Efficient and Discriminative Image Feature Extraction for Universal Image Retrieval
作者: Morris Florek, David Tschirschwitz, Björn Barz, Volker Rodehorst
分类: cs.CV
发布日期: 2024-09-20
🔗 代码/项目: GITHUB
💡 一句话要点
提出一种高效的通用图像检索特征提取框架,解决领域泛化性问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 通用图像检索 特征提取 多领域学习 度量学习 视觉-语义模型
📋 核心要点
- 现有图像检索系统在不同领域表现差异大,泛化能力不足,难以适应通用场景。
- 构建多领域数据集M4D-35k,并探索视觉-语义基础模型和度量学习损失函数的组合,实现高效训练。
- 在Google通用图像嵌入挑战赛中取得优异成绩,参数量远低于领先方法,性能接近SOTA。
📝 摘要(中文)
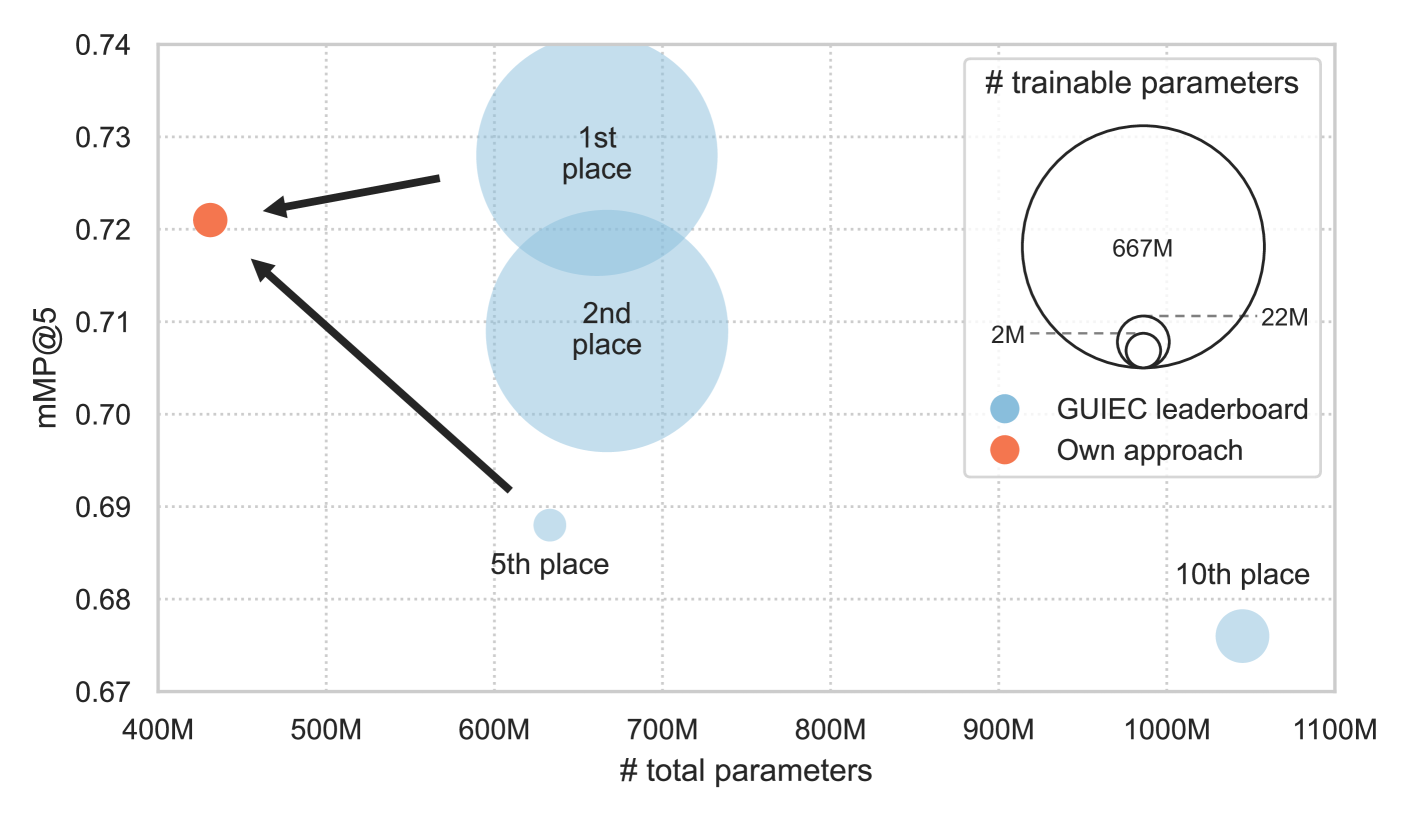
当前图像检索系统常面临领域特定性和泛化性问题。本研究旨在通过开发一种计算高效的通用特征提取训练框架来克服这些限制,该框架能够提供跨各种领域的强大语义图像表示。为此,我们整理了一个名为M4D-35k的多领域训练数据集,从而实现资源高效的训练。此外,我们还对各种最先进的视觉-语义基础模型和基于边距的度量学习损失函数进行了广泛的评估和比较,以确定它们对高效通用特征提取的适用性。尽管计算资源有限,我们在Google通用图像嵌入挑战赛中取得了接近最先进水平的结果,mMP@5为0.721。这使我们的方法在排行榜上名列第二,仅比表现最佳的方法落后0.7个百分点。然而,我们的模型总体参数减少了32%,可训练参数减少了289倍。与具有类似计算要求的方法相比,我们优于之前的最先进水平3.3个百分点。我们发布了我们的代码和M4D-35k训练集注释。
🔬 方法详解
问题定义:现有图像检索系统往往针对特定领域进行优化,导致在其他领域表现不佳,泛化能力差。这限制了它们在通用图像检索场景中的应用。现有的方法通常需要大量的计算资源和领域特定的数据进行训练,难以满足资源受限场景的需求。
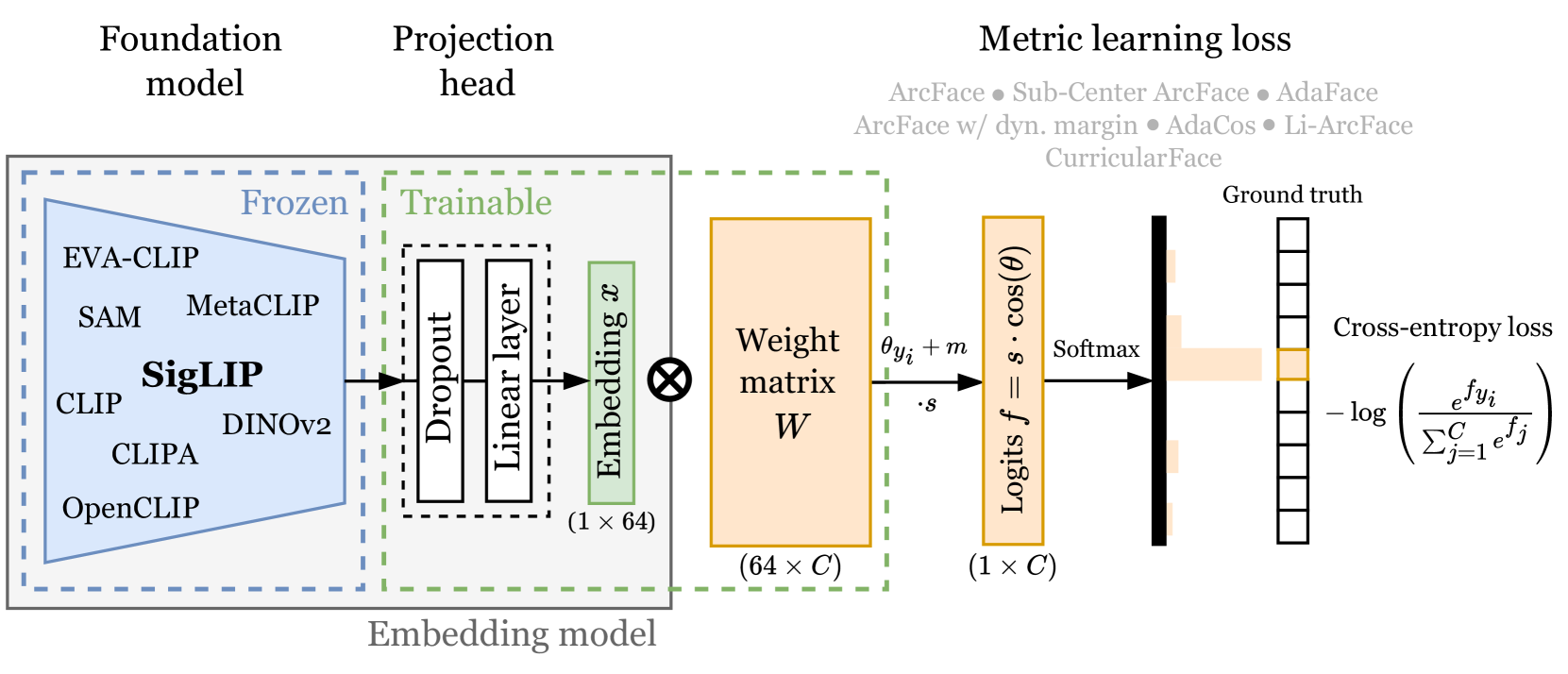
核心思路:论文的核心思路是设计一个计算高效的训练框架,利用多领域数据集训练出一个通用的图像特征提取器。通过探索不同的视觉-语义基础模型和度量学习损失函数,找到在资源有限的情况下能够提供强大语义表示的最佳组合。
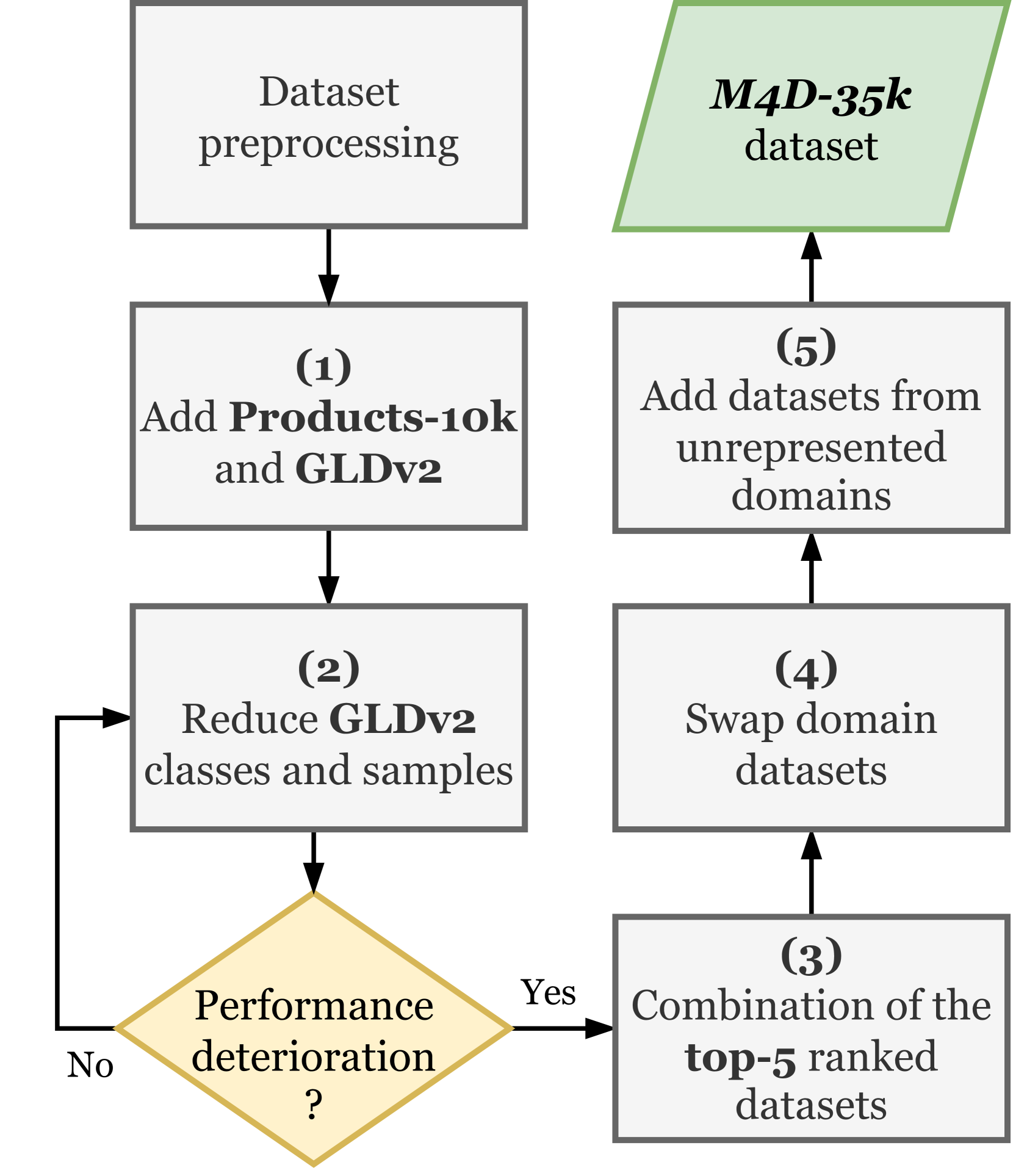
技术框架:整体框架包含数据准备、模型选择、训练和评估四个主要阶段。首先,构建多领域数据集M4D-35k。然后,选择合适的视觉-语义基础模型作为特征提取器,并选择合适的度量学习损失函数进行优化。最后,在标准数据集上评估模型的性能。
关键创新:主要创新在于构建了M4D-35k数据集,并系统地评估了各种视觉-语义基础模型和度量学习损失函数在通用图像检索任务中的性能。通过实验发现,在资源受限的情况下,特定的模型和损失函数组合能够达到接近SOTA的性能,同时显著降低了计算成本。
关键设计:M4D-35k数据集包含多个领域的图像,并提供了详细的标注信息。在模型选择方面,论文探索了多种视觉-语义基础模型,如CLIP、ALIGN等。在损失函数方面,论文比较了多种基于边距的度量学习损失函数,如ArcFace、CosFace等。最终选择的模型和损失函数组合在计算效率和性能之间取得了良好的平衡。
🖼️ 关键图片
📊 实验亮点
在Google通用图像嵌入挑战赛中,该方法取得了mMP@5为0.721的成绩,位列第二,仅比最佳方法低0.7个百分点。更重要的是,该模型的参数量比最佳方法少32%,可训练参数少289倍。与计算资源相似的方法相比,该方法性能提升了3.3个百分点,证明了其高效性和优越性。
🎯 应用场景
该研究成果可应用于通用图像搜索引擎、跨领域图像检索、图像分类、目标检测等领域。通过高效的特征提取,可以降低计算成本,提高检索效率,并增强模型在不同领域的泛化能力。该方法尤其适用于资源受限的移动设备和嵌入式系统。
📄 摘要(原文)
Current image retrieval systems often face domain specificity and generalization issues. This study aims to overcome these limitations by developing a computationally efficient training framework for a universal feature extractor that provides strong semantic image representations across various domains. To this end, we curated a multi-domain training dataset, called M4D-35k, which allows for resource-efficient training. Additionally, we conduct an extensive evaluation and comparison of various state-of-the-art visual-semantic foundation models and margin-based metric learning loss functions regarding their suitability for efficient universal feature extraction. Despite constrained computational resources, we achieve near state-of-the-art results on the Google Universal Image Embedding Challenge, with a mMP@5 of 0.721. This places our method at the second rank on the leaderboard, just 0.7 percentage points behind the best performing method. However, our model has 32% fewer overall parameters and 289 times fewer trainable parameters. Compared to methods with similar computational requirements, we outperform the previous state of the art by 3.3 percentage points. We release our code and M4D-35k training set annotations at https://github.com/morrisfl/UniFEx.