HMD^2: Environment-aware Motion Generation from Single Egocentric Head-Mounted Device
作者: Vladimir Guzov, Yifeng Jiang, Fangzhou Hong, Gerard Pons-Moll, Richard Newcombe, C. Karen Liu, Yuting Ye, Lingni Ma
分类: cs.CV
发布日期: 2024-09-20 (更新: 2025-03-02)
备注: International Conference on 3D Vision 2025 (3DV 2025)
💡 一句话要点
HMD^2:利用单目头戴设备进行环境感知全身动作生成
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱四:生成式动作 (Generative Motion) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 全身运动生成 头戴设备 运动扩散模型 视觉SLAM 多模态融合
📋 核心要点
- 现有方法难以仅通过单目头戴设备准确生成全身运动,存在信息不足和运动模糊的问题。
- HMD^2系统融合运动重建与生成,利用相机流提取特征,并采用扩散模型保证时间连贯性。
- 实验表明,该系统能有效生成复杂环境下的全身运动,并实现低延迟的在线运动推理。
📝 摘要(中文)
本文研究了如何使用单个头戴设备(HMD),该设备配备了外向彩色相机并具备视觉SLAM能力,来生成逼真的全身人体运动。为了解决这种设置下的模糊性,我们提出了HMD^2,这是一种平衡运动重建和生成的新系统。从重建的角度来看,它旨在最大限度地利用相机流来生成分析和学习的特征,包括头部运动、SLAM点云和图像嵌入。在生成方面,HMD^2采用了一种具有Transformer主干的多模态条件运动扩散模型,以保持生成运动的时间连贯性,并利用自回归修复来促进在线运动推理,且延迟最小(0.17秒)。我们表明,我们的系统提供了一种有效且稳健的解决方案,可以扩展到复杂室内和室外环境中超过200小时的各种运动数据集。
🔬 方法详解
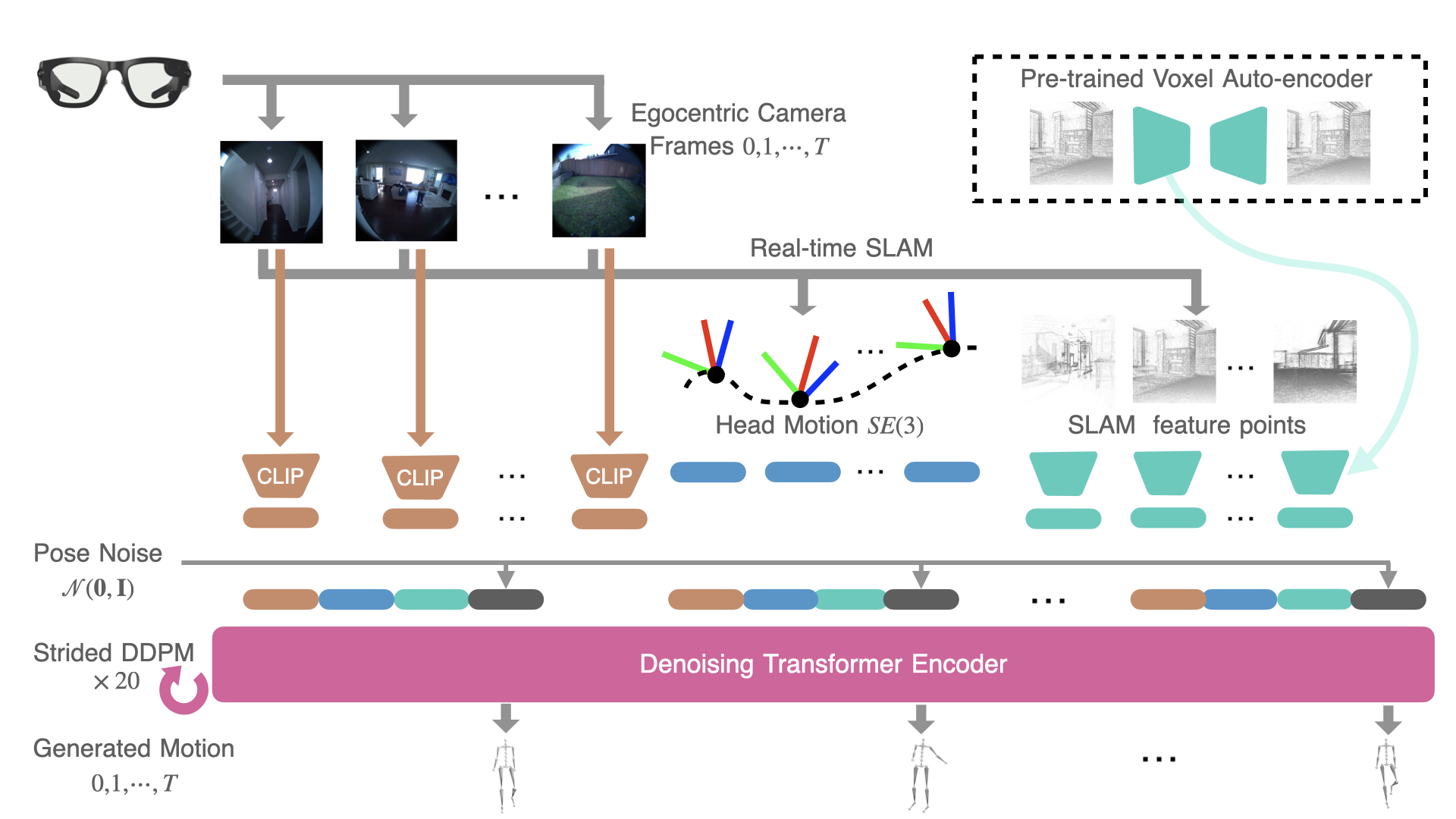
