DAP-LED: Learning Degradation-Aware Priors with CLIP for Joint Low-light Enhancement and Deblurring
作者: Ling Wang, Chen Wu, Lin Wang
分类: cs.CV, cs.AI
发布日期: 2024-09-20
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出DAP-LED,利用CLIP学习退化先验,联合解决弱光增强和去模糊问题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 弱光增强 图像去模糊 对比语言-图像预训练 CLIP Transformer 联合学习 图像退化 视觉感知
📋 核心要点
- 现有方法串联弱光增强和去模糊模型,易产生伪影或难以学习黑暗区域运动信息。
- DAP-LED利用CLIP学习图像退化程度,指导Transformer网络联合优化增强和去模糊任务。
- 实验表明,DAP-LED在弱光增强和去模糊任务上达到SOTA,并提升了下游任务性能。
📝 摘要(中文)
在夜间,自动驾驶车辆和机器人常因光照不足以及RGB相机长时间曝光导致运动模糊,难以获得可靠的视觉感知。现有方法通常串联现成的弱光增强和去模糊模型,但容易在过度曝光区域产生伪影(如颜色失真),或难以学习黑暗区域的运动线索。本文发现视觉-语言模型(如CLIP)能够全面感知夜间不同的退化程度。因此,提出了一种基于Transformer的联合学习框架DAP-LED,可以联合实现弱光增强和去模糊,从而有益于黑暗环境下的深度估计、分割和检测等下游任务。核心思想是利用CLIP自适应地学习夜间图像的退化程度,从而学习丰富的语义信息和视觉表示,以优化联合任务。为此,首先引入CLIP引导的跨融合模块,从图像嵌入中获得多尺度、逐块的退化热图。然后,通过设计的CLIP增强Transformer块融合热图,以保留有用的退化信息,从而有效地优化模型。实验结果表明,与现有方法相比,DAP-LED在黑暗环境中实现了最先进的性能。同时,增强后的结果被证明对三个下游任务有效。
🔬 方法详解
问题定义:论文旨在解决夜间或低光照条件下,由于光照不足和相机运动导致的图像质量下降问题,具体表现为图像亮度低和运动模糊。现有方法通常采用串联的弱光增强和去模糊模型,但这些方法容易引入颜色失真等伪影,并且难以有效学习黑暗区域的运动信息。
核心思路:论文的核心思路是利用对比语言-图像预训练模型(CLIP)对图像退化程度的感知能力,自适应地学习图像的退化先验信息。通过将CLIP的语义理解能力融入到弱光增强和去模糊任务中,可以更有效地指导模型的优化,从而避免伪影并更好地恢复图像细节。
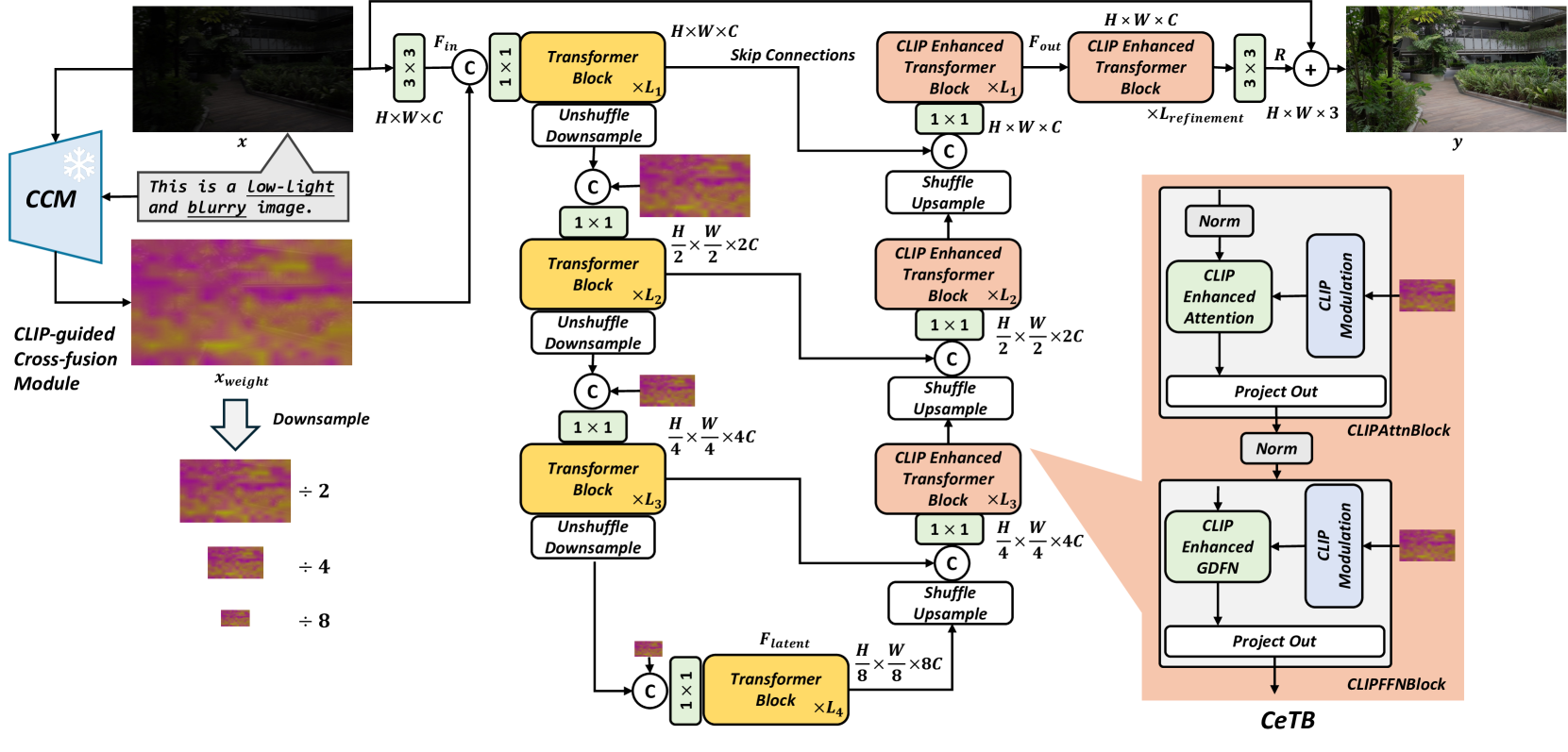
技术框架:DAP-LED框架主要包含以下几个模块:1) CLIP引导的跨融合模块:用于从输入图像的嵌入中提取多尺度、逐块的退化热图。2) CLIP增强Transformer块:用于融合退化热图,并利用Transformer的强大建模能力,保留有用的退化信息。3) 联合学习框架:将弱光增强和去模糊任务整合到一个统一的框架中进行优化,从而实现更好的性能。
关键创新:论文的关键创新在于将CLIP模型引入到弱光增强和去模糊任务中,利用CLIP的语义理解能力来指导模型的优化。这种方法能够更准确地估计图像的退化程度,从而避免伪影并更好地恢复图像细节。此外,论文还设计了CLIP引导的跨融合模块和CLIP增强Transformer块,以有效地利用CLIP提供的退化信息。
关键设计:CLIP引导的跨融合模块可能涉及多层特征的融合,以获得更全面的退化信息。CLIP增强Transformer块可能采用注意力机制,以更好地关注重要的退化区域。损失函数的设计可能包括图像重建损失、感知损失和对抗损失等,以保证图像质量和视觉效果。具体的参数设置和网络结构细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片


📊 实验亮点
DAP-LED在弱光增强和去模糊任务上取得了state-of-the-art的性能。实验结果表明,DAP-LED不仅能够有效地增强图像亮度和去除运动模糊,还能显著提升下游任务(如深度估计、分割和检测)的性能。具体的性能数据和提升幅度需要在论文中查找(未知)。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、安防监控等领域,提升这些系统在夜间或低光照条件下的视觉感知能力。通过改善图像质量,可以提高目标检测、图像分割和深度估计等下游任务的准确性和可靠性,从而增强系统的整体性能和安全性。
