSE框架通过语义多样性选择关键数据子集,并利用未标注数据进行语义增强,提升模型性能。
- 实验证明,SSE框架能在减少训练数据量的同时保持甚至提升模型性能,验证了语义多样性的重要性。
📝 摘要(中文)
近年来,人工智能领域的数据量呈爆炸式增长。尤其是在自动驾驶等工业应用中,模型训练的计算预算已经超出限制,而模型性能却趋于饱和,但数据仍在不断涌入。为了应对这一数据洪流,我们提出了一个框架,用于选择语义上最具多样性和重要性的数据集部分。然后,通过从海量未标记数据池中发现有意义的新数据,进一步在语义上丰富它。重要的是,我们可以利用基础模型为每个数据点生成语义,从而提供可解释性。我们通过定量实验表明,我们的语义选择和增强框架(SSE)可以a) 通过更小的训练数据集成功地保持模型性能,以及b) 通过丰富更小的数据集来提高模型性能,而不会超过原始数据集的大小。因此,我们证明了语义多样性对于最佳数据选择和模型性能至关重要。
🔬 方法详解
问题定义:论文旨在解决工业规模数据同化中,由于数据量过大导致的模型训练计算成本高昂和模型性能饱和的问题。现有方法难以有效利用海量数据,且缺乏对数据语义信息的有效利用,导致数据冗余和训练效率低下。
核心思路:论文的核心思路是利用数据的语义信息,首先通过语义选择,选择最具代表性和多样性的数据子集,从而减少训练数据量;然后通过语义增强,从海量未标注数据中挖掘有价值的信息,进一步提升模型性能。这种方法旨在在保证模型性能的前提下,降低训练成本。
技术框架:SSE框架包含两个主要阶段:语义选择和语义增强。在语义选择阶段,利用预训练的基础模型(Foundation Models)提取数据的语义特征,并基于这些特征计算数据的多样性,选择最具代表性的数据子集。在语义增强阶段,利用未标注数据,通过某种方式(具体方法未知)扩充已选择的数据集,从而进一步提升模型性能。整个框架旨在实现数据的高效利用和模型性能的提升。
关键创新:该论文的关键创新在于将语义信息引入到数据选择和增强过程中。传统的数据选择方法往往基于数据的统计特征或模型预测结果,而忽略了数据的语义信息。通过利用预训练的基础模型,可以有效地提取数据的语义特征,从而实现更有效的数据选择和增强。
关键设计:论文中关于语义多样性的具体计算方法、未标注数据的具体增强方式以及基础模型的选择等关键技术细节未知。损失函数和网络结构等细节也未在摘要中提及。
🖼️ 关键图片
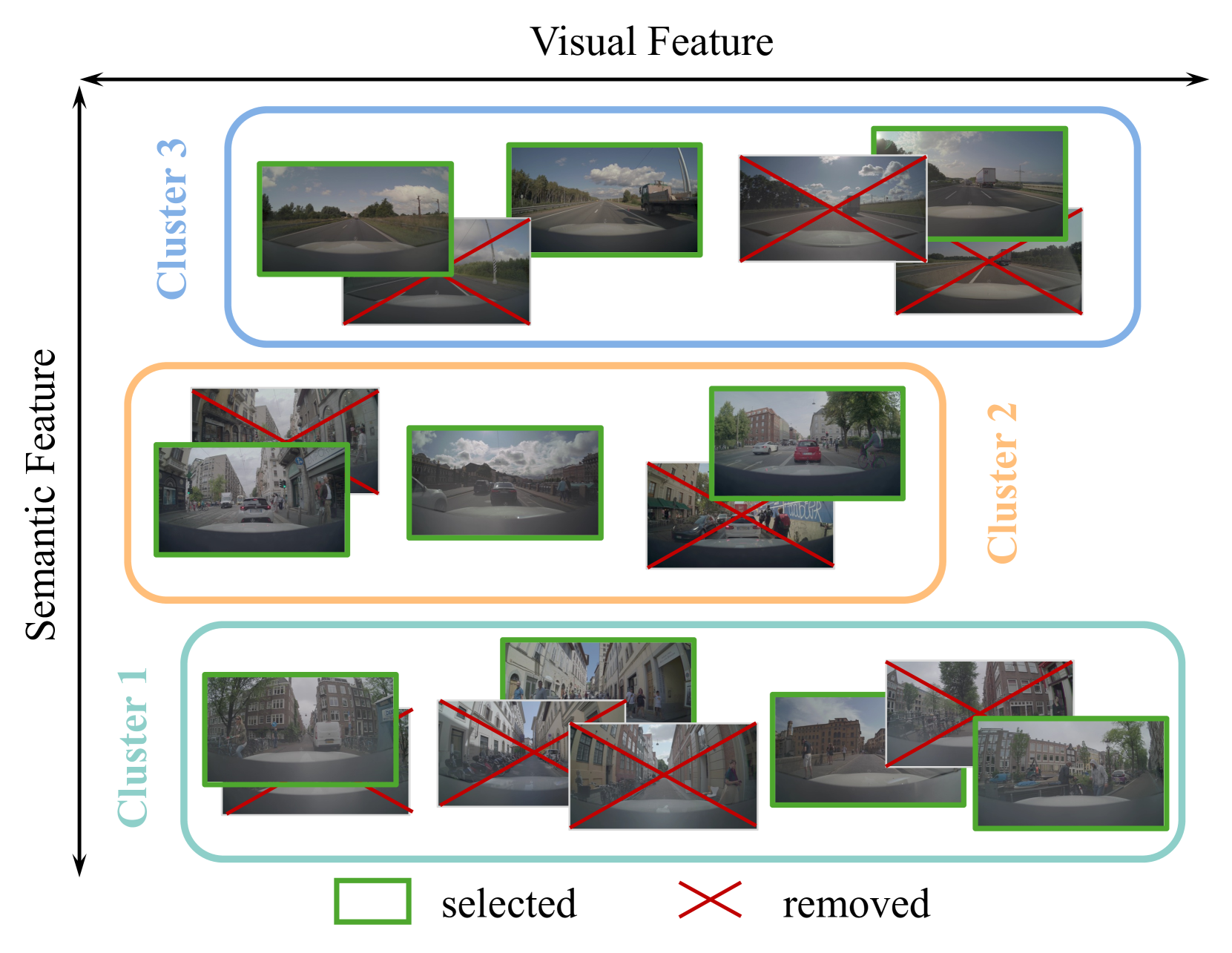


📊 实验亮点
实验结果表明,SSE框架能够在减少训练数据集大小的同时,成功保持模型性能。更重要的是,通过对较小的数据集进行语义增强,SSE框架能够在不超出原始数据集大小的情况下,进一步提高模型性能。这些结果突出了语义多样性在优化数据选择和提升模型性能方面的重要性。
🎯 应用场景
该研究成果可广泛应用于自动驾驶、智能制造、智慧城市等工业领域,尤其是在数据量巨大且标注成本高昂的场景下。通过减少训练数据量和提升模型性能,可以显著降低计算成本,加速模型迭代,并最终提升产品的智能化水平。该方法还有潜力应用于其他机器学习任务,例如图像识别、自然语言处理等。
📄 摘要(原文)
In recent years, the data collected for artificial intelligence has grown to an unmanageable amount. Particularly within industrial applications, such as autonomous vehicles, model training computation budgets are being exceeded while model performance is saturating -- and yet more data continues to pour in. To navigate the flood of data, we propose a framework to select the most semantically diverse and important dataset portion. Then, we further semantically enrich it by discovering meaningful new data from a massive unlabeled data pool. Importantly, we can provide explainability by leveraging foundation models to generate semantics for every data point. We quantitatively show that our Semantic Selection and Enrichment framework (SSE) can a) successfully maintain model performance with a smaller training dataset and b) improve model performance by enriching the smaller dataset without exceeding the original dataset size. Consequently, we demonstrate that semantic diversity is imperative for optimal data selection and model performance.