Instruction-guided Multi-Granularity Segmentation and Captioning with Large Multimodal Model
作者: Li Zhou, Xu Yuan, Zenghui Sun, Zikun Zhou, Jingsong Lan
分类: cs.CV
发布日期: 2024-09-20
备注: Code and dataset will be released at https://github.com/lizhou-cs/mglmm. 7 pages, 4 figures with Supplementary Material
💡 一句话要点
提出MGLMM,通过指令引导实现多粒度分割和描述,解决现有LMMs在细粒度理解和分割上的局限性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 指令引导 图像分割 图像描述 多粒度 大型多模态模型 视觉语言模型
📋 核心要点
- 现有大型多模态模型在细粒度理解和分割方面存在局限性,无法根据详细文本提示进行像素级的精准操作。
- MGLMM通过指令引导,实现从全景到细粒度的分割和描述粒度调整,从而提升模型对图像的理解能力。
- 论文构建了包含1万张图像和3万多个图像-问题对的多粒度分割和描述基准,并验证了MGLMM在多个任务上的优越性。
📝 摘要(中文)
大型多模态模型(LMMs)通过扩展大型语言模型取得了显著进展。最新的LMMs通过集成分割模型,展现了生成密集像素级分割的能力。然而,现有工作的文本响应和分割掩码仍停留在实例级别,即使提供详细的文本提示,也难以进行细粒度的理解和分割。为了克服这一限制,我们引入了一种多粒度大型多模态模型(MGLMM),它能够根据用户指令无缝地调整分割和描述(SegCap)的粒度,从全景SegCap到细粒度SegCap。我们将这种新任务命名为多粒度分割和描述(MGSC)。由于缺乏针对MGSC任务的模型训练和评估基准,我们使用定制的自动化标注流程建立了一个包含1万张图像和3万多个图像-问题对的基准,其中包含对齐的掩码和多粒度的描述。我们将发布我们的数据集以及自动化数据集标注流程的实现,以供进一步研究。此外,我们提出了一种新颖的统一SegCap数据格式,以统一异构分割数据集;它有效地促进了多任务训练期间将对象概念与视觉特征相关联的学习。大量的实验表明,我们的MGLMM擅长处理八个以上的下游任务,并在MGSC、GCG、图像描述、指代分割、多重和空分割以及推理分割任务中实现了最先进的性能。MGLMM的卓越性能和多功能性突显了其在推进多模态研究方面的潜在影响。
🔬 方法详解
问题定义:现有的大型多模态模型(LMMs)在图像分割和描述任务中,主要集中在实例级别,即识别和分割图像中的主要对象。然而,在需要更细粒度的理解和分割时,例如根据用户的具体指令分割图像中的特定区域或属性,现有模型的能力不足。痛点在于无法灵活地调整分割和描述的粒度,缺乏对图像细节的深入理解。
核心思路:论文的核心思路是构建一个能够根据用户指令动态调整分割和描述粒度的多粒度大型多模态模型(MGLMM)。通过引入指令引导机制,模型可以根据用户提供的文本提示,从全景分割到细粒度分割进行切换,从而实现对图像更精确和细致的理解。
技术框架:MGLMM的整体架构包含以下几个主要模块:1) 视觉编码器:用于提取图像的视觉特征。2) 语言编码器:用于编码用户提供的文本指令。3) 多模态融合模块:将视觉特征和语言特征进行融合,以实现跨模态的信息交互。4) 分割解码器:根据融合后的特征生成分割掩码。5) 描述生成器:根据融合后的特征生成图像的文本描述。整个流程是,输入图像和指令,经过编码、融合和解码,最终输出分割结果和描述。
关键创新:论文最重要的技术创新点在于提出了指令引导的多粒度分割和描述框架。与现有方法相比,MGLMM能够根据用户指令动态调整分割和描述的粒度,从而实现更灵活和精确的图像理解。此外,论文还提出了统一的SegCap数据格式,方便了多任务训练。
关键设计:在关键设计方面,论文可能采用了以下技术细节:1) 使用Transformer架构作为多模态融合模块,以实现更好的跨模态信息交互。2) 设计了特定的损失函数,以优化分割和描述的性能。3) 采用了数据增强技术,以提高模型的泛化能力。4) 针对多粒度分割和描述任务,设计了特定的网络结构和参数设置,以提高模型的性能。
🖼️ 关键图片
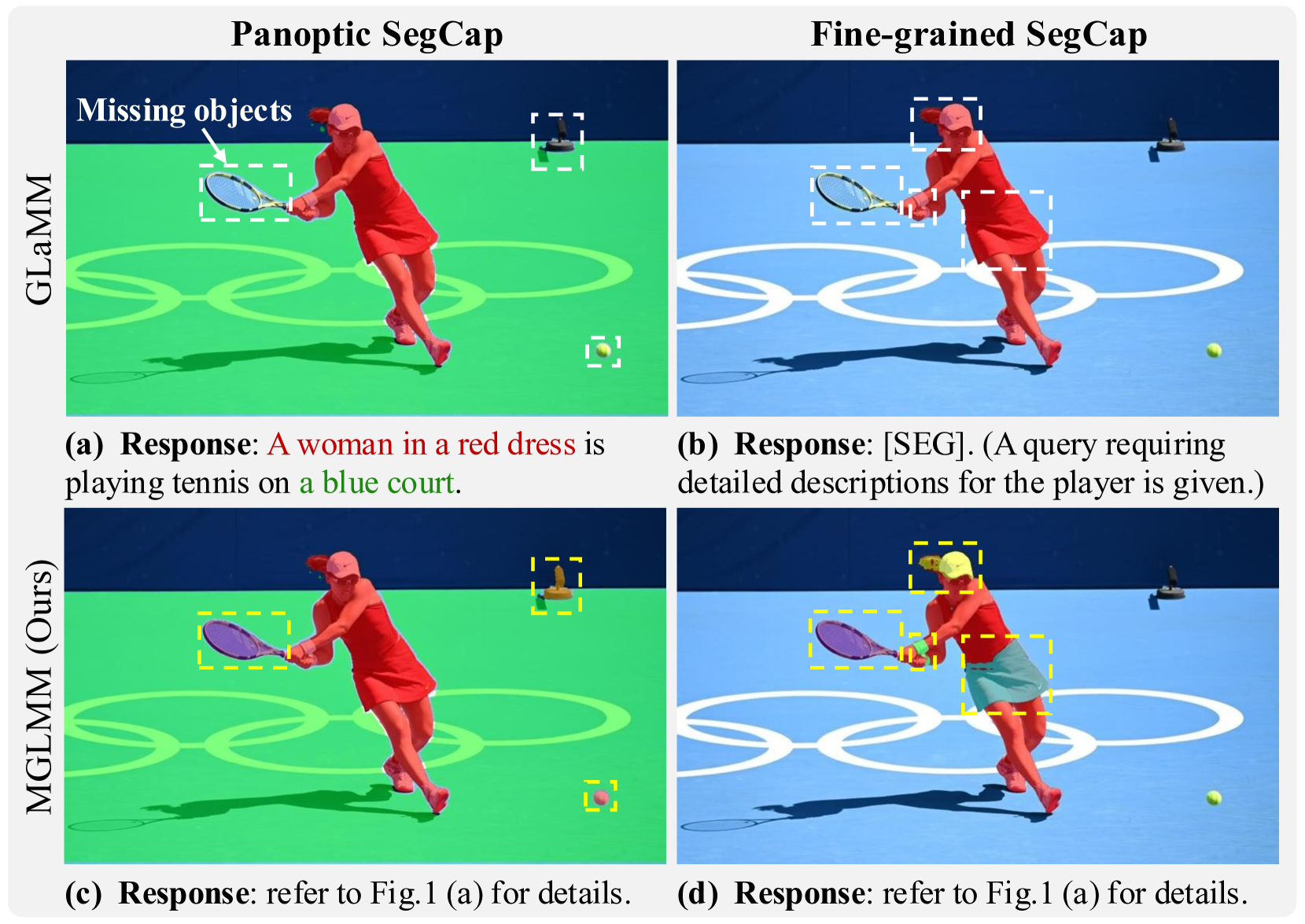


📊 实验亮点
实验结果表明,MGLMM在多粒度分割和描述(MGSC)任务上取得了state-of-the-art的性能。此外,MGLMM在GCG、图像描述、指代分割、多重和空分割以及推理分割等多个下游任务上也表现出色,证明了其强大的泛化能力。具体性能数据未知,但论文强调了其在多个任务上的领先地位。