问题定义:论文旨在解决仅使用单个配备外向彩色相机的头戴设备(HMD)生成逼真全身人体运动的问题。现有方法在这种单目视觉设置下,由于缺乏足够的深度信息和视角限制,难以准确捕捉和重建全身运动,导致生成结果模糊且不自然。
核心思路:HMD^2的核心思路是平衡运动重建和生成。一方面,系统尽可能从相机流中提取有用的特征,包括头部运动、SLAM点云和图像嵌入,以提供尽可能多的环境和运动信息。另一方面,利用多模态条件运动扩散模型,从这些特征中生成全身运动,并保证生成运动的时间连贯性。
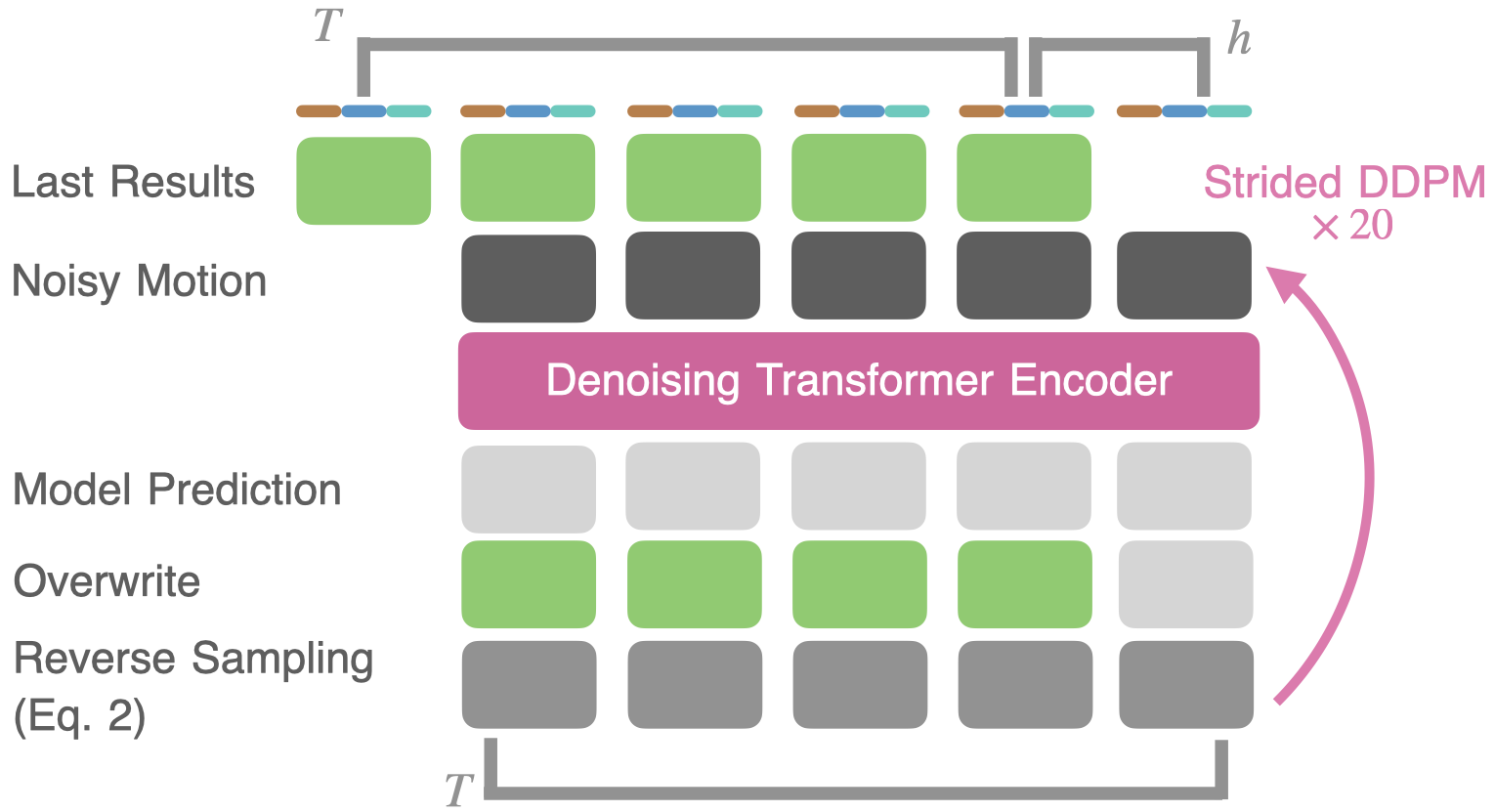
技术框架:HMD^2系统包含以下主要模块:1) 特征提取模块:从相机流中提取头部运动、SLAM点云和图像嵌入等特征。2) 运动生成模块:使用多模态条件运动扩散模型,以提取的特征为条件,生成全身运动。该模块采用Transformer作为主干网络,以捕捉运动的时间依赖性。3) 自回归修复模块:用于在线运动推理,通过自回归的方式逐步生成运动序列,并利用修复技术填充缺失或不准确的部分,从而实现低延迟的运动生成。
关键创新:HMD^2的关键创新在于其平衡重建和生成的策略,以及多模态条件运动扩散模型的设计。与仅依赖重建或生成的传统方法不同,HMD^2充分利用了相机流中的信息,并结合了扩散模型的生成能力,从而实现了更准确、更自然的全身运动生成。此外,自回归修复模块的设计也显著降低了在线运动推理的延迟。
关键设计:运动扩散模型使用Transformer作为主干网络,以捕捉运动的时间依赖性。损失函数包括重建损失和对抗损失,以保证生成运动的准确性和真实性。自回归修复模块采用滑动窗口的方式,逐步生成运动序列,并利用卷积神经网络填充缺失或不准确的部分。具体参数设置未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,HMD^2系统能够有效生成复杂室内和室外环境下的全身运动。该系统在在线运动推理中实现了0.17秒的低延迟。通过与现有方法的对比,HMD^2在运动质量和时间连贯性方面均取得了显著提升。该系统在超过200小时的运动数据集上进行了验证,证明了其有效性和鲁棒性。
🎯 应用场景
该研究成果可应用于虚拟现实(VR)、增强现实(AR)、游戏、动画制作、康复训练等领域。通过头戴设备捕捉用户头部运动和环境信息,即可生成逼真的全身运动,提升用户在虚拟环境中的沉浸感和交互体验。此外,该技术还可用于远程协作、运动分析等场景。
📄 摘要(原文)
This paper investigates the generation of realistic full-body human motion using a single head-mounted device with an outward-facing color camera and the ability to perform visual SLAM. To address the ambiguity of this setup, we present HMD^2, a novel system that balances motion reconstruction and generation. From a reconstruction standpoint, it aims to maximally utilize the camera streams to produce both analytical and learned features, including head motion, SLAM point cloud, and image embeddings. On the generative front, HMD^2 employs a multi-modal conditional motion diffusion model with a Transformer backbone to maintain temporal coherence of generated motions, and utilizes autoregressive inpainting to facilitate online motion inference with minimal latency (0.17 seconds). We show that our system provides an effective and robust solution that scales to a diverse dataset of over 200 hours of motion in complex indoor and outdoor environments.