📄 摘要(原文)
Autonomous vehicles and robots often struggle with reliable visual perception at night due to the low illumination and motion blur caused by the long exposure time of RGB cameras. Existing methods address this challenge by sequentially connecting the off-the-shelf pretrained low-light enhancement and deblurring models. Unfortunately, these methods often lead to noticeable artifacts (\eg, color distortions) in the over-exposed regions or make it hardly possible to learn the motion cues of the dark regions. In this paper, we interestingly find vision-language models, \eg, Contrastive Language-Image Pretraining (CLIP), can comprehensively perceive diverse degradation levels at night. In light of this, we propose a novel transformer-based joint learning framework, named DAP-LED, which can jointly achieve low-light enhancement and deblurring, benefiting downstream tasks, such as depth estimation, segmentation, and detection in the dark. The key insight is to leverage CLIP to adaptively learn the degradation levels from images at night. This subtly enables learning rich semantic information and visual representation for optimization of the joint tasks. To achieve this, we first introduce a CLIP-guided cross-fusion module to obtain multi-scale patch-wise degradation heatmaps from the image embeddings. Then, the heatmaps are fused via the designed CLIP-enhanced transformer blocks to retain useful degradation information for effective model optimization. Experimental results show that, compared to existing methods, our DAP-LED achieves state-of-the-art performance in the dark. Meanwhile, the enhanced results are demonstrated to be effective for three downstream tasks. For demo and more results, please check the project page: \url{https://vlislab22.github.io/dap-led/}.