🎯 应用场景
该研究成果可应用于智能图像编辑、自动驾驶、医学图像分析、机器人视觉等领域。例如,在智能图像编辑中,用户可以通过自然语言指令精确地分割和修改图像中的特定区域。在自动驾驶中,可以根据指令识别和分割道路上的各种物体,提高驾驶安全性。在医学图像分析中,可以辅助医生进行病灶检测和分割。
📄 摘要(原文)
Large Multimodal Models (LMMs) have achieved significant progress by extending large language models. Building on this progress, the latest developments in LMMs demonstrate the ability to generate dense pixel-wise segmentation through the integration of segmentation models.Despite the innovations, the textual responses and segmentation masks of existing works remain at the instance level, showing limited ability to perform fine-grained understanding and segmentation even provided with detailed textual cues.To overcome this limitation, we introduce a Multi-Granularity Large Multimodal Model (MGLMM), which is capable of seamlessly adjusting the granularity of Segmentation and Captioning (SegCap) following user instructions, from panoptic SegCap to fine-grained SegCap. We name such a new task Multi-Granularity Segmentation and Captioning (MGSC). Observing the lack of a benchmark for model training and evaluation over the MGSC task, we establish a benchmark with aligned masks and captions in multi-granularity using our customized automated annotation pipeline. This benchmark comprises 10K images and more than 30K image-question pairs. We will release our dataset along with the implementation of our automated dataset annotation pipeline for further research.Besides, we propose a novel unified SegCap data format to unify heterogeneous segmentation datasets; it effectively facilitates learning to associate object concepts with visual features during multi-task training. Extensive experiments demonstrate that our MGLMM excels at tackling more than eight downstream tasks and achieves state-of-the-art performance in MGSC, GCG, image captioning, referring segmentation, multiple and empty segmentation, and reasoning segmentation tasks. The great performance and versatility of MGLMM underscore its potential impact on advancing multimodal